前言: 吳思先生在《潛規則》(中國曆史中的真實遊戲)一書中講述了很多生動、有趣的官場故事,透過曆史表象,揭示出隐藏在正式規則之下、實際上支配着社會運作的不成文的規矩, 非常值得閱讀。
這篇文章準确來講并不是計算機/軟體開發的潛規則, 實際上是那些你可能在使用,卻沒有注意到的一些原理和規律,這些東西很重要,掌握了能夠指導你以後的開發和設計。
和碼農翻身公衆号之前的文章不同, 這是一篇沒有故事,讀起來不那麼好玩的超級幹貨, 我建議你靜下心來,閱讀一遍, 仔細的思考一下, 絕對物超所值。
上帝的規矩:局部性原理
這個原理講的是在一段時間裡, 整個程式的執行僅限于程式的某一個部分, 相應的, 程式通路的存儲空間也局限于某一個記憶體區域, 具體分為:
(1) 時間局部性:是指如果程式中的某條指令一旦執行,則不久之後該指令可能再次被執行; 如果某資料被通路,則不久之後該資料可能再次被通路。
(2) 空間局部性: 是指一旦程式通路了某個存儲單元,則不久之後。其附近的存儲單元也将被通路。
為什麼是這樣? 我也不知道, 可能是計算機界的上帝定下的規矩。
但是這個原理的用處可就大了, 例如java 虛拟機, 本來是解釋執行.class 檔案,性能不怎麼樣, 但是利用局部性原理, 就可以找到那些常用的, 所謂的熱點(hotspot)代碼, 然後把他們編譯成本地原生代碼(native code), 這樣執行效率就和c/c++差不多了。
當然這個原理更大的用處就是下面要提到的緩存。
坐飛機的怎麼和坐驢車的打交道: 緩存
為什麼需要緩存(cache)?
本質的原因是速度的不比對。
cpu比記憶體快100多倍, 比硬碟快1000多萬倍。
如果cpu每次做事的時候, 都等着記憶體和硬碟, 那整個計算機的速度估計要慢的要死了。
是以根據局部性原理, 作業系統會把經常需要用的資料從硬碟取到記憶體, cpu 會把經常用的資料從記憶體取到自己的緩存中。
(參見文章《cpu阿甘》)
通過這種辦法等待的問題能帶到極大的緩解。
在web 開發中,緩存更是非常常見的, 由于資料庫(硬碟)太慢, 大部分web系統都會把最常用的業務資料放到記憶體中緩存起來。
抛棄細節: 抽象
抽象是計算機科學中最為重要的概念之一。
當我們遇到複雜問題的時候, 抽象是非常重要的武器。
《深入了解計算機系統》一書中提到:
“指令集是對cpu的抽象, 檔案是對輸入/輸出裝置的抽象, 虛拟存儲器是對程式存儲的抽象, 程序是對一個正在運作的程式的抽象, 而虛拟機是對整個計算機(包括作業系統、處理器和程式)的抽象。”— 總結的非常精辟
cpu內建電路硬體無比複雜, 但是我們寫程式肯定不用接觸這些硬體細節, 那樣就累死了, 我們隻要遵循cpu的指令集, 程式就可以正确的運作, 而不用關心指令在硬體層次到底是怎麼運作的。
硬碟也是這樣, 有磁道,柱面,扇區, 我們寫應用層程式也不用和這些煩人的細節打交道, 在作業系統和裝置驅動的配合下, 我們隻需要面對一個個“檔案”,打開,讀取,關閉就行了。 作業系統會把邏輯的檔案翻譯成實體磁盤上的位元組。
再比如為了實作資料的共享,資料的一緻性和安全性,需要大量的,複雜的程式代碼來實作, 每個應用程式都實作一份肯定不是現實的。 是以計算機科學抽象出了一個叫資料庫的東西, 你隻需要安裝資料庫軟體, 使用sql和事務就能實作多使用者對資料的安全通路了。
參見文章《抽象, 程式員必備的能力》
我隻想和鄰居打交道: 分層
分層其實也是抽象的一種,它通過層次把複雜的,可能變化的東西隔離開來, 某一層隻能通路它的直接上層和下層, 不能跨層通路。
例如網絡協定分層:
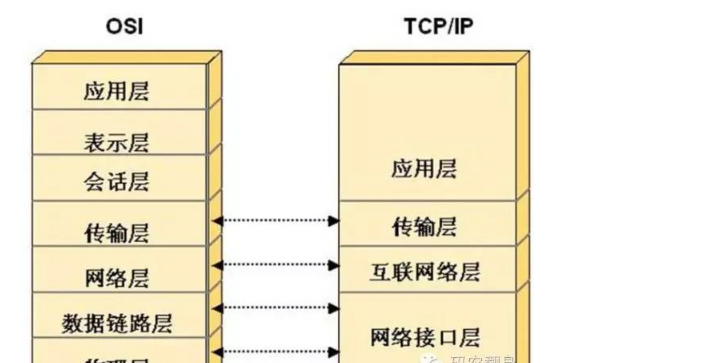
再比如web開發的分層:

分層的好處就是隔離變化, 在接口不變的情況下, 某一層的變化隻會局限于本層次内。
即使是接口變化, 也僅僅會影響調用方。
我怕等不及: 異步調用
當你的程式需要等待一個長時間的操作而被阻塞住時而無所事事的時候, 異步調用就派上用場了。
異步調用簡單就是說: 我等不及你了, 先去做别的事情, 你做完了告訴我一聲。
回到最早的那個cpu的例子, cpu速度太快, 當它想讀取硬碟檔案的時候,是不會等待慢1000多萬倍的硬碟的, 它會啟動一個dma , 不用通過cpu, 直接把資料從硬碟讀到記憶體, 讀完以後通過中斷的方式來通知cpu。
node.js 和 web伺服器nginx 也是這樣, 一個線程或若幹個線程處理所有的請求, 遇到耗時的操作, 絕不等待, 馬上去幹别的事情,等到耗時操作完成後,再來通知這些幹活的線程。
還有著名的ajax , 當浏覽器中的javascript發出一個http 請求的時候, 也不會等待從伺服器端傳回資料, 隻是設定一個回調函數, 伺服器響應資料回來的時候調用一下就行了。
大事化小, 小事花了 : 分而治之
分而治之的基本思想是将一個規模比較大的問題分解為多個規模較小的子問題,這些子問題互相獨立且與原問題性質相同。求出子問題的解,最後組合起來就可得到原問題的解。
由于子問題和原問題性質相同, 是以很多時候可以用遞歸。
歸并排序就是一個經典的例子, 資料結構與算法書上到處都是, 這裡就不在贅述了。
如果把分而治之泛化一下, 到軟體設計領域, 就可以認為是把一個大問題逐漸分解的過程:
思考: 你工作和學習中遇到過哪些“潛規則”? 不妨留言和大家分享下。