本節書摘來自華章出版社《深入淺出dpdk》一書中的第2章,第2.9節numa系統,作者朱河清,梁存銘,胡雪焜,曹水 等,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
2.9 numa系統
之前的章節已經簡要介紹過numa系統,它是一種多處理器環境下設計的計算機記憶體結構。numa系統是從smp(symmetric multiple processing,對稱多處理器)系統演化而來。
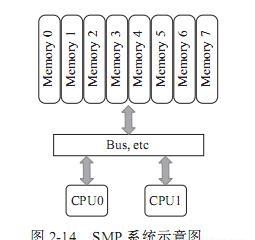
smp系統最初是在20世紀90年代由unisys、convex computer(後來的hp)、honeywell、ibm等公司開發的一款商用系統,該系統被廣泛應用于unix類的作業系統,後來又擴充到windows nt中,該系統有如下特點:
1)所有的硬體資源都是共享的。即每個處理器都能通路到任何記憶體、外設等。
2)所有的處理器都是平等的,沒有主從關系。
3)記憶體是統一結構、統一尋址的(uma,uniform memory architecture)。
4)處理器和記憶體,處理器和處理器都通過一條總線連接配接起來。
其結構如圖2-14所示:
smp的問題也很明顯,因為所有的處理器都通過一條總線連接配接起來,是以随着處理器的增加,系統總線成為了系統瓶頸,另外,處理器和記憶體之間的通信延遲也較大。為了克服以上的缺點,才應運而生了numa架構,如圖2-15所示。

numa是起源于amd opteron的微架構,同時被英特爾nehalem架構采用。在這個架構中,處理器和本地記憶體之間擁有更小的延遲和更大的帶寬,而整個記憶體仍然可作為一個整體,任何處理器都能夠通路,隻不過跨處理器的記憶體通路的速度相對較慢一點。同時,每個處理器都可以擁有本地的總線,如pcie、sata、usb等。和記憶體一樣,處理器通路本地的總線延遲低,吞吐率高;通路遠端資源,則延遲高,并且要和其他處理器共享一條總線。圖2-16是英特爾公司的至強e5伺服器的架構示意圖。
可以看到,該架構有兩個處理器,處理器通過qpi總線相連。每個處理器都有本地的四個通道的記憶體系統,并且也有屬于自己的pcie總線系統。兩個處理器有點不同的是,第一個處理器內建了南橋晶片,而第二個處理器隻有本地的pcie總線。
和smp系統相比,numa系統通路本地記憶體的帶寬更大,延遲更小,但是通路遠端的記憶體成本相對就高多了。是以,我們要充分利用numa系統的這個特點,避免遠端通路資源。
以下是dpdk在numa系統中的一些執行個體。
1)per-core memory。一個處理器上有多個核(core),per-core memory是指每個核都有屬于自己的記憶體,即對于經常通路的資料結構,每個核都有自己的備份。這樣做一方面是為了本地記憶體的需要,另外一方面也是因為上文提到的cache一緻性的需要,避免多個核通路同一個cache行。
2)本地裝置本地處理。即用本地的處理器、本地的記憶體來處理本地的裝置上産生的資料。如果有一個pci裝置在node0上,就用node0上的核來處理該裝置,處理該裝置用到的資料結構和資料緩沖區都從node0上配置設定。以下是一個配置設定本地記憶體的例子:
該例試圖配置設定一個結構體,通過傳遞socket_id,即node id獲得本地記憶體,并且以cache行對齊。