本節書摘來自異步社群出版社《循序漸進oracle:資料庫管理、優化與備份恢複》一書中的第1章,第1.5節,作者:蓋國強,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
在本節中,我将與本章有關的一些案例診斷、故障分析收錄于此,供讀者參考。
在資料庫建立中所提到的“預防性指導報告”就包括空間指導報告,這一定時任務在很多客戶系統中帶來了極大的麻煩。
在以下客戶的sap系統中,某個高負載的時段,資料庫就遇到了dbms_scheduler任務的一個bug,其資料庫版本為10.2.0.2。
在sql ordered by elapsed time的采樣中,top 6都是dbms_scheduler排程的任務,而且耗時顯著,如圖1-28所示。
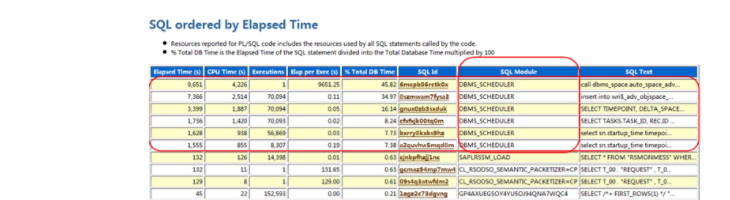
處在第一位的,是auto_space_advisor_job_proc過程調用,cpu time消耗高達4226秒:
執行花費了大量的時間,3000多秒,進而執行的sql:
也花費了2514秒的時間,這顯然是不正常的。在正常情況下,單獨跟蹤一下sql*plus中手工執行這個過程,可以獲得這個sql的執行統計資訊,跟蹤過程可能如下:
格式化跟蹤檔案,獲得以下輸出,如圖1-29所圖檔 1
圖1-29 輸出資訊
示。

注意到,這個insert仍然消耗了389秒的時間,邏輯讀429 297,性能是存在問題的。在metalink上存在如下一個bug:
**
bug 5376783: dbms_space.object_growth_trend call takes a lot of disk reads**
這個bug在dbms_space.object_growth_trend進行空間分析時被觸發,根本原因在于内部算法在執行空間檢查時,耗費了大量的評估io成本,導緻了大量的io資源使用。
臨時的處理辦法是,暫時關閉這個自動任務:
execute dbms_scheduler.disable('auto_space_advisor_job');
這個bug在10.2.0.2之後的版本中被修正。
既然oracle的預設定時任務可能會帶來如此多的問題,我們就很有必要去關注一下系統有哪些預設的任務,執行情況如何。以下是一個10.2.0.5版本的資料庫中一些自動任務的排程設定情況:
在以上的排程任務中,gather_stats_job是oracle database 10g開始引入的自動統計資訊收集的任務,該任務預設的排程是,工作日每晚22:00至淩晨6:00進行分析,周末全天進行分析。在以下輸出中,我們可以看到任務無法完成,stop的情況:
在一些大型資料庫中,這個任務不一定能夠有效執行,以下是某使用者的資料庫環境,輸出顯示,多日資料庫都因為ora-04031錯誤未能完成統計資訊收集采樣:
在gather_stats_job任務不能夠有效地執行時,我們必須及時地介入去手工處理,不及時地統計資訊可能使資料庫産生錯誤的執行計劃。
正常的auto_space_advisor_job排程可能應該有着類似以下輸出的執行結果:
在oracle資料庫的運作過程中,可能會因為一些異常遇到資料庫挂起失去響應的狀況,在這種狀況下,我們可以通過對系統狀态進行轉儲,獲得跟蹤檔案進行資料庫問題分析;很多時候資料庫也會自動轉儲出現問題的程序或系統資訊;這些轉儲資訊成為我們分析故障、排查問題的重要依據。
在一次客戶現場教育訓練中,客戶提出一個系統正遇到問題,請求我協助診斷解決,理論聯系實踐,這是我在教育訓練中極力主張的,我們的案例式教育訓練業正好遇到了實踐現場。
問題是這樣的:此前一個job任務可以在秒級完成,而現在運作了數小時也無法結束,一直挂起在資料庫中,殺掉程序重新手工執行,嘗試多次,同樣無法完成。
客戶的資料庫環境為:
介入問題診斷首先需要收集資料,我最關注兩方面的資訊:
boll 告警日志檔案,檢查是否出現過異常;
boll 生成awr報告,檢查資料庫内部的運作狀況。
通常有了這兩部分資訊,我們就可以做出初步判斷了。
檢查資料庫的告警日志檔案,我們發現其中出現過一個如下錯誤:
這個錯誤提示出現在7點左右,正是job的排程時間附近,顯然這是一個高度相關的可能原因。這個異常生成了轉儲的dump檔案,獲得該檔案進行進一步的詳細分析。該檔案的頭部資訊如下:
row cache隊列鎖無法獲得,表明資料庫在sql解析時,遇到問題,dc層面出現競争,導緻逾時。row cache位于shared pool中的data dictionary cache,是用于存儲表列定義、權限等相關資訊的。
注意以上資訊中的重要内容如下。
boll 逾時告警的時間是06:54: 2010-03-27 06:54:00.106。
boll 出現等待逾時的資料庫程序号是29:oracle process number: 29。
boll 等待逾時的29号程序的os程序号為8317:unix process pid: 8371。
boll 程序時通過sqlplus排程執行的:module name:(sqlplus)。
boll 會話的id、serial#資訊為120.46138:session id:(120.46138)。
boll 程序的state object為6c10508e8:row cache enqueue: session: 6c10508e8。
boll 隊列鎖的請求模式為共享(s):mode: n, request: s。
有了這些重要的資訊,我們就可以開始一些基本的分析。
