本節書摘來華章計算機出版社《r的極客理想——進階開發篇 a》一書中的第2章,第2.1節,作者:張丹 更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
問題
如何用r語言實作推薦算法?
引言
推薦系統在網際網路應用中很常見,比如亞馬遜為你推薦購書清單,豆瓣為你推薦電影清單。mahout是hahoop家族用于機器學習的分步式計算架構,主要包括三類算法,即推薦算法、聚類算法和分類算法。本節将用r語言來重寫推薦部分的基于使用者的協同過濾算法。用r語言重寫mahout的基于使用者的協同過濾推薦算法,将完全按照mahout的思路和設計進行實作,并與mahout的計算結果進行對比。
2.1.1 mahout的推薦算法模型
首先我們需要了解一下,協同過濾算法在mahout中是如何實作的。mahout的推薦算法定義了一套标準化的模型建構過程和調用過程,以基于使用者的協同過濾算法(usercf)為例,如圖2-1所示。
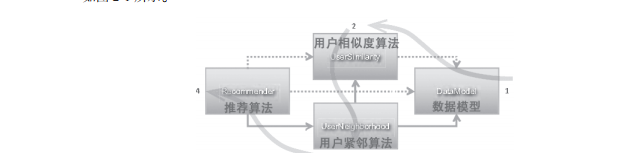
圖2-1 mahout推薦算法模型(摘自《mahout in action》)
從圖2-1中我們可以看到,基于使用者的協同過濾算法是被子產品化的,通過4個子產品進行統一的方法調用。首先,建立資料模型(datamodel),然後定義使用者的相似度算法(usersimilarity),接下來定義使用者近鄰算法(userneighborhood),最後調用推薦算法(recommender)完成計算過程。而基于物品的協同過濾算法(itemcf)過程也是類似的,去掉第三步計算使用者的近鄰算法就行了。
本節中将用r語言對mahout的0.5版本算法進行重新實作,下面是mahout在maven中版本定義。
org.apache.mahout
mahout-core
0.5
我們選用一組比較簡單的測試資料集testcf.csv,資料集分為3列:使用者id、物品id以及使用者對物品的打分。一共21行資料。
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
我們先看一下如何用java語言使用mahout庫的api,實作基于使用者的協同過濾算法的代碼。java程式實作代碼如下所示。
/**
usercf測試,單機算法實作程式
*/
public class usercf {
}
運作java程式,輸出推薦結果。
uid:1(104,4.250000)(106,4.000000)
uid:2(105,3.956999)
uid:3(103,3.185407)(102,2.802432)
uid:4(102,3.000000)
uid:5
對結果的解讀如下。
給uid=1的使用者,推薦計算得分最高的2個物品,104和106。
給uid=2的使用者,推薦計算得分最高的1個物品,105。
給uid=3的使用者,推薦計算得分最高的2個物品,103和102。
給uid=4的使用者,推薦計算得分最高的1個物品,102。
給uid=5的使用者,沒有推薦。
2.1.2 r語言模型實作
接下來,我們使用r語言重寫mahout的實作,r語言代碼将完全按照mahout源代碼的程式設計思路進行實作。為保證與java程式思路一緻,r代碼用了for循環實作,這裡暫時不考慮r程式的性能。
用r語言建構算法模型,将按照下面的5個步驟進行:
(1)建立資料模型
(2)歐氏距離相似度算法
(3)使用者近鄰算法
(4)推薦算法
(5)運作程式
1.?建立資料模型
建立資料模型的函數filedatamodel(),主要用于從csv檔案中讀取資料,然後以r語言中矩陣類型(matrix)加載到記憶體中。
filedatamodel<-function(f?ile){ # 資料模型函數
data<-read.csv(f?ile,header=false) # 讀csv檔案到記憶體
names(data)<-c("uid","iid","pref") # 增加列名
user <- unique(data$uid) # 計算使用者數
item <- unique(sort(data$iid)) # 計算産品數
uidx <- match(data$uid, user)
iidx <- match(data$iid, item)
m <- matrix(0, length(user), length(item)) # 定義存儲矩陣
i <- cbind(uidx, iidx, pref=data$pref)
for(n in 1:nrow(i)){ # 給矩陣指派
dimnames(m)[[2]]<-item
m # 傳回矩陣資料
2.?歐氏距離相似度算法
我們在計算使用者相似度算法的時候可以有多種選擇,如歐氏距離相似度算法、皮爾森相似度算法、餘弦相似度算法、spearman秩相關系數相似度算法、曼哈頓距離相似度算法、對數似然相似度算法等,很多算法都有對應的r語言函數,直接調用就可以了。按照mahout的代碼實作思路,它對于基礎的算法做了一些優化,是以我們也需要完全從底層重寫這些算法。
下面将以歐氏距離相似度算法為例,建立歐氏距離相似度的計算函數euclidean-
distancesimilarity(),加載使用者物品的矩陣資料,通過歐氏距離來計算使用者的相似度。
euclideandistancesimilarity<-function(m){
row<-nrow(m)
s<-matrix(0, row, row) # 相似度矩陣
for(z1 in 1:row){
ts<-t(s) # 補全三角矩陣
w<-which(upper.tri(ts))
s[w]<-ts[w]
s # 傳回使用者相似度矩陣
3.?使用者近鄰算法
我們在計算使用者近鄰的時候,也有2種算法來選擇。一種是以個數來計算的,選出最近的前幾個;另一種是以百分比來計算的,選出最近的前百分之幾的數量。下面将以個數計算為例,選出最近的前n個使用者。建立最近鄰計算的函數nearestnuserneighborhood(),傳入使用者的相似度矩陣和個數,就能計算出使用者最近鄰了。
nearestnuserneighborhood<-function(s,n){
4.?推薦算法
