本節書摘來異步社群《storm技術内幕與大資料實踐》一書中的第9章,第9.4節,作者: 陳敏敏 , 黃奉線 , 王新春
責編: 楊海玲,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
在pc網際網路時代,谷歌2005年就推出了個性化搜尋服務,因為引發公衆對隐私的擔憂,沒有太商業化,如今移動網際網路時代,去哪兒、京東等電商,慢慢都推出了個性化搜尋,無論消費者登入與否,通過追蹤客戶的搜尋行為來判斷其消費喜好,即便使用者登出,也會根據cookie、裝置号等資訊,給使用者傳回個性化的搜尋内容。當然搜尋引擎本身的爬蟲/反爬蟲等異常檢測、對搜尋關鍵字分詞後進行同義詞/反義詞/全半角/簡繁體等自動擴充以及錯别字的糾正都可以在實時計算中進行資料清洗。例如,ebay應用jetstream流處理技術,對海量的使用者行為進行了實時的資料清洗。
要讓個性化的搜尋内容更加精準,需要打通外部使用者畫像和不斷更新着的商家的服務、商品等。在電商的搜尋系統中,為了解決搜尋的并發和性能,往往有記憶體中的實時分布式索引和硬碟中的全量索引,熱門商品資訊直接從記憶體中讀取,當記憶體中不存在時,才從硬碟中讀全量索引。在實時流計算出來之前,初始化分布式索引對索引的切分很多時候是根據類目。不同的類目的pv和産品數不一樣,根據每一個類目的pv和産品數不同,對産品的索引進行切分。有的類目pv高,産品數少,放到記憶體中,備援多份資料在不同的機器上;有的類目pv少,産品數多,這種就不适合初始化進實時索引中了。當賣家更新和增加産品資訊時,索引等産品資訊統一更新到一個地方,然後每隔一段時間把資訊一并推送到分布式索引中。當實時流計算出來之後,實時的更新分布式索引就更加友善了。
電商的搜尋系統中,一般都會自己維護一套詞庫,以對搜尋内容進行更加準确地切詞,然後通過切出來的詞映射到對應的類目、品牌等。電商每一個類目的專有名詞比較多,僅僅應用外面通用的中文分詞詞庫在實踐中很難提高分詞的準确性。在這裡,想強調下,維護一個自己的屬性、品牌詞庫,對整個網站價值很大。首先,自己的準确的詞庫讓使用者畫像系統也會更加精準。網站早期很多産品屬性命名的不統一,相同的屬性,業務方錄入很多不同的屬性名稱,導緻一個系統的産品屬性到後面往往是混亂的,畫像打出來的分也是以不能準确反應出使用者的偏好。有準确和健全的詞彙,一來可以對屬性做清洗,提高使用者打分的準确性,二來可以規範業務方錄入的各種産品的命名等,讓業務方更好地進行品類管理。其次,對電商的比價系統也是至關重要。電商往往要識别其他競争對手的同類産品的價格,好進行智能調價或者統計,準确的詞彙,能讓系統更精确的對産品的标題進行分詞和特征詞标注,提高抓取競争對手網站産品的覆寫率和比對準确率。最後,對識别使用者搜尋的内容也是不可或缺的,有了完善的自己的詞庫,對搜尋的内容才能進行更加準确地切分和映射,更加精準地明白使用者想要的産品、類目等,進而提高使用者搜尋排序的準确率,以及減少使用者篩選時間。
在電商系統中,在書籍、衣服等同一類目下用基于itemcf的推薦計算出産品相似度,推薦同類目下其他産品,相對可解釋。但是如果因為兩本書所購買的人群比較相似,把人群中a使用者喜歡的某茶葉推薦給b使用者,顯然不大好解釋。是以我們應首先識别使用者目前需要購物的類目,并識别出購物類目的意圖,再在同一類目下通過協同過濾、内容推薦等方式給使用者推薦合适的商品。目前各大電商網站都在識别使用者搜尋的實時意圖上進行了不同程度的探索和研發,有些在使用者長期畫像的基礎上抽出一張使用者短期畫像表來實作,我們認為使用者對大部分的品牌和産品具有長期的偏好,偏好的更新周期相對比較長;而對于類目,使用者往往根據外界環境、家庭短缺等不确定因素而購買,比如家裡什麼東西意外壞了需要補充,如果能實時的識别使用者需要購買的類目,顯然是比較有價值的。