本節書摘來華章計算機《資料分析實戰:基于excel和spss系列工具的實踐》一書中的第1章 ,第1.1節,紀賀元 著, 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
在我做資料分析教育訓練和咨詢的時候,時不時會有學員或者客戶流露出這樣的情緒:
我們的企業其實是不需要資料分析的。
我們公司的業務情況,我很清楚,分析不分析都那樣,反正我都知道了。
公司的資料好簡單啊,就那麼幾列,有啥好分析的。
公司裡面的很多資料都是造假的,沒有分析的價值。
在以上問題中,除了資料品質,其他問題都與企業資料的可分析度有關。資料品質确實是資料分析很難解決的問題,如果企業員工出于種種原因總是在編造各種假資料,這應該屬于職業道德或者企業管理水準(企業應該通過嚴格嚴謹的管理流程使得員工無從造假)的範疇,這裡暫且不讨論。那麼,什麼是資料的可分析度呢?
這個問題實際上包含如下兩層意思:
1)這個企業的資料是比較複雜的,一眼是看不到結論的,需要使用一些工具、模型、方法進行分析。
2)關于資料的分析是有價值的,也就是說分析的過程和結論對于企業是有價值的,能夠對企業的生産經營等帶來促進和提高。
是以,在資料的可分析度方面,我們需要有一些判斷的次元,以幫助我們辨識資料是否值得分析,這裡所說的次元主要考慮企業資料量、資料複雜度、資料顆粒度這三個方面(如圖1-1所示)。
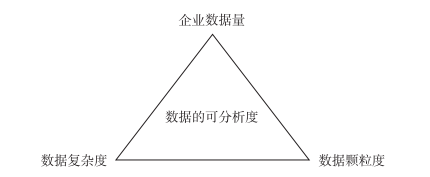
企業資料量是企業可分析度的第一要素,企業資料量的大小往往取決于兩個因素:
一是企業的行業屬性,二是企業的資訊化程度。衆所周知,網際網路行業往往也是産生大量資料的行業,“bat”不僅僅引領了各自行業的發展,同時也是資料行業發展的标杆。
一般情況下,企業的資料量跟企業的規模呈正相關關系,中等以上規模的企業資料量均比較大。但是也有例外,我曾經接觸過一家從事智能手機作業系統推送業務的公司,該公司規模很小,隻有40多人,但是由于合作方是國内諸多智能手機的生産企業,是以該企業的手機使用者數量有3000多萬,每天産生的業務數量高達幾gb。
如果說資料量相當于資料的行,那麼資料複雜度就相當于資料的列。某公司營銷部曾給我發來的資料樣例,總共的列數加在一起是12列。該公司要求分析客戶資料,但是涉及客戶資料的資料基本上就是客戶名稱、客戶行業(行業資料還是不全的)這兩列,客戶注冊資本、銷售收入、雇傭人數都沒有,怎麼分析?
做過資料分析的人肯定都知道“巧婦難為無米之炊”的苦楚!請想想,你提供的客戶資料就是寥寥數列,那要怎麼去分析?怎麼做文章?
到目前為止,并沒有什麼明确的名額來度量資料量與資料複雜度,我們很難說每天的資料超過3萬行就算資料量多,或者說資料超過30列就算資料複雜。特别是資料複雜度,這中間還有一個資料相關性的問題:以案例檔案1.1為例,雖然其中的資料是3列,但是用excel自帶的“資料分析”子產品中的“相關分析”進行分析(相關系數的函數,後面會詳細講解),我們發現第二列“銷售數量”和第三列“銷售額”之間的相關系數是1(完全相關),如圖1-2所示。

從資料分析的角度看,這裡實際上是兩列資料而不是3列,換句話說,第3列的銷售額資料屬于“衍生名額”,因為單價30是固定的,我們隻需要用銷售量這個資料就可以反映銷售的狀況。
是以通過資料的列數來衡量資料複雜度其實也未必準确,而是應該看剔除相關性之後的列數。
資料顆粒度指的是從不同的層次來看待資料。很難用語言來形容資料顆粒度的重要性,還是通過一個例子來說明一下。炒過股票、用過股票軟體的人都知道各種周期的分析(如圖1-3所示)。
從圖1-3可以看出,股票有1分鐘、5分鐘、15分鐘、30分鐘等多個觀察周期,而各種周期之間存在着互相包含的關系,例如5分鐘的周期線實際上是由5個1分鐘的周期線組合而成的,而15分鐘的周期線是由3個5分鐘周期線組合而成,以此類推。是以,我們說股票資料的顆粒度是:1分鐘、5分鐘……
其他顆粒度的例子還有很多,例如在分析各地gdp的資料時,涉及全國、省、市、區(縣)等顆粒度;考慮家電産品的次元時,也有家電、白色家電、冰箱、型号等顆粒度。
了解了顆粒度之後,就很容易了解如下道理:資料的顆粒度越細越好,因為有了細顆粒度的資料,就可以自行組合成顆粒度比較“粗”的資料。例如我們知道了全國各個區(縣)的gdp資料,就可以推算出市、省、全國的資料,但是反向的操作無法實作,即知道了市的gdp資料,未必能夠知道下轄區(縣)的gdp資料。
綜上所述,可以得到如下結論:企業資料量比較大的、複雜度比較高的、顆粒度比較細的資料,就有比較高的分析和利用價值。