本節書摘來自華章出版社《大資料內建(1)》一書中的第1章,第1.2節,作者 [美] 董欣(xin luna dong)戴夫士·斯裡瓦斯塔瓦(divesh srivastava),更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視
為了更好地了解大資料內建帶來的各種挑戰,我們給出5個最近的案例研究,實驗性地檢查大資料內建中的web資料源的各種特征,以及對這些特征自然分類的次元。
“當你能度量你所說的,并能将它表示成數字,那麼你就認識它一些了。”
——lord kelvin
大資料內建在多個次元上不同于傳統資料內建,類似于大資料不同于傳統資料庫的次元。
1.海量性(volume)
在大資料時代,不僅資料源包含大量的資料,而且資料源的數目也增長到千萬級;即使對于單個領域,資料源的數目也增長到成萬到十萬甚至百萬的級别。
很多情境下,單一的資料源可能包含大規模的資料,如社交媒體、電信網絡以及金融等。
單個領域中包含大量資料源的情境,可以考慮我們給出的航班的例子。假設我們想把它擴充到世界上所有航空公司和機場,進而可以支援靈活的國際旅行的航行計劃。由于全世界有成百上千個航空公司和4萬多個機場1,需要被內建的資料源數目很容易就上萬乃至十萬了。
更一般地,我們将在1.2.2節、1.2.3節和1.2.5節中讨論的案例研究中量化包含結構化資料的web資料源的數目,結果顯示這些數目大大超過了傳統資料內建中所考慮的資料源的數目。
2.高速性(velocity)
資料被采集和不斷被可用化的速度直接導緻大多數資料源都是動态的,而且資料源的數目也是飛速增長的。
動态資料源的情境可以考慮我們給出的航班的例子,其中上萬個資料源在提供随時間不斷變化的資訊。有些資訊的變化粒度是小時和分鐘,例如航班的估計出發和到達時間,以及航班目前的位置等。其他一些資訊變化得更慢些,以月、星期或天為變化粒度,例如航班原定的出發和到達時間的變化。為所有這些資料源上的動态變化的資料提供一個內建的視圖,是傳統資料內建方法無法做到的。
為了說明資料源數目的增長速度,我們在1.2.2節中讨論的案例研究顯示了幾年内深網資料源數目的爆炸性增長。毫無疑問,這些數目現在可能變得更大了。
3.多樣性(variety)
來自不同領域的資料源自然是多樣的,因為它們描述不同類型的實體和關系,經常要在支援複雜應用時需要被內建起來。另外,即使同一領域的資料源也常常是異構的,主要展現在模式級别如何結構化它們的資料和在執行個體級别如何描述同一現實世界中的實體,即使對非常類似的實體也會顯示很大的多樣性。最後,這些領域、源模式以及實體表達會随着時間演化,更增加了大資料內建中需要處理的多樣性和異構性。
再次考慮我們的航班例子。假設我們想把它擴充到其他交通類型(如飛機、輪船、火車、大巴、計程車等)來支援複雜的國際旅行計劃的制訂。需要被內建的資料源的多樣性将大大提高。除了世界上的航空公司和機場,又有世界上近千個活躍的海港和内陸港,世界範圍内1?000多個大巴公司,以及差不多相同數目的火車公司。234
我們在1.2.2節、1.2.4節和1.2.5節給出的案例研究量化了web資料源中實際存在的巨大的多樣性。
4.真實性(veracity)
不同資料源的品質千差萬别,在資料的覆寫面、精确度以及時效性等方面存在着巨大差異。
我們的航班例子顯示了實際中可能存在的一些具體的品質問題。随着資料源數目和多樣性的不斷增長,這些品質問題隻會更加惡化,因為實際中資料源之間會互相複制而且存在着不同類型的相關性。
我們在1.2.3節、1.2.4節和1.2.6節中給出的案例研究顯示了即使在同一領域的web資料源中可能存在的嚴重的資料覆寫和品質問題。這也說明為什麼“三個商業上司者中間就有一個不相信他們用來做決策的資訊”。5
深網包含大量的資料源,其資料被存儲在資料庫中并且隻能通過查詢web 表單來獲得。[he at al. 2007]和[madhavan et al. 2007]實驗性地研究了深網中資料源的海量性、高速性和領域級的多樣性等性質。
1.主要問題
這兩個研究集中在以下兩個與1.2.1節中給出的“v”次元相關的主要問題。
* 深網的規模有多大?