我們假設使用者畫像有使用者基礎屬性(性别、年齡、職業等)和使用者偏好(類目、品牌、産品等),在使用者偏好的基礎上抽出長期偏好和短期偏好兩個表,用短期偏好和基礎屬性來實時預測使用者購買類目,再記錄各個類目的使用者短期購買行為。因為基于鄰域的協同過濾具有擴充性問題,計算複雜度随着使用者數和産品數增加而增加,在實時推薦中,是一個亟需要解決的問題,我們這裡用判别分析方法實時預測使用者需要購買的類别(判别分析法實際上是一種基于模型的推薦算法)。判别分析是使用者判斷個體所屬類别的一種統計方法,對使用者的購買意圖進行預測,根據已知觀測對象的分類和若幹表明觀測對象特征的變量值,建立判别函數和判别準則,并使其錯判率最小。
我們儲存最近一段時間有過使用者行為的使用者
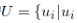
最近一段時間有行為的使用者} 最近一段時間有行為的使用者}。
對u_i取其基礎屬性和短期偏好(性别、年齡、購買cj時的地域、購買cj時的時間、品類偏好等)組成基礎屬性向量

表示使用者u_i的某一個基礎屬性和偏好,n表示屬性和偏好的具體數量。
對u_i取其發生購買某個類别cj前的相關行為(浏覽、搜尋、收藏、加車、購買某個品類),組成行為向量
,表示使用者u_i在購買cj前某項行為的次數,n表示行為總數量,m表示使用者數。則我們得到購買類目cj的使用者組成的矩陣:
将
的行向量看作n維随機向量,對其進行降維,采用pca(主成分分析)技術進行降維,然後對
采用資訊增益技術進行特征選取,選取topn個最能判别使用者購買意圖的基礎屬性。常用的判别函數有fisher判别法、馬式距離判别法、廣義平方距離判别法、最大後驗機率判别法、貝葉斯判别法等,它們各自有不同的優缺點,當加入或者減少某一種條件,它們又可以互相轉換。這裡我們以馬氏距離為例,與歐氏距離不同的是它考慮到各種特性之間的聯系,馬氏距離能夠很好地處理多元向量各次元的量綱不一緻的問題以及各次元具有相關性的問題,隻需要知道總體的特征值,不需要知道總體的分布類型,方法簡單,結論明确。首先根據樣本矩陣
統計購買cj這個總體的協方差矩陣
和總體均值向量
:
對任意使用者u_i,設其降維後的行為向量為a_i ,得到使用者與cj總體的廣義馬氏距離為
其中text{q_j } 為總體cj發生的先驗機率,根據使用者u_i與總體cj的距離,即可以得到使用者最近一段時間内topn的意圖類目,然後利用建構的場景引擎應用到相應的欄位。我們以個性化搜尋為例,當使用者剛上來,沒有太多初始化行為的時候,預設排序根據使用者的長期偏好、廣告主投放等排序,當使用者點選浏覽了一定的商品後,利用上面的判别分析方法,實時預測出使用者實時的類目,當使用者再次搜尋或者到達某一個推薦欄位的時候,結合得到的實時topn的意圖類目,并給予一定的權重,融進原來的排序結果,給出新的排序結果,如圖9-18所示。
在推薦欄位中,得到使用者topn的類目再在同類目下利用協同過濾、關聯規則等推薦方法,對同一類目下的産品進行相關推薦,以得到更加精準的結果;但是在搜尋系統中,往往搜尋詞已經映射到相應的一些類目上,這個時候,對使用者需要購買的産品、品牌的意圖識别往往更有用,比如品牌,因為數量相對産品小很多。可以把類目的意圖識别方法應用過來,然後融入實時個性化搜尋中。對于海量的産品,可以根據使用者前面幾年購買的産品屬性、天氣、地域等各類标簽預先作一定的關聯分析,然後把天氣,地域等标簽融入選品中心,通過這些标簽做意圖識别。
一淘、幫5買、網易惠惠等都是目前比較成熟的比價搜尋,通過它們能搜出各類商品在各個電商上的價格;目前不少電商也實作了自己的比價/調價系統。如何定價,是傳統零售業和電商必須需要思考的問題,隻有定價政策應用得當,才能在成本、銷量、利潤、轉化率上找到一種平衡。而且電商相比其他的網際網路産品,使用者粘性偏弱,使用者對價格敏感性更強,往往一點點的差價,就會影響使用者的留存率和産品的利潤,是以合理設定和競争對手商品的價格,在利潤和使用者轉化率上取得平衡,才能提高電商的整體競争力。面對百萬、甚至千萬的sku,通過人工來定價成本非常高,是以需要系統進行智能定價。當然系統中也會設定自己的價格底線,如果發現對手的價格偏低,那麼可以及早地分析是不是對手的進貨管道不同,或者是不是他們在營運、物流、供應鍊上成本控制得更好,還是對手貼錢促銷。及時知道熱門商品競争對手的資訊,可以快速優化自己的營運和決策,可以挖掘出競争對手新品和好的缺失品,對自己的品類分析、品類管理、價格監控等都有非常大的價值。
