本文就架構,功能,産品線,概念等方面就elasticsearch和splunk做了一下全方位的對比,希望能夠大家在制定大資料搜尋方案的時候有所幫助。
簡介
elasticsearch (1)(2)是一個基于lucene的開源搜尋服務。它提供了一個分布式多使用者能力的全文搜尋引擎,基于restful web接口。elasticsearch是用java開發的,并作為apache許可條款下的開放源碼釋出,是目前流行的企業級搜尋引擎。設計用于雲計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用友善。
elk是elasticsearch,logstash,kibana的縮寫,分别提供搜尋,資料接入和可視化功能,構成了elastic的應用棧。
splunk 是大資料領域第一家在納斯達克上市公司,splunk提供一個機器資料的引擎。使用 splunk 可收集、索引和利用所有應用程式、伺服器和裝置(實體、虛拟和雲中)生成的快速移動型計算機資料 。從一個位置搜尋并分析所有實時和曆史資料。 使用 splunk 處理計算機資料,可讓您在幾分鐘内(而不是幾個小時或幾天)解決問題和調查安全事件。監視您的端對端基礎結構,避免服務性能降低或中斷。以較低成本滿足合規性要求。關聯并分析跨越多個系統的複雜事件。擷取新層次的營運可見性以及 it 和業務智能。
根據最新的資料庫引擎排名顯示,elastic,solr和splunk分别占據了資料庫搜尋引擎的前三位。
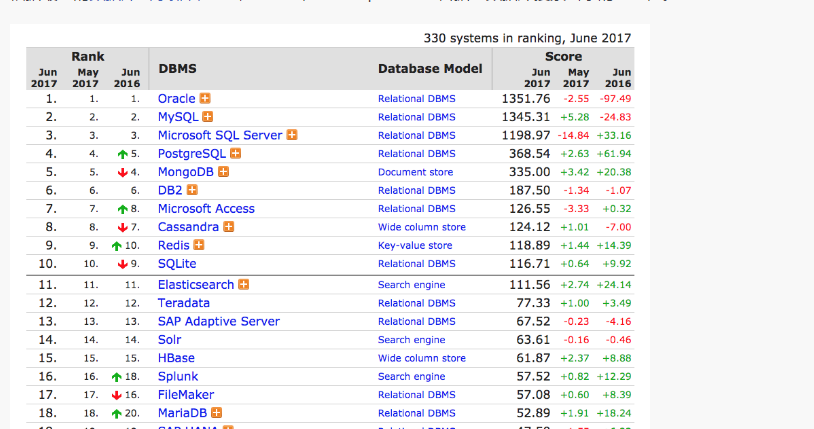
從趨勢上來看,elastic和splunk上升明顯,elastic更是表現出了非常強勁的勢頭。

基本概念
elastic
準實時(nrt)
elasticsearch是一個準實時性的搜尋平台,從資料索引到資料可以被搜尋存在一定的時延。
索引(index)
索引是有共同特性的文檔的集合,索引有自己的名字,可以對索引執行搜尋,更新,删除等操作。
類型(type)
每個索引可以包含一個或者多個類型,類型可以看作一個索引資料的邏輯分組,通常我們會把擁有相同字段的文檔定義為同一個類型。
文檔(document)
文檔是索引資訊的基本單元。elastic中文檔表現為json對象,文檔實體存貯在索引中,并需要被制定一個類型。因為表現為json, 很自然的,文檔是由一個個的字段(feilds)組成,每個字段是一個名值對(name value pair)
評分(score)
elastic是基于lucene建構的,是以搜尋的結果會有一個打分。來評價搜尋結果和查詢的相關性。
下圖是一個elastic的搜尋在kibana中看到的例子,原始的資料是一個簡單的日志檔案:
我們通過logstash索引到elasticsearch後,就可以搜尋了。
splunk
實時性
splunk同樣是準實時的,splunk的實時搜尋(realtime search)可以提供不間斷的搜尋結果的資料流。
事件(event)
對應于elastic的文檔,splunk的資料索引的基本單元是事件,每一個事件包含了一組值,字段,時間戳。splunk的事件可以是一段文本,一個配置檔案,一段日志或者json對象。
字段(fields)
字段是可以被搜尋的名值對,不同的事件可能擁有不同的字段。splunk支援索引時(index time)和搜尋時(search time)的字段抽取(fields extraction)
索引(indexes)
類似elastic的索引,所有的事件實體存儲在索引上,可以把索引了解為一個資料庫的表。
知識對象(knowledge object)
splunk的知識對象提供對資料進一步的解釋,分類,增強等功能,包括:字段(fields),字段抽取(fields extraction),事件類型(event type),事務(transaction),查找(lookups),标簽(tags),别名(aliases),資料模型(data model)等等。
下圖是一個splunk的搜尋在splunk用戶端看到的和前一個例子同樣的日志資料的搜尋結果。
從基本概念上來看,elasticsearch和splunk基本一緻。從例子中我們可以看到很多的共性,事件/文檔,時間戳,字段,搜尋,時間軸圖等等。其中有幾個主要的差别:
elastic不支援搜尋時的字段抽取,也就是說elastic的文檔中的所有字段在索引時已經固定了,而splunk支援在搜尋時,動态的抽取新的字段
elastic的搜尋是基于評分機制的,搜尋的結果有一個打分,而splunk沒有對搜尋結果評分
splunk的知識對象可以提供對資料更進階,更靈活的管理能力。
使用者接口
elasticsearch提供rest api來進行
叢集的管理,監控,健康檢查
索引的管理(curd)
搜尋的執行,包括排序,分頁,過濾,腳本,聚合等等進階的搜尋功能。