例如,web上有多少個資料庫的查詢界面?通過這樣的查詢界面可以存取多少個web資料庫?多少web資料源提供這樣的資料庫查詢界面?這些有關深網的數字是如何随時間變化的?
* web資料庫的領域分布是什麼?
例如,是否深網的資料源主要是關于電子商務的,如商品搜尋?還是web資料庫存在着相當程度的領域級的多樣性?這些領域級的多樣性和淺層網比較起來如何?
2.研究方法
由于沒有一個對深網資料源的較完全的索引,兩個研究都是用采樣的方法來量化這些問題的答案。
[he at el. 2007]使用一種ip采樣的方法搜集伺服器樣本,即随機采樣2004年的1百萬個ip位址,使用wgethttp用戶端下載下傳html頁面,然後人工判定和分析此樣本中的web資料庫,以此來推算22億個有效ip位址。這一研究使用下面的方法來區分深網資料源、web資料庫(一個深網資料源可以包含多個web資料庫)和查詢界面(一個web資料庫可能被多個查詢界面所存取)。
1)從每個web資料源的根頁面開始向下爬取三層,然後判定爬取到的頁面上的所有html查詢界面。
一個資料源上的多個查詢界面可能指向同一底層的資料庫。這可以通過下面的方法來判定:先人工随機選擇一個查詢界面上傳回的一組對象,然後看是否每個對象也可以通過另外一個查詢界面擷取。
[madhavan et al. 2007]從google 2006年的索引中随機采樣2?500萬個網頁,然後用規則驅動的方法判定這些頁面上的深網查詢界面,并最終将他們的估計推算至google索引中的10億多頁面上。沿用[he et al. 2007]中的術語,這一研究主要檢查了深網中查詢界面的數目,而不是不同深網資料庫的數目。他們使用的方法如下。
1)由于許多html 表單(form)可能出現在多個網頁上,他們為每個表單計算了一個簽名,具體把表單動作中的主機名和可視輸入項合在一起得到。這被用來得到不同html 表單的數目的下界。
2)從這一數字出發,他們删去了非查詢表單(如密碼輸入項)和網站搜尋框,并隻計算那些至少有一個文本輸入域且包含2~10個輸入項的表單。
3.主要結果
我們按照幾個“v”次元來歸類這些研究得到的主要結果。
(1)海量性、高速性
[he et al. 2007]在2004年估計深網大概含有307?000個資料源,450?000個web資料庫,以及1 258 000個不同查詢界面。這是從他們随機選擇的ip樣本中判定的總共126個深網資料源(包含190個web資料庫和406個查詢界面)推算得到的。由于判定的深網資料源的數目不大,使得他們能用人工判定查詢界面的方法來完成他們大部分的分析工作。
[madhavan et al. 2007]在2006年估計深網有超過1?000萬個不同的查詢界面。這是從他們随機采樣的網頁中判定的647 000個不同查詢界面中推算出的。判定這樣大量的查詢界面需要使用自動的方法來區分深網查詢界面和非查詢界面。madhavan等估計出的查詢界面的數目大于he等估計出的數目也部分反映了深網資料源的數目在這兩個研究點的時間段内快速增長的速度。
(2)多樣性
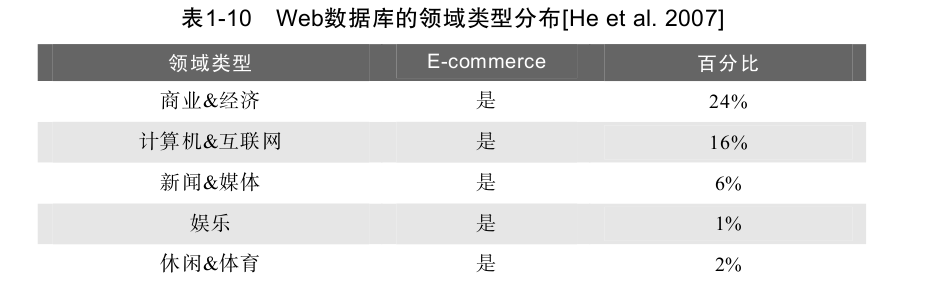
[he et al. 2007]的研究顯示深網資料庫具有很大的領域級多樣性,在他們樣本中被判定出來的190個web資料庫中,51%屬于非電子商務領域,如健康、社會文化、教育、藝術人文、科學等,隻有49%屬于電子商務領域。表1-10給出了he等人研究中判定的領域類别分布,表明了在大資料內建中資料的領域級多樣性。web資料庫的領域級多樣性與淺層網形成鮮明對比,之前的一個研究表明淺層網中83%的網站是電子商務類的。
[madhavan et al. 2007]的研究也肯定了深網資料源中的語義内容也很廣,分布在大部分類别上。

淺層網的文檔中包含了大量結構化的資料,可以用資訊抽取的技術得到。[dalvi et al. 2012]實驗性地研究了某些領域(如餐館、旅店)内的這些結構化資料(即實體和它們的屬性)的數量和覆寫特性。
這一研究集中在以下兩個與1.2.1節中給出的“v”次元相關的主要問題。
要為一個給定領域(甚至限定一組屬性)建構一個完全的資料庫需要多少資料源?