我們在計算推薦的時候,也有幾種算法可以選擇,如基于使用者的推薦算法、基于物品的推薦算法、slopeone推薦算法、itemknn推薦算法、svd推薦算法、treecluster推薦算法,這幾種推薦算法要與上面定義的資料和相似度算法進行比對才能一起使用。
下面我們建立基于使用者的推薦算法計算的函數userbasedrecommender(),通過使用者物品資料矩陣、使用者相似度矩陣、使用者最近鄰,按基于使用者的協同過濾算法實作,計算出推薦結果。
userbasedrecommender<-function(uid,n,m,s,n){
這樣基于使用者的協同過濾算法的函數,我們都已經用r程式實作了。下面按照調用關系,我們運作這些功能函數。
5.?運作程式
file<-"item.csv" # 資料檔案 neighborhood_num<-2 # 取2個最大近鄰 recommender_num<-3 # 保留最多3個推薦結果 m<-filedatamodel(file) # 把資料檔案,換成矩陣加載到記憶體 s<-euclideandistancesimilarity(m) # 計算使用者相似度矩陣 n<-nearestnuserneighborhood(s,neighborhood_num) # 計算使用者近鄰 r1<-userbasedrecommender(1,recommender_num,m,s,n);r1 # 檢視對user=1的推薦結果
[1,] "104" "4.25"
[2,] "106" "4"
[3,] "0" "0"
r2<-userbasedrecommender(2,recommender_num,m,s,n);r2 # 檢視對user=2的推薦結果
[1,] "105" "3.95699903407931"
[2,] "0" "0"
r3<-userbasedrecommender(3,recommender_num,m,s,n);r3 # 檢視對user=3的推薦結果
[1,] "103" "3.18540697329411"
[2,] "102" "2.80243217111765"
r4<-userbasedrecommender(4,recommender_num,m,s,n);r4 # 檢視對user=4的推薦結果
[1,] "102" "3"
r5<-userbasedrecommender(5,recommender_num,m,s,n);r5 # 檢視對user=5的推薦結果
[1,] 0 0
[2,] 0 0
[3,] 0 0
最後我們看到計算結果,同調用mahout的api的java程式的計算結果是一緻的。
2.1.3 算法實作的原理——矩陣變換
那麼我們算法實作的原理是什麼呢?所謂協同過濾算法,其實就是矩陣變換的結果!請大家下面留意每一步的矩陣變換。從原始資料檔案開始,如下所示。
第一步的矩陣變換,通過filedatamodel()函數,輸出使用者物品矩陣。
[1,] 5.0 3.0 2.5 0.0 0.0 0 0
[2,] 2.0 2.5 5.0 2.0 0.0 0 0
[3,] 2.5 0.0 0.0 4.0 4.5 0 5
[4,] 5.0 0.0 3.0 4.5 0.0 4 0
[5,] 4.0 3.0 2.0 4.0 3.5 4 0
第二步,利用歐氏相似度算法進行矩陣變換,運作euclideandistancesimilarity()函數,結果如下所示。
[1,] 0.0000000 0.6076560 0.2857143 1.0000000 1.0000000
[2,] 0.6076560 0.0000000 0.6532633 0.5568464 0.7761999
[3,] 0.2857143 0.6532633 0.0000000 0.5634581 1.0000000
[4,] 1.0000000 0.5568464 0.5634581 0.0000000 1.0000000
[5,] 1.0000000 0.7761999 1.0000000 1.0000000 0.0000000
第三步,通過使用者相似度矩陣,計算出使用者最近鄰,運作euclideandistancesimilarity()函數,結果如下所示。
[1,] 4 5
[2,] 5 3
[3,] 5 2
[4,] 1 5
[5,] 1 3
第四步,把上面的矩陣合并計算,通過基于使用者的推薦算法,得到每個使用者的推薦矩陣。以uid=1的使用者為例,運作userbasedrecommender()函數,結果如下所示。
4 0 0 0 4.5 0.0 4 0
5 0 0 0 4.0 3.5 4 0
打開注釋行:userbasedrecommender()函數的代碼注釋print(r) #列印每個使用者的推薦矩陣。
第五步,過濾推薦矩陣的結果,取前2個得分最高的推薦結果傳回。以uid=1的使用者為例,結果如下所示。
[1,] "104" "4.25"
[2,] "106" "4"
通過這5步矩陣變換,我們就可以清楚地看到基于使用者的協同過濾算法的本質了。當然,mahout所提供的算法。都是以矩陣為基礎的可以處理海量資料的算法。如果我們的資料量很小,可以把上面的算法過程優化并改進,降低矩陣計算的複雜度。
2.1.4 算法總結
本節隻是用r語言重寫了mahout的基于使用者的、歐氏距離相似度、個數最近鄰的協同過濾算法,重寫其他的算法過程也是類似的。另外,在讀mahout源代碼的過程中發現,mahout做各種算法時,都有自己的優化,并不是簡單地套用教課書上的算法公式。比如,計算基于歐氏距離的使用者相似度時,并不是标準的歐氏距離算法,而是改進的歐氏距離算法。
similar = 1/(1+sqrt( (a-b)^2 + (a-c)^2 )) # 歐氏距離算法
similar = n/(1+sqrt( (a-b)^2 + (a-c)^2 )) # 改進的歐氏距離算法
公式解釋:
a, b是被兩個使用者都打分的物品,也可能是1個或者多個
n是被兩個使用者都打分的物品的個數
當similar>1時,則similar=1
當similar<-1時,則similar=-1
![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)