一個比價系統通常包括爬蟲系統、比對系統、資料分析系統、智能決策系統(優化品類、自動調價、促銷政策等)。爬蟲系統用來抓取競争對手的商品資訊,java的爬蟲一般應用httpclient和jsoup庫來實作,通過httpclient發起http請求,通過jsoup解析請求回來的頁面的元素。但是有些電商網站商品頁的價格、庫存、評論數等值,在頁面的源代碼裡面是無法擷取到的,它們往往是頁面裡面有另外的ajax請求去擷取價格、庫存等值,然後通過javascript填充到頁面的相關div或者span等位置,通過java的方式抓取腳本通常都是要發起多個請求才能完成一次完整資訊的抓取,失敗率也特别高,抓取腳本相當複雜,去開發一個java的javascript解析引擎時間成本又過高。而python有pyqt4這個類庫,它有内置的webkit浏覽器引擎,通過它來請求url,傳回的html源碼是渲染好的網頁,價格、庫存等資訊已經填充在了相應的html元素中,不用多次請求。如果用java的runtime的方式去調用python腳本,顯然性能存在一定的損耗,但storm支援python等多種語言,這樣可以不受語言限制,充分運用各類優秀的開源庫,更低成本地實作爬蟲系統。python有解析html元素成熟的beautifulsoup庫(類似java的jsoup庫),結合python的urllib2或者requests庫,可以更好地完成這個任務。
有了爬蟲系統,要得到同一款商品競争對手的資訊,那麼比對系統運用而生,假設不考慮商品詳情頁中價格、商品介紹、商品圖檔等因素,僅對商品詳情頁的标題做比對,一般把标題切成特征詞(品牌詞、規格、貨号、成份、品類詞),然後不同類目下給每種特征詞不同的權重,計算出哪些商品是同一商品,進而結合調價系統,進行自動調價。
有諸多的因子決定電商搜尋産品的排序,常見的包括:是否自營、銷售額、銷量、收藏數、點選數,曝光數、毛利率、使用者評價數、好評率、是否促銷、退款率、投訴率、發貨速度等。如果是商城或者店鋪,商品的排序因子主要如表9-6所示,分為推廣量、服務、店鋪優化、店鋪等級等。同時商家為了提高商品排名,會出現不同程度的作弊,有的通過虛假交易進行刷單;有的在商品标題中加入競争對手品牌;有的用低價引流,實際上是将一個低價産品和一個正常産品組成套餐;有的過一陣偷偷更換标題和商品,把一個銷量比較好的商品變成另外一個新商品,這些不同的作弊方式也是一個排序因子,用來懲罰違規的商家。
影響排序因子又分為靜态因子和動态因子,如表9-7所示。動态因子中對搜尋關鍵字和标題相關性的計算需要對标題進行切詞,前面比價系統中的比對子產品也需要對标題進行切詞,兩者的切詞算法可以用一套,關鍵是對各個商家和品牌的一些詞彙需要人工整理,這個一般會耗費一定的成本。
可以看到,影響搜尋排序的因子數目繁多,并且不同的因子(比如銷售額、送貨速度、好評率等)量綱不同,首先需要對各個因子歸一化,不同的因子需要設計不同的歸一化公式。歸一化後,根據各因子對結果的貢獻不同,要設定不同的權重,可以通過svm等機器學習算法來訓練各因子的系數。檢測訓練出來的模型是否靠譜,通常使用已知目标值的樣本作為輸入,觀察其準确率。對于電商而言,轉化率是一個不錯的選擇,轉化率的分子可以是商品的銷售量、銷售額、加入購物車的數目等,分母可以用商品的曝光率。訓練得到各因子系數,并且模型經過驗證後,搜尋的基本排序公式應運而生,實際的系統中還會加入人工規則和廣告競價排序的因素。