發現一個給定領域的資料源和實體有多容易?
例如,是否可以從幾個資料源或種子實體出發疊代地發現大部分(如99%)資料?主要資訊聚集網站在這一資料源發現過程中的作用有多關鍵?
回答這些問題的一種方法是在各種領域内實際進行web規模的資訊抽取,然後計算出需要的數值;但這是一個極具挑戰的任務,好的解決方法仍在研究中。相反,[dalvi et al. 2012]采用的方法是研究具有以下三個特性的領域。
1)有一個包含該領域内實體的較完全的結構化資料庫可以被通路。
2)實體可以由網頁上的一些關鍵屬性值所唯一辨別。
3)包含實體的關鍵屬性的(近乎)所有網頁可以被通路。
dalvi等給出了9個這樣的領域:圖書、餐館、汽車、銀行、圖書館、學校、旅店和借宿、零售和購物,以及家居和園藝。圖書可以被isbn所唯一辨別,而其他領域内的實體可以用電話号碼和/或首頁url來唯一辨別。對每個領域,他們找到yahoo!網頁緩存中每個頁面上實體的辨別屬性,将網頁按照主機名分組,每個組對應一個資料源,然後将每個資料源的所有網頁上發現的實體聚集在一起。
他們用一個實體和資料源之間的二分圖來為資料源和實體發現容易程度問題模組化。邊(e, s)表示實體e在資料源s中被發現。圖的一些諸如二分圖的連接配接度等性質有助于了解疊代資訊抽取算法相對于種子實體和初始資料源選擇的魯棒性。類似地,圖的直徑可以指出需要多少次疊代才可以收斂。這樣,他們不需要實際進行資訊抽取,隻要研究他們資料庫中已有的實體資訊分布即可。盡管這種方法有一定的局限性,它為這一主題的研究提供了一個很好的開始。
我們按照幾個“v”次元來歸類這一研究得到的主要結果。
海量性
第一,他們發現研究的所有領域具有上萬到上十萬的資料源(見圖1-2中所示的餐館領域中的電話号碼數量)。這些數目大大超出了傳統資料內建中考慮的資料源數目。
第三,他們使用k-coverage(資料庫中出現在至少k個資料源中的實體所占的比例)來調查資訊的備援度,以使得抽取出的資訊具有更高的置信度。例如,他們顯示要獲得90%餐館電話号碼的5-coverage需要5000個資料源(而10個資料源就足以獲得93%電話号碼的1-coverage),見圖1-2。
第四,他們(使用使用者生成的對餐館的評論)顯示從長尾資料源中抽取出的資訊具有很大的價值。具體地,盡管對評論資訊的需求和評論資訊的數量都在向尾部遞減,但是評論資訊的數量遞減得更快,說明長尾抽取是有價值的,盡管對其需求相對較低。
第五,如圖1-3所示,他們觀察到存在着大量的資料備援(平均每個實體出現在幾十個到幾百個資料源中),以及同一領域的資料很好地互聯在一起。這一資料備援性和良好的互聯性在大資料內建的發現資料源和實體過程中非常關鍵。具體地,對于幾乎所有的(領域,屬性)對而言,超過99%的實體存在于二分圖的最大連接配接子圖,說明即使随機選擇一小組實體作為種子也足以到達領域中的大部分實體。另外,一個小的直徑長度(6~8)意味着疊代算法會很快收斂。最後,他們顯示即使在去掉前10個資訊聚集型資料源,二分圖仍然保持良好的互聯性(連接配接超過90%的實體),表明這一互聯性不僅僅依賴于主要的聚集型資料源。
[he et al. 2007]和[madhavan et al. 2007]中的研究展示了深網資料的海量性、高速性,以及領域級多樣性,但沒有調查這些資料源中的資料品質的問題。為了彌補這一缺陷,[li et al. 2012]實驗性地研究了深網資料的真實性問題。
* 深網資料的品質如何?
