本節書摘來自華章社群《spark大資料分析實戰》一書中的第1章,第1.3節spark架構與運作邏輯,作者高彥傑 倪亞宇,更多章節内容可以通路雲栖社群“華章社群”公衆号檢視
1.3 spark架構與運作邏輯
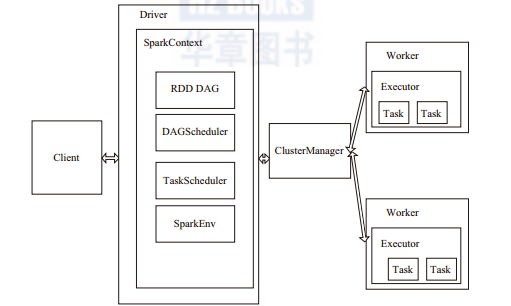
1.?spark的架構
driver:運作application的main()函數并且建立sparkcontext。
client:使用者送出作業的用戶端。
worker:叢集中任何可以運作application代碼的節點,運作一個或多個executor程序。
executor:運作在worker的task執行器,executor啟動線程池運作task,并且負責将資料存在記憶體或者磁盤上。每個application都會申請各自的executor來處理任務。
sparkcontext:整個應用的上下文,控制應用的生命周期。
rdd:spark的基本計算單元,一組rdd形成執行的有向無環圖rdd graph。
dag scheduler:根據job建構基于stage的dag工作流,并送出stage給
taskscheduler。
taskscheduler:将task分發給executor執行。
sparkenv:線程級别的上下文,存儲運作時的重要元件的引用。
2.?運作邏輯
(1)spark作業送出流程
如圖1-3所示,client送出應用,master找到一個worker啟動driver,driver向master或者資料總管申請資源,之後将應用轉化為rdd有向無環圖,再由dagscheduler将rdd有向無環圖轉化為stage的有向無環圖送出給taskscheduler,由taskscheduler送出任務給executor進行執行。任務執行的過程中其他元件再協同工作確定整個應用順利執行。
(2)spark作業運作邏輯
如圖1-4所示,在spark應用中,整個執行流程在邏輯上運算之間會形成有向無環圖。action算子觸發之後會将所有累積的算子形成一個有向無環圖,然後由排程器排程該圖上的任務進行運算。spark的排程方式與mapreduce有所不同。spark根據rdd之間不同的依賴關系切分形成不同的階段(stage),一個階段包含一系列函數進行流水線執行。圖中的a、b、c、d、e、f,分别代表不同的rdd,rdd内的一個方框代表一個資料塊。資料從hdfs輸入spark,形成rdd a和rdd c,rdd c上執行map操作,轉換為rdd d,rdd b和rdd e進行join操作轉換為f,而在b到f的過程中又會進行shuff?le。最後rdd f通過函數saveassequencefile輸出儲存到hdfs中。