首先可以在跟蹤檔案中找到29号程序,檢視其中的相關資訊。經過檢查可以發現這些内容與跟蹤檔案完全相符合:
進一步向下檢查可以找到so對象6c10508e8,這裡顯示該程序确實由用戶端的sql*plus發起,并且用戶端的主機名稱及程序的ospid都記錄在案:
接下來的資訊顯示,程序一直在等待,等待事件為'ksdxexeotherwait':
在這個程序跟蹤資訊的最後部分,有如下一個so對象繼承關系清單,注意這裡的owner具有級聯關系,下一層隸屬于上一層的owner,第一個so對象的owner 6c1006740就是process 29的so号。
到了最後一個級别的so 4e86f03e8上,請求出現阻塞。
row cache enqueue有一個(count=1)共享模式(request=s)的請求被阻塞:
回過頭去對比一下跟蹤檔案最初的資訊,注意這裡的session資訊正是跟蹤檔案頭上列出的session資訊:
至此我們找到了出現問題的根源,這裡也顯示請求的對象是object=4f4e57138。
跟蹤檔案向下顯示了更進一步的資訊,位址為4f4e57138的row cache parent object緊跟着之前的資訊顯示出來,跟蹤資訊同時顯示是在dc_objects層面出現的問題。
跟蹤資訊顯示對象的鎖定模式為排他鎖定(mode=x)。圖1-30是跟蹤檔案的截取,我們可以看到oracle的記錄方式:
進一步的,跟蹤檔案裡也顯示了29号程序執行的sql為insert操作:
好了,那麼現在我們來看看是哪一個程序排他的鎖定了之前的4f4e57138對象。在跟蹤檔案中搜尋4f4e57138就可以很容易地找到這個持有排他鎖定的so對象。
以下顯示了相關資訊,row cache對象的資訊在此同樣有所顯示:
<code>`</code>javascript
so: 4e86f0508, type: 50, owner: 8c183c258, flag: init/-/-/0x00
row cache enqueue: count=1 session=8c005d7c8 object=4f4e57138, mode=x
savepoint=0x2716
row cache parent object: address=4f4e57138 cid=8(dc_objects)
hash=b363a728 typ=11 transaction=8c183c258 flags=00000002
own=4f4e57208[4e86f0538,4e86f0538] wat=4f4e57218[4e86f0418,4e86f0418] mode=x
status=valid/-/-/-/-/-/-/-/-
set=0, complete=false
data=
00000038 00134944 585f4341 43495f49 4e565f42 4c425f44 43000000 00000000
00000000 04000009 505f3230 31305f51 31000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 000209ca ffff0000 000209ca 14786e01 020e3239
786e0102 0e323978 6e01020e 32390100 00000000 00000000 00000000 00000000
00000000 00000006
process 16:
----------------------------------------
so: 8c00037d0, type: 2, owner: 0, flag: init/-/-/0x00
(process) oracle pid=16, calls cur/top: 8c0095028/8c0094aa8, flag: (0) -
int error: 0, call error: 0, sess error: 0, txn error 0
(post info) last post received: 115 0 4
last post received-location: kslpsr
last process to post me: 6c1002800 1 6
last post sent: 0 0 24
last post sent-location: ksasnd
last process posted by me: 6c1002800 1 6
(latch info) wait_event=0 bits=0
process group: default, pseudo proc: 4f818c298
o/s info: user: oracle, term: unknown, ospid: 8200
osd pid info: unix process pid: 8200, image: oracle@sf2900 (j000)
在這裡可以看到16号程序是一個job程序,其程序為j000,那麼這個job程序在執行什麼操作呢?下面的資訊可以看出一些端倪,job由dbms_scheduler排程,執行auto_space_advisor_job任務,處于wait for shrink lock等待:
job slave state object
slave id: 0, job id: 8913
----------------------------------------
so: 8c005d7c8, type: 4, owner: 8c00037d0, flag: init/-/-/0x00