例如,深網資料源之間是否存在大量的備援資料?一個領域的不同資料源中的資料是否一緻?某些領域的資料品質是否優于其他領域?
* 深網資料源的品質如何?
例如,資料源是否高度準确?正确的資料是否被大多數資料源提供?在資料源出現不一緻時,是否存在一個可以被信任的權威資料源而所有其他資料源均可以忽略?資料源是否和其他資料源共享或互相複制資料?
回答這些問題的一種方法是在每個領域實際地進行跨所有深網資料源的大資料內建;但這是一個極具挑戰的任務,還未被解決。相反,[li et al. 2012]采用的方法是研究具有以下特性的一些領域。
1)這些領域内的深網資料源被頻繁使用,而且被認為是幹淨的因為錯誤資料會對人們的生活産生負面影響。
2)這些領域内的實體在資料源之間被一些關鍵屬性一緻地唯一辨別,這使得易于跨深網資料源連結資訊。
3)集中研究一部分較流行的資料源足夠了解這些領域中使用者所體驗到的資料品質問題。
[li et al. 2012]的研究給出了兩個這樣的領域:股票和航班。股票用股票代号(如t表示at&t公司,goog表示google公司)可以被跨資料源一緻地唯一辨別;航班号(如ua 48)和出發/到達機場代碼(如ewr和sfo)一般可以被用來跨資料源地唯一辨別某天内的航班。他們用以下方法确定了每個領域内較流行的一組深網資料源:i)使用領域特定的詞彙搜尋通用搜尋引擎,然後在傳回的前200個結果中人工判斷深網資料源;ii)選出那些使用get方法(即查詢表單的資料被編碼在url中)而不是使用javascript的資料源。這樣他們在股票領域得到55個資料源(包括流行的金融資訊聚集網站如yahoo! finance、google finance和msn money,官方的股票交易資料源如nasdaq,以及一些金融新聞資料源如bloomberg和marketwatch),在航班領域得到38個資料源(包括3個航空公司資料源、8個樞紐機場資料源,以及27個第三方資料源如orbitz、travelocity等)。
在股票領域,他們從dow jones、nasdaq和russell 3000選擇了1000隻股票代号,在2011年7月的每個工作日用每隻股票代号分别查詢55個資料源。查詢在每天股票市場結束一小時後送出。從不同資料源抽取出的屬性被人工比對來判斷那些全局不同的屬性;其中16個常見屬性的值在股票市場結束後較穩定(如每日收盤價),再被進一步詳細分析。他們在5個流行金融資料源用多數表決的結果為200個股票代号生成了一組标準資料。
在航班領域,他們集中研究了從三大航空公司(聯合航空、大陸航空和美國航空)的樞紐機場出發和到達的1200個航班,在2011年12月的每一天,在其原定到達時間至少一小時之後查詢每個航班。從不同資料源抽取出的屬性被人工比對來判斷那些全局不同的屬性;其中6個常見屬性被進一步詳細分析。他們用相應的航空公司資料源提供的資料為100個航班生成一組标準資料。
類似于前面的案例研究,我們按照1.2.1節中的“v”次元來歸類這一研究得到的主要結果。
盡管這一研究的目标主要集中在資料的真實性,這一研究的結果同時顯示了深網資料源模式級的多樣性。
(1)多樣性
[li et al. 2012]在所調查的深網資料源中發現相當大的模式級的多樣性。例如,股票領域的55個資料源提供了不同數目的屬性,屬性個數最少的是3,最多的是71,總共有333個屬性。人工比對了不同資料源的屬性後,他們得到了153個全局不同的屬性,其中許多屬性用其他屬性計算得到(如52個星期的最高和最低價格)。提供這些屬性的資料源數目的分布是非常偏斜的,僅有13.7%的屬性(共21個)由三分之一以上的資料源所提供,而86%的屬性由少于25%的資料源提供。航班領域的模式多樣性較小,38個資料源共提供了43個屬性,經過人工比對後得到15個全局不同的屬性。
(2)真實性
雖然所研究的領域内的資料被認為應該是很幹淨的,但資料品質并不如所期望的那樣高。具體地,這些領域的資料展示了很強的不一緻性。例如,在股票領域,同一資料項的不同值(允許一定值容差後)的個數最少是1,最大是13,平均是3.7;另外,超過60%的資料項的不一緻值由不同資料源所提供。在航班領域,值的不一緻程度低很多,同一資料項的不同值(允許一定值容差後)的個數最少是1,最大是5,平均是1.45;另外,少于40%的資料項的不一緻值由不同資料源所提供。不同的原因造成觀察到的資料的不一緻性,包括語義歧義性、過期資料以及錯誤。圖1-4展示了兩個領域的資料項的不同值的數目的分布。li等人表明這些不一緻性不能用簡單的多數表決方法來解決,表決結果的精度常常低于使用單一資料源得到的最高精度。
另外,他們觀察到深網資料源的準确度變化很大。在股票領域,資料源的平均準确度為0.86,而且隻有35%的資料源的準确度超過0.9。盡管大多數權威資料源的準确度超過0.9,但是它們的覆寫率都低于0.9,意味着一個應用無法隻依賴于某個單一的權威資料源而忽略所有其他資料源。在航班領域,資料源的平均準确率更低,隻有0.8,29%的資料源的準确率低于0.7。這一領域中權威資料源的準确度超過0.9,但是它們的覆寫率都低于0.9。
最後,[li et al. 2012]觀察到每個領域中的深網資料源間存在着複制現象。一些情況下的複制被明确說明,但其他情況下的複制是通過觀察嵌入的界面和查詢重定向來檢測出的。有趣的是,被複制的原始資料源的準确度并不總是很高,在股票領域其變化範圍是0.75~0.92,在航班領域是0.53~0.93。
淺層網上的靜态html頁面上明顯地含有大量的無結構資料,也包含大量的結構資料,展現在html表格(table)中,如圖1-5所示的表格。[cafarella et al. 2008b]和[lautert et al. 2013]實驗性地研究了網上這些表格的數量和結構多樣性。
這一工作的研究動機是淺層網通常被視為一組超連結起來的非結構化文檔,因而忽略了web文檔中所包含的關系資料。例如,大多是維基百科(wikipedia)網頁含有高品質的關系資料,為幾乎每個主題提供有價值的資訊。通過識别這些爬取器可通路到的淺層網上的關系表,web搜尋引擎就可以為使用者的關鍵詞查詢傳回這類表格了。
這些研究集中在以下兩個與1.2.1節中給出的“v”次元相關的主要問題。
淺層網上具有多少高品質的關系表?如何将它們和html表格的其他使用(如表單布局)區分開來?
* 這些表格的異構程度如何?
例如,表格的大小,即行和列的數目,是如何分布的?多少這樣的表格具有比傳統的關系表更豐富的結構(如嵌套表、列聯表)?
