druid 是一個開源的,分布式的,列存儲的,适用于實時資料分析的存儲系統,能夠快速聚合、靈活過濾、毫秒級查詢、和低延遲資料導入。
druid叢集包含不同類型的節點,而每種節點都被設計來做好某組事情。這樣的設計可以隔離關注并簡化整個系統的複雜度。
不同節點的運轉幾乎都是獨立的并且和其他的節點有着最小化的互動,是以叢集内的通信故障對于資料可用性的影響非常小。
druid叢集的構成和資料流向如圖1所示:
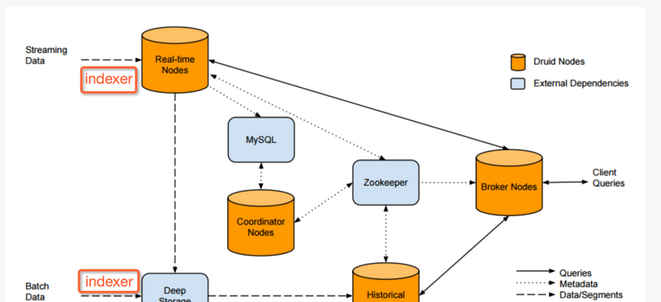
(圖1)
druid 包含3個外部依賴 :mysql、deep storage、zookeeper
實時節點封裝了導入和查詢事件資料的功能,經由這些節點導入的事件資料可以立刻被查詢。實時節點隻關心一小段時間内的事件資料,并定期把這段時間内收集的這批資料導入到深存儲區裡。實時節點通過zookeeper來宣布它們的線上狀态和它們提供的資料。

如圖2,實時節點緩存事件資料到記憶體中的索引上,然後有規律的持久化到磁盤上。在轉移之前,持久化的索引會周期性地合并在一起。查詢會同時命中記憶體中的和已持久化的索引。所有的實時節點都會周期性的啟動背景的計劃任務搜尋本地的持久化索引,背景計劃任務将這些持久化的索引合并到一起并生成一塊不可變的資料,這些資料塊包含了一段時間内的所有已經由實時節點導入的事件資料,稱這些資料塊為”segment”。在傳送階段,實時節點将這些segment上傳到一個永久持久化的備份存儲中,通常是一個分布式檔案系統,例如s3或者hdfs,稱之為”deep storage”(深存儲區)。
曆史節點遵循shared-nothing的架構,是以節點間沒有單點問題。節點間是互相獨立的并且提供的服務也是簡單的,它們隻需要知道如何加載、删除和處理segment。類似于實時節點,曆史節點在zookeeper中通告它們的線上狀态和為哪些資料提供服務。加載和删除segment的指令會通過zookeeper來進行釋出,指令會包含segment儲存在deep storage的什麼地方和怎麼解壓、處理這些segment的相關資訊。
如圖3,在曆史節點從深存儲區下載下傳某一segment之前,它會先檢查本地緩存資訊中看segment是否已經存在于節點中,如果segment還不存在緩存中,曆史節點會從深存儲區下載下傳segment到本地。這階段處理完成,這個segment就會在zookeeper中進行通告。此時,這個segment就可以被查詢了,查詢之前需要将segment加載到記憶體中。
協調節點主要負責segment的管理和在曆史節點上的分布。協調節點告訴曆史節點加載新資料、解除安裝過期資料、複制資料、和為了負載均衡移動資料。druid為了維持穩定的視圖,使用一個多版本的并發控制交換協定來管理不可變的segment。如果任何不可變的segment包含的資料已經被新的segment完全淘汰了,則過期的segment會從叢集中解除安裝掉。協調節點會經曆一個leader選舉的過程,來決定由一個獨立的節點來執行協調功能,其餘的協調節點則作為備援備份節點。
broker節點是曆史節點和實時節點的查詢路由。broker節點知道釋出于zookeeper中的segment的資訊,broker節點就可以将到來的查詢請求路由到正确的曆史節點或者是實時節點,broker節點也會将曆史節點和實時節點的局部結果進行合并,然後傳回最終的合并後的結果給調用者。broker節點包含一個支援lru失效政策的緩存。
如圖4,每次broker節點接收到查詢請求時,都會先将查詢映射到一組segment中去。這一組确定的segment的結果可能已經存在于緩存中,而不需要重新計算。對于那些不存在于緩存的結果,broker節點會将查詢轉發到正确的曆史節點和實時節點中去,一旦曆史節點傳回結果,broker節點會将這些結果緩存起來以供以後使用,這個過程如圖6所示。實時資料永遠不會被緩存,是以查詢實時節點的資料的查詢請求總是會被轉發到實時節點上去。實時資料是不斷變化的,是以緩存實時資料是不可靠的。
索引服務是運作索引任務相關的高可用性,分布式的服務。索引服務建立(有時破壞)druid的segment。索引服務有一個類似主/從的架構。
索引服務是由三個主要部分組成:可以運作單個任務的peon元件,用于管理peon的中層管理元件,以及管理任務配置設定到中層管理元件的overlord元件。overlord元件和中層管理元件可以在同一節點上或跨多個節點上運作,而中層管理元件和peon元件總是相同的節點上運作。
druid 使用zookeeper(zk)管理目前叢集狀态,在zk上發生的操作有:
1.協調節點的leader選舉
2.曆史和實時節點釋出segment協定
3.協調節點和曆史節點之間的segment load/drop協定
4.overlord的leader選舉
5.索引服務任務管理
druid vs impala/shark
druid和impala、shark 的比較基本上可以歸結為需要設計什麼樣的系統
druid被設計用于:
一直線上的服務
擷取實時資料
處理slice-n-dice式的即時查詢
elasticsearch(es) 是基于apache lucene的搜尋伺服器。它提供了全文搜尋的模式,并提供了通路原始事件級資料。 elasticsearch還提供了分析和彙總支援。根據研究,es在資料擷取和聚集用的資源比在druid高。
druid側重于olap工作流程。druid是高性能(快速聚集和擷取)以較低的成本進行了優化,并支援廣泛的分析操作。druid提供了結構化的事件資料的一些基本的搜尋支援。
spark是圍繞彈性分布式資料集( rdd )的概念,建立了一個叢集計算架構,可以被看作是一個背景分析平台。 rdd啟用資料複用保持中間結果存在記憶體中,給spark提供快速計算的疊代算法。這對于某些工作流程,如機器學習,相同的操作可應用一遍又一遍,直到有結果後收斂尤其有益。spark提供分析師與不同算法各種各樣運作查詢和分析大量資料的能力。
druid重點是資料擷取和提供查詢資料的服務,如果建立一個web界面,使用者可以随意檢視資料。
論文: druid a real-time analytical data store