elasticsearch 本身并沒有提供任何ui的功能,搜尋可以用kibana,但是沒有管理ui還是讓人不爽的,好在開源的好處就是會有很多的開發者來建構缺失的功能:
elastichq
cerebro (推薦,界面幹淨,我喜歡)
dejavu
另一選擇就是安裝x-pack,這個是要收費的。
splunk作為企業軟體,管理及通路接口比較豐富,除了rest api 和指令行接口,splunk的ui非常友好易用,基本上所有的功能都能通過內建的ui來使用。同時提供以下接口
rest api
splunk ui
cli
功能
資料接入和擷取
elastic棧使用logstash和beats來進行資料的消化和擷取。
logstash用jruby實作,有點像一個資料管道,把輸入的資料進行處理,變形,過濾,然後輸出到其它地方。logstash 設計了自己的 dsl,包括有區域,注釋,資料類型(布爾值,字元串,數值,數組,哈希),條件判斷,字段引用等。
logstash的資料管道包含三個步驟,input,filter和output,每一步都可以通過plugin來擴充。另外input和output還支援配置codecs,完成對輸入輸出資料的編解碼工作。
logstash支援的常見的input包含file,syslog,beats等。filter中主要完成資料的變形處理,可以增删改字段,加标簽,等等。作為一個開源軟體,output不僅僅支援elasticsearch,還可以和許多其它軟體內建和目标,output可以是檔案,graphite,資料庫,nagios,s3,hadoop等。
在實際運用中,logstash 程序會被分為兩個不同的角色。運作在應用伺服器上的,盡量減輕運作壓力,隻做讀取和轉發,這個角色叫做 shipper;運作在獨立伺服器上,完成資料解析處理,負責寫入 elasticsearch 的角色,叫 indexer。
logstash 作為無狀态的軟體,配合消息隊列系統,可以很輕松的做到線性擴充
beats是 elastic 從 packetbeat 發展出來的資料收集器系統。beat 收集器可以直接寫入 elasticsearch,也可以傳輸給 logstash。其中抽象出來的 libbeat,提供了統一的資料發送方法,輸入配置解析,日志記錄架構等功能。
開源社群已經貢獻了許多的beats種類。
因為beats是使用golang編寫的,效率上很不錯。
splunk使用farwarder和add-ons來進行資料的消化和擷取。
splunk内置了對檔案,syslog,網絡端口等input的處理。當配置某個節點為forwarder的時候,splunk forwarder可以作為一個資料通道把資料發送到配置好的indexer去。這時候,它就類似logstash。這裡一個主要的差別就是對資料字段的抽取,elastic必須在logstash中通過filter配置或者擴充來做,也就是我們所說的index time抽取,抽取後不能改變。splunk支援index time的抽取,但是更多時候,splunk 在index time并不抽取而是等到搜尋是在決定如何抽取字段。
對于特定領域的資料擷取,splunk是用add-on的形式。splunk 的app市場上有超過600個不同種類的add-on。
使用者可以通過特定的add-on或者自己開發add-on來擷取特定的資料。
對于大資料的資料采集,大家也可以參考我的另一篇部落格。
資料管理和存儲
elasticsearch的資料存貯模型來自于lucene,基本原理是實用了倒排表。大家可以參考這篇文章。
splunk的核心同樣是倒排表,推薦大家看這篇去年splunk conf上的介紹,behind the magnifying glass: how search works
splunk的event存在許多buckets中,多個buckets構成邏輯分組的索引分布在indexer上。
每個bucket中都是倒排表的結構存儲資料,原始資料通過gzip壓縮。
搜尋時,利用bloom filter定位資料所在的bucket。
在對資料的存儲管理上,elastic 和splunk都是利用了倒排表。splunk對資料進行壓縮,是以存儲空間的占用要少很多,尤其考慮到大部分資料是文本,壓縮比很高的,當然這會損失一部分性能用于資料的解壓。
資料分析和處理
對資料的處理分析,elasticsearch主要使用 search api來實作。而splunk則提供了非常強大的spl,相比起es的search api,splunk的spl要好用很多,可以說spl就是非結構化資料的sql。無論是利用spl來開發分析應用,還是直接在splunk ui上用spl來處理資料,spl都非常易用。開源社群也在試圖為elastic增加類似spl的dsl來改善資料處理的易用性。例如: