當 healthchecks.io 的流量超過每秒一次通路之後,我就意識到不能随意在部署代碼後重新開機服務了。作為一個監控服務,即使丢掉幾個 http 請求也是不應該的。而且,如果伺服器變得更加繁忙的話,這個問題隻會更加嚴重。
先簡單介紹一下我們所做的工作,這是一個相對簡單的 django 實作的 app,由 gunicorn 來運作,前端是 nginx。資料儲存在 postgresql 資料庫裡。gunicorn和另一個額外的背景程序由 supervisor 負責管理。整個服務在單個$20級别的digitalocean執行個體上運作。
此外,我的技術選型的指導方針是整個架構盡可能的簡單,能夠使用盡可能長的時間。需要添加的東西,例如負載均衡、資料庫容災、k-v存儲、消息隊列等等,都要是必須的。另一方面,還需要考慮更多的事情,包括監控、備份等等。同時,對于剛接觸這個項目的人來說,需要花更多時間來了解整個系統的“輸入和輸出”,并且從頭開始搭建系統。既需要保持簡單、實用,還要保證性能和功能符合預期,這是個不錯的挑戰。
目前的部署方式是使用 fabric 腳本,以及用于 supervisor 和 nginx 的配置模闆。在我的工作機上運作“fab deploy”,fabric 本就會在遠端機上完成下面的事情:
fabric 腳本的相關部分參考下面的代碼,其中的 virtualenv 上下文管理部分源自優秀的 fabtools 庫。
現在,如何消除掉部署的最後一步停止服務的時間呢?我們來加一些前提條件:沒有負載均衡(目前)。所有的功能都需要集中在一台機器,而且不能有非 200 的響應碼。不過我們可以有一些小小的讓步:可以考慮一個稍微簡單(一般)的情形,不需要做資料庫合并,或者資料庫合并是向後相容的,應用的老版本在資料庫合并之後也能工作。
經過觀察,我發現應用的某些部分的可用性比其他部分的更重要。特别是被監控的用戶端系統需要通路的 api,其重要程度要高于使用者需要通路的前端頁面。雖然向使用者顯示錯誤頁面肯定是很糟糕的,但是不丢掉用戶端的請求更加重要。丢失的請求可能會導緻後續發送不該發送的報警,這顯然更加糟糕。
我考慮過使用 amazon api gateway 來處理用戶端的 ping 請求,也實作了原型。這需要把 ping 消息放到 amazon sqs 隊列裡,django 在空閑的時候去消費。這是相對簡單的增強可用性和擴充性的方式,不過代價比較大,也帶來新的外部依賴。将來需要再考慮一下有沒有更好的辦法。
另一種方式:把監聽用戶端的 ping 請求這個功能與 django 應用的其他部分分離開。ping 的監聽邏輯非常簡單,最終隻涉及到兩個 sql 操作:一個更新操作和一個插入操作。重寫這部分代碼應該比較簡單,也許可以使用 python的microframeworks,或者也可以不用 python 去實作,甚至還可以在 nginx 裡去實作(使用 ngx_postgres 子產品)。有意思的是,這裡有一段 nginx 的配置,做的就是類似的事情(忽略其中可笑的正規表達式):
簡單的說明一下這段配置:當用戶端請求并且 url 滿足一定規則的時候,服務端會執行 postgresql 查詢,傳回 http 的 200 或者4 00。這樣做性能上也占優,因為請求沒有走到 gunicorn、django 和 psycopg2。隻要資料庫可用,nginx 就可以處理 ping 請求,即使是 django 由于某種原因挂掉了。
不過,這種方式用了一點小伎倆,而且還引入了一些細節,開發者和系統管理者需要了解這些細節。例如,當資料庫的 schema 更改時,前面提到的 sql 查詢語句也需要更新并測試。另外,ngx_postgres擴充也不是簡單的通過“apt-get install”就能安裝成功的。
讓我們再想一下,也許通過仔細規劃程序的重加載,就能實作零當機時間的目标。
我的腳本裡之前使用的是“/etc/init.d/nginx restart”,這是因為我不知道更好的辦法。不過現在我知道可以改成 “/etc/init.d/nginx reload”,這樣會更優雅一些:
類似的,我的腳本使用“supervisorctl reload”來停止服務、重新加載配置、然後再啟動所有的服務。實際上,應該使用“supervisorctl update”來在配置有更新的時候啟動、停止和重新開機服務。
現在,“fab deploy”的工作流程如下:
下面是 fabric 腳本的改進部分,與 supervisor 任務處理相關:
通過這種方式,nginx 可以一直提供服務,總可以與線上的 gunicorn 程序互動。為了驗證這點,我寫了一個腳本無限循環的請求特定的 url。當遇到非 200 的響應結果時,會列印出相應的錯誤資訊。用這個腳本對測試虛拟機進行壓測,期間部署了多次,沒有發現有請求被丢掉。成功!
代碼部署時保證零當機有很多種方式,每一種都有其優缺點。例如,把關鍵部分從一個大的系統裡區分出來,這是一個合理的政策。這樣每個部分就可以獨立進行更新。之後每個部分也可以獨立的進行擴充。這種方式的不足之處是需要維護更多的代碼和配置。
最終的結果是:
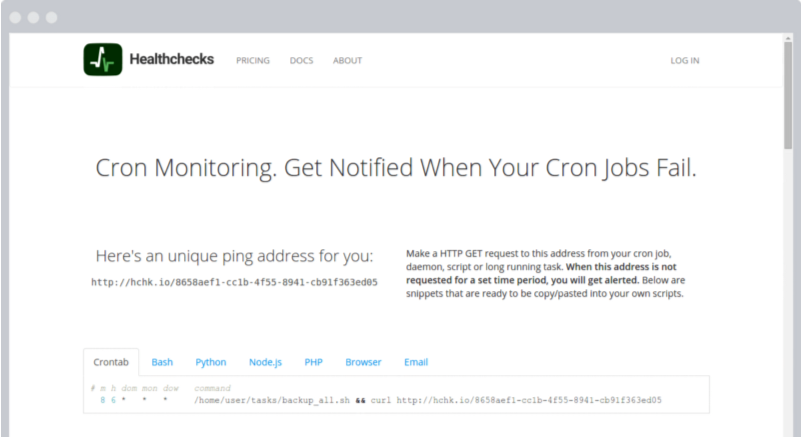
強烈推薦:healthchecks.io,它是一個免費的開源的基于 cron 的監控服務。在 cron 裡配置好監控隻需要幾分鐘時間,卻能讓你晚上睡得更好!
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)