[cafarella et al. 2008b]從google爬取的幾十億個英文網頁出發,使用一個html解析器獲得網頁上的所有table标簽。其中隻有一小部分發現的表格是高品質的關系表,他們使用以下方法将這些表格和那些非關系表的html标簽區分開來。
1)他們使用解析器将那些明顯的非關系表格去掉,包括極小表格(少于2行或2列),嵌在html 表單中的表格(用于可視化使用者輸入域的布局),以及月曆。
2)他們在剩下的表格中選取一部分樣本,然後人工标注來估計高品質關系表的比例。
3)他們基于各式各樣表級的特征訓練了一個分類器來區分關系表和html table标簽的其他用法,如頁面布局和屬性表(property sheet)等。接下來,他們用分類器的輸出結果收集有關分布的統計資料。
[lautert et al. 2013]觀察到web上即使高品質的表格也是異構的,有水準、垂直和矩陣的結構,一些單元格跨多個行或列,一些單元格中有多個值,等等。他們使用下面的方法量化web上表格的異構性。
1)他們從wikipedia、電子商務、新聞、大學等資料源出發爬取了一組網頁,然後抽取出網頁上所有的html表格,共通路了174?927個html頁面,抽取出342?795個不同的html表格。
2)他們使用包括頁面布局、html和詞彙方面的25個特征,開發了一個有監督的神經網絡分類器将表格分到不同類别。訓練資料集含有4000個web表格。
(1)海量性
首先,[cafarella et al. 2008b]從所爬取的頁面中抽取出大約141億個html表格。其中89.4%(或者125億)被去掉了,因為解析器判斷它們是明顯的非關系表(大部分是極小表格)。在剩下的表格中,用人工在一個樣本集上判斷的結果推斷有大約10.4%(或者1.1%的初始html表格)是高品質關系表。進而可以估計web上大約有15?400個高品質的關系表格。
其次,[cafarella et al. 2008b]使用諸如行數、列數、大部分為null值的行數、非字元串數值的列數、單元格中字元串長度的平均值和标準差等為特征,訓練了一個分類器來判别高品質關系表格,其查全率較高,為0.81,而查準率則較低,隻有0.41。使用分類器的結果,他們得到了高品質關系表的行數和列數的分布統計資料。93%以上的這些表具有2~9列;非常少的高品質表格具有非常多的屬性列。相反,高品質表的行數呈現較大的多樣性,如表1-11所示。
[lautert et al. 2013]确定在web上的高品質表格中存在着相當大的結構多樣性。隻有17.8%的高品質web表格類似于傳統關系資料庫中的表格(每個單元格含有單個值,不跨多行或多列)。web表格不同于rdbms中表的兩大主要原因是:i)74.9%的表格含有包含多個值(相同或不同資料類型)的單元格。ii)12.9%的表格含有跨多個行或列的單元格。
我們最後一個案例研究是關于使用web規模的資訊抽取技術獲得的領域無關的結構化資料,即被表示為<主語,謂詞,賓語>的知識三元組。在我們的航班例子裡,三元組和表示airline1航空公司的49号航班的出發和到達機場分别是ewr和sfo。[dong et al. 2014b]實驗性地研究了通過爬取大量網頁并從中抽取獲得的這樣的知識三元組的數量和真實性。
這一工作的起因是要完成自動建構大規模知識庫的任務,即通過使用多個抽取器從每個資料源為每個資料項抽取出(可能互相沖突的)值,然後解決抽取出的三元組中存在的歧義性,最後建構一個高品質的知識庫。
從web網頁上可以被抽取出的知識三元組的數目和分布特性是什麼?
例如,從網頁的dom樹結構中抽取出的三元組數目和使用自然語言處理技術從非結構文本中抽取出的三元組數目。
* 抽取出的三元組的品質以及抽取器的準确度如何?
[dong et al. 2014]爬取了超過10億個web頁面,使用以下方法從4類網頁内容中抽取知識三元組。
2)他們限定抽取的三元組中的主語和謂詞必須已經存在于已有的知識庫如freebase [bollacker et al. 2008]中。
3)抽取出的知識的品質用freebase知識庫作為标準來衡量。具體地,如果一個抽取出的三元組存在于freebase中,則為真;如果不在freebase中,但在,則抽取出的三元組被視為假;否則其不被包含在标準結果集中。
首先,[dong et al. 2014b]抽取出16億不同三元組,其中80%來自dom樹結構,19%來自文本文檔。不同類型的web頁面内容抽取出的三元組重疊部分很小,如圖1-6所示。
其次,這些抽取到的三元組與freebase中的4?300萬個主語和4?500個謂詞(3.37億個(主語,謂詞)對)有關。大部分分布(如每個主語的三元組數目)是高度偏斜的,有很長的長尾;例如,前5個實體每個具有100萬個以上的三元組,而56%的實體每個隻抽取出不超過10個三元組。
在抽取出的16億三元組中,40%(或65?000萬個)三元組具有标準結果,其中2億個被認為是真的。進而,抽取出的三元組的總體準确度僅約為30%。大部分的錯誤是抽取錯誤,但也有一小部分是由于資料源提供了錯誤資訊造成的。
此研究顯示不同抽取器的準确度存在巨大差異。