本節書摘來異步社群《python機器學習——預測分析核心算法》一書中的第1章,第1.5節,作者:【美】michael bowles(鮑爾斯),更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
使用機器學習需要幾項不同的技能。一項就是程式設計技能,本書不會把重點放在這。其他的技能用于獲得合适的模型進行訓練和部署。這些其他技能将是本書重點關注的。那麼這些其他技能包括哪些内容?
最初,問題是用多少有些模糊的日常語言來描述的,如“給網站通路者展示他們很可能點選的連結”。将其轉換為一個實用的系統需要用具體的數學語言對問題進行重述,找到預測所需的資料集,然後訓練預測模型,預測網站通路者對出現的連結點選的可能性。對問題用數學語言進行重叙,其中就包含了對可獲得的資料資源中抽取何種特征以及對這些特征如何建構的假設。
當遇到一個新問題時,應該如何着手?首先,需要浏覽可獲得的資料,确定哪類資料可能用于預測。“浏覽”的意思是對資料進行各種統計意義上的檢測分析,以獲得直覺感受這些資料透露了什麼資訊,這些資訊又與要預測的有怎樣的關系。在某種程度上,直覺可以指導你做些工作,也可以量化結果,測試潛在的這些預測特征與結果的相關性。第2章将詳細介紹對資料集測試分析的過程,本書餘下部分所述的算法及其比較會用到這些資料集。
假設通過某種方法,選擇了一組特征,開始訓練機器學習算法。這将産生一個訓練好的模型,然後是估計它的性能。下一步,可能會考慮對特征集進行調整,包括增加新的特征,删除已證明沒什麼幫助的特征,或者選擇另外一種類型的訓練目标(也叫作目标函數),通過上述調整看看能否提高性能。可以反複調整設計決策來提高性能。可能會把導緻性能比較差的資料單獨提出來,然後嘗試是否可以從中發現背後的規律。這可以導緻添加新的特征到預測模型中,也可以把資料集分成不同的部分分别考慮,分别建立不同的預測模型。
本書的目的是讓你熟悉上述處理過程,以後遇到新問題就可以獨立完成上述步驟。當重述問題、提取特征、訓練算法、評估算法時,需要熟悉不同算法所要求的輸入資料結構。此過程通常包括如下步驟。
(1)提取或組合預測所需的特征。
(2)設定訓練目标。
(3)訓練模型。
(4)評估模型在測試資料上的性能表現。
注意
在完成第一遍過程後,可以通過選擇不同的特征集、不同的目标等手段來提高預測的性能。
機器學習要求不僅僅是熟悉一些工具包。它是開發一個可以實際部署的模型的全部過程,包括對機器學習算法的了解和實際的操作。本書的目标就是在這方面提供幫助。本書假設讀者具有大學大學的基礎數學知識、了解基本的機率和統計知識,但是本書不預設讀者具有機器學習的背景知識。同時本書傾向于給讀者直接提供針對廣泛問題具有最佳性能的算法,而不需要通覽所有機器學習相關的算法或方法。有相當數量的算法很有趣,但是因為各種原因并沒有獲得廣泛使用。例如,這些算法可能擴充性不好,不能對内部的運作機理提供直覺的解釋,或者很難使用,等等。例如,衆所周知随機森林算法(本書将會介紹)在線上機器學習算法競争中遙遙領先。通常有非常切實的原因導緻某些算法被經常使用,本書的目标就是在你通讀完本書後對這方面具有充分了解。
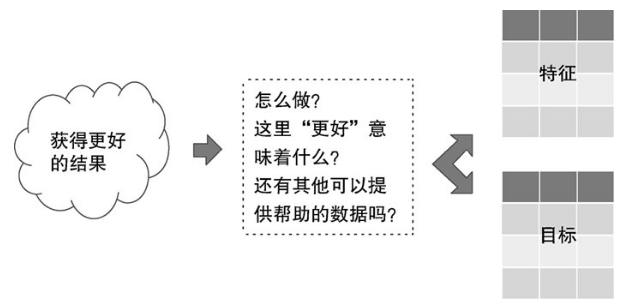
參加機器學習算法競賽可以看作是解決真實機器學習問題的一個仿真。首先機器學習算法競賽會提供一個簡短的描述(例如,宣稱一個保險公司想基于現有機動車保險政策更好地預測保費損失率)。作為參賽選手,你要做的第一步就是仔細審視資料集中的資料,确定需要做哪種形式的預測。通過對資料的審視,可以獲得直覺的感受:這些資料代表什麼,它們是如何與預測任務關聯起來的。資料通常可以揭示可行的方法。圖1-5描述了從通用語言對預測目标的描述,到對資料的整理準備,以作為機器學習算法輸入的基本步驟。
首先,通俗的說法“獲得更好的結果”需要先轉換成可測量可優化的具體目标。作為網站的擁有者,更好的結果可以是提高點選率或更高的銷售額(或更高的利潤)。下一步就是收集資料,隻要其有助于預測:特定使用者有多大可能性會點選各種不同類型的連結,或購買線上提供的各種商品。将這些資料表示為特征的矩陣,如圖1-5所示。以網站為例,這些特征可能包括:網站通路者之前浏覽的其他網頁、通路者之前購買的商品。除了用于預測的這些特征,針對此類問題的機器學習算法還需要已知正确的答案用于訓練。在圖1-5中表示為“目标”。本書涵蓋的算法通過使用者過去的行為來發現使用者的購買模式,當然算法不是單純地記憶使用者過去的行為,畢竟一個使用者不可能重複購買他昨天剛剛購買的商品。第3章将詳細讨論無記憶行為的預測模型的訓練過程。