(session) sid: 45 trans: 8c183c258, creator: 8c00037d0, flag: (48100041) usr/- bsy/-/-/-/-/-
did: 0001-0010-0007bfa6, short-term did: 0000-0000-00000000
txn branch: 0
oct: 0, prv: 0, sql: 0, psql: 0, user: 0/sys
o/s info: user: oracle, term: unknown, ospid: 8200, machine: sf2900
program: oracle@sf2900 (j000)
application name: dbms_scheduler, hash value=2478762354
action name: auto_space_advisor_job, hash value=348111556
waiting for 'wait for shrink lock' blocking sess=0x0 seq=5909 wait_time=0 seconds since wait started=3101
object_id=0, lock_mode=0, =0
dumping session wait history
for 'wait for shrink lock' count=1 wait_time=380596
for 'wait for shrink lock' count=1 wait_time=107262
for 'wait for shrink lock' count=1 wait_time=107263
for 'wait for shrink lock' count=1 wait_time=107246
for 'wait for shrink lock' count=1 wait_time=107139
for 'wait for shrink lock' count=1 wait_time=107248
for 'wait for shrink lock' count=1 wait_time=107003
for 'wait for shrink lock' count=1 wait_time=107169
for 'wait for shrink lock' count=1 wait_time=107233
for 'wait for shrink lock' count=1 wait_time=107069
temporary object counter: 3
so: 4e8a2c6c0, type: 53, owner: 8c005d7c8, flag: init/-/-/0x00
library object lock: lock=4e8a2c6c0 handle=4c3c1ce60 mode=n
call pin=0 session pin=0 hpc=0000 hlc=0000
htl=4e8a2c740[4e81436e0,4e8c80c98] htb=4e8937910 ssga=4e8936e48
user=8c005d7c8 session=8c005d7c8 count=1 flags=[0000] savepoint=0x4bad2eec
library object handle: handle=4c3c1ce60 mtx=4c3c1cf90(1) cdp=1
name=alter index "caci"."idx_caci_inv_blb_dc" modify partition "p_2010_q1" shrink space check
hash=0ed1a6f7b2cf775661d314b8d1b7659b timestamp=03-25-2010 22:05:09
namespace=crsr flags=ron/kghp/tim/pn0/med/kst/dbn/mtx/[500100d0]
kkkk-dddd-llll=0000-0001-0001 lock=n pin=0 latch#=15 hpc=0002 hlc=0002
lwt=4c3c1cf08[4c3c1cf08,4c3c1cf08] ltm=4c3c1cf18[4c3c1cf18,4c3c1cf18]
pwt=4c3c1ced0[4c3c1ced0,4c3c1ced0] ptm=4c3c1cee0[4c3c1cee0,4c3c1cee0]
ref=4c3c1cf38[4c3c1cf38,4c3c1cf38] lnd=4c3c1cf50[4c3c1cf50,4c3c1cf50]
library object: object=4aa2bf668
type=crsr flags=exs[0001] pflags=[0000] status=vald load=0
children: size=16
child# table reference handle
------ -------- --------- --------
0 49efa3fe8 49efa3c58 4c3ad91a8
1 49efa3fe8 49efa3ed8 4c3941608
data blocks:
data# heap pointer status pins change whr
----- -------- -------- --------- ---- ------ ---
0 4c3589b38 4aa2bf780 i/p/a/-/- 0 none 00