本節書摘來自華章出版社《移動資料挖掘》一 書中的第2章,第2.3節,作者連德富 張富峥 王英子 袁晶 謝幸,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
很多移動軌迹資料都具有非常高的備援性,比如,志願者收集的gps軌迹和計程車的gps軌迹都是間隔幾秒記錄一次gps點。然而,這些移動對象在短短幾秒内乃至十幾秒内一般不會有大的變化。另外,有很多中間的實體,使用者隻是經過,并不感興趣。因而,需要對所收集的這些移動軌迹資料進行預處理,抽取出使用者感興趣的地方。這類興趣地點應該具有停留時間較長的特點。也就是說,這類興趣地點應該在空間次元具有聚集效應。為此,大部分先前的重要地點檢測的方法是在時間限制的情況下在空間次元進行聚類。這類工作的先驅者是佐治亞理工學院的阿什布魯克和斯達納教授。他們在文章[6,5]中提出了place(地方)和location(地點)的概念,認為地方是帶有時間區間(即停留時間)的gps位置,而地點則是地方(place)的聚類。place的檢測比較簡單,首先需要将gps軌迹中在順序上鄰接的距離在gps誤差範圍(10米以内)以内的gps點合并,作為一個place,其gps位置即為這些gps的平均值,同時取出該place在軌迹中第一次出現的時間和最後一次出現的時間,這兩個時間之間的時間間隔作為該place的停留時間。他們的文獻所闡述的關于place的聚類算法類似于mean-shift聚類的思想。即每次從一個place開始,帶上一個半徑,然後針對所有存在于place半徑範圍内的place點來計算均值。這個均值點作為新的place,再重複上述過程,直到均值不再變化為止。這個時候就找到了第一個location。然後把這個location相關的place點删除。針對剩下的place點進行上述聚類方法,直到将所有的點都删除完。圖2.8給出了聚類的示例。關于聚類中取多少個類的問題,作者采用了繪制聚類個數随着半徑增長的圖,然後從圖中找到拐點處(knee)作為最終的聚類半徑。這裡的拐點和數學中拐點的定義不同。數學中的拐點是可微分曲線中改變凹凸性的點,而
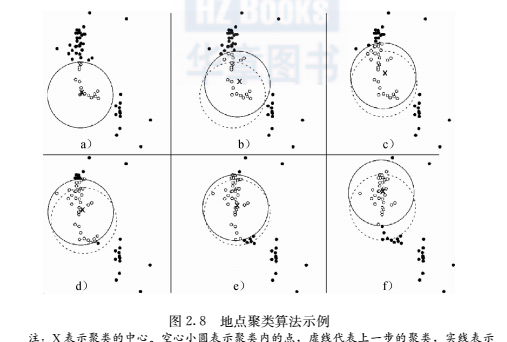
這裡需要注意的是,聚類算法是不考慮時間上的限制的,即不管這兩個place在通路時間上是否相隔很久。此外,該文獻中還考慮了location的地理層次性問題,并定義了sublocation的概念,并應用上述類似的聚類算法在每個location中尋找sublocation。
在此之後,很多相關的重要地點檢測的算法[38,47,48,69,159,16]先後被提出。大部分算法的思想都是類似的,可能location和place的相關概念有所不同,或者是把location的形成和place的抽取合并為一個過程。比如在參考文獻[47,48]中,提出了一種基于時間的聚類方法,這種聚類方法不僅能夠自動确定聚類的個數,而且還會過濾掉一些噪聲點。這個聚類算法對gps的軌迹流進行聚類,并且丢棄停留時間很短的那些小簇。特别地,軌迹流的第一個gps點形成一個目前簇,之後的每一個gps點都會與目前簇的所有gps點進行比較,如果平均距離大于某個門檻值,則會形成一個新的簇,否則将并入原來的簇中。關于算法中的時間門檻值和距離門檻值的确定,同樣是通過類似于上述的拐點的方法來獲得的。另一類方法始于參考文獻[38],其中提出了與place類似概念的停留點(stay of point)。參考文獻[55,69]做了跟進,不過并沒有在重要地點檢測這個問題上做出方法的創新。停留點定義為停留了一段時間的某個地方。從字面上看,這個詞由于有“停留”,蘊含了時間概念,因而表述更加貼切,是以後續的研究中被使用得更多。停留點依賴于兩個參數,一個是停留門檻值,代表停留的最少時間;另一個是距離門檻值,代表這個地方的最大地理範圍。下面給出參考文獻[38]的算法架構,如圖2.9所示。算法中的函數medoid(r,i,j)和diameter(r,i,j)是在集合{rkrk∈r,i≤k不過在檢測停留點之後,從不同軌迹中檢測出來的停留點之間可能是不一緻的,即有些離得很近的停留點卻是不同的,被賦予了不同的停留點編号,這為所有人進行使用者移動模組化和基于移動行為進行朋友關系預測制造了很大的困難。為此,與斯達納教授團隊的研究類似,也需要對這些來自不同軌迹的停留點進行聚類。不同的研究工作在聚類算法上大同小異[55,16],一般都是利用k均值或類似于dbscan的密度聚類法,而且一般是具有層次性的,如圖2.10所示。它們的差異性主要展現在使用的特征上,比如在參考文獻[6,55]中,使用停留點之間的實體距離來進行聚類。而在參考文獻[16]中,不僅使用了距離,還使用了停留點的語義資訊,比如停留點的通路時間差異性、停留時間差異性、通路使用者群體的相似性,以及相關語義資訊。