通常構造一個機器學習問題可以采用不同的方法。這就導緻了問題的構造、模型的選擇、模型的訓練、模型性能評估這一過程會發生多次疊代,如圖1-6所示。

與問題随之而來的是定量的訓練目标,或者部分任務是資料提取(這些資料叫作目标或标簽)。例如,考慮建立一個自動化預測證劵交易的系統。為了實作交易的自動化,第一步可能是預測證劵的價格變化。這些價格是很容易獲得的,是以利用曆史資料建構一個訓練模型來預測未來價格的變化應該是容易的。但是即使這一過程包含了多種算法的選擇和實驗,未來價格的變化仍然可以用多種方法來計算。這種價格的變化可以是目前價格與10分鐘之後的價格的差異、目前價格與10天之後的價格差異,也可以是目前價格與接下來的10分鐘内價格的最高值、最低值之間的差異。價格的變化可以用一個2值的變量來表示:“高”或“低”,這依賴于10分鐘之後價格是升高還是降低。所有這些選擇将會導緻不同的預測模型,這個預測模型将用于決定是買入還是賣出證劵,需要實驗來确定最佳的選擇。
确定哪些特征可用于預測也需要實驗嘗試。這個過程就是特征提取和特征工程。特征提取就是一個把自由形式的各種資料(如一個文檔中的字詞、一個網頁中的字詞)轉換成行、列形式的數字的過程。例如,垃圾郵件過濾的問題,輸入就是郵件的文本,需要提取的東西包括:文本中大寫字母的數量、所有大寫的詞的數量、在文檔中出現詞“買”的次數,等等,諸如此類的數值型特征。然後基于這些特征把垃圾郵件從非垃圾郵件中區分出來。
特征工程就是對特征進行整理組合,以達到更富有資訊量的過程。建立一個證劵交易系統包括特征提取和特征工程。特征提取将決定哪些特征可以用來預測價格。過往的價格、相關證劵的價格、利率、從最近釋出的新聞提取的特征都是現有公開讨論的各種交易系統的輸入資料。而且證劵的價格還有一系列的工程化特征,包括:指數平滑異同移動平均線(moving average convergence and divergence,macd)、相對強弱指數(relative strength index,rsi)等。這些特征都是過往價格的函數,它們的發明者都認為這些特征對于證劵交易是非常有用的。
選好一系列合理的特征後,就像本書描述的那樣,需要訓練一個預測模型,評價它的性能,然後決定是否部署此模型。為了確定模型的性能足夠滿足要求,通常需要調整采用的特征。一個确定使用哪些特征的方法就是嘗試所有的組合,但是這樣時間代價太大。不可避免地,你面臨着提高性能的壓力,但是又需要迅速獲得一個訓練好的模型投入使用。本書讨論的算法有一個很好的特征,它們提供對每個特征對最終預測結果的貢獻的度量。經過一輪訓練,将會對特征打分以辨別其重要性。這些資訊可以幫助加速特征工程的過程。
資料準備和特征工程估計會占開發一個機器學習模型80%~90%的時間。
模型的訓練也是一個過程,每次開始都是先選擇作為基線的特征集合。作為一個現代機器學習算法(如本書描述的算法),通常訓練100~5000個不同的模型,然後從中精選出一個模型進行部署。産生如此之多的模型的原因是提供不同複雜度的模型,這樣可以挑選出一個與問題、資料集最比對的模型。如果不想模型太簡單又不想放棄性能,不想模型太複雜又不想出現過拟合問題,那麼需要從不同複雜度的模型中選擇一個最合适的。
一個模型合适與否是由此模型在測試資料集上的表現來決定的。這個雖然概念上很簡單,卻是非常重要的一步。需要留出一部分資料,不用于訓練,用于模型的測試。在訓練完成之後,用這部分資料集測試算法的性能。本書讨論了留出這部分測試資料的方法。不同的方法各有其優勢,主要依賴于訓練資料的規模。就像字面上了解那麼簡單,人們持續地提出各種複雜的方法讓測試資料“滲入”訓練過程。在處理過程的最後階段,你将獲得一個算法,此算法讀取資料,産生準确的預測。在這個過程中,你可能需要檢測環境條件的變化,這種變化往往會導緻潛在的一些統計特性的變化。