本節書摘來自華章出版社《多核與gpu程式設計:工具、方法及實踐》一書中的第3章,第3.8節, 作 者 multicore and gpu programming: an integrated approach[阿聯酋]傑拉西莫斯·巴拉斯(gerassimos barlas) 著,張雲泉 賈海鵬 李士剛 袁良 等譯, 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
3.2.3.1節介紹過,qt管理一組就緒的線程池,不需要作業系統來配置設定和初始化新線程實體。盡管建立線程的開銷較之建立程序的開銷要小幾個量級,但它仍然是較為耗時的,特别是當線程需要在運作時動态生成時。一個經典的粒子是監聽請求和配置設定線程進行服務的并發web或者資料庫伺服器。在這種情況下線程可以從一個空閑線程庫中選取并重用,而不是為每一個請求建立一個新的線程。<code>qthreadpool</code>類提供的功能正是這種線程庫。
本節将要介紹如何利用<code>qthreadpool</code>,以及如何建立線程庫,即使線程庫并不是嵌入式的。
<code>qthreadpool</code>類和<code>qtconcurrent</code>命名空間函數提供給了高效、簡單地擴充到多線程應用程式的方法(即使線程并不需要共享資源)。唯一的問題是隻有當存在一個可用線程時,由獨立線程運作的函數才會執行。
代碼清單3-25是代碼清單3-10生産者和消費者代碼的重寫版本,用于說明如何利用這些功能。
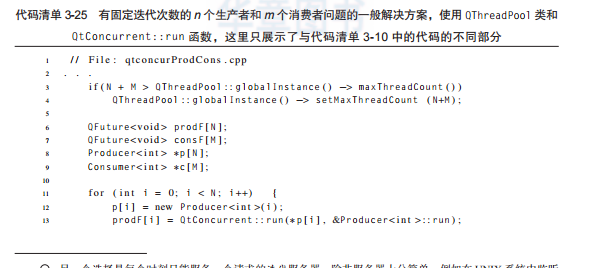

從代碼清單3-25的長度可以看到,為了引入這些新的功能,隻改變了很少的部分。<code>qtconcurrent::run</code>函數也能工作于一個對象的方法上,前提是提供這個對象的引用,以及待調用方法的位址。由于線程是匿名的,是以主線程必須使用<code>qtconcurrent::run</code>的<code>qfuture</code>對象來等待其完成(第22行和第25行)。
第13行和第18行使用的對象引用(p[i]和c[i])意味着調用的方法是常量,亦即它們不改變對象。如果不使用常量方法,對象指針可能按如下方式使用。
關于第13行和第18行中文法的最後一個說明是,在沒有類執行個體的情況下,需要使用位址操作符,否則非靜态函數将不能被引用。
第3行和第4行保證了所有請求的線程都将會開始執行,即使根據qt的标準這一數目是次優的。理想的線程數目是通過<code>qthread::idealthreadcount()</code>方法來估計和設定的,這是設定動态線程數的預設方法。通過<code>qthreadpool::globalinstance()</code>靜态方法獲得一個内部<code>qthreadpool</code>執行個體,可用的線程數目可以修改(第4行)。
需要頻繁生成線程的應用可以通過重用線程來提高性能,亦即使用相同的線程處理不同的任務。這一提高來自記憶體管理子系統需求的減少,這是由于作業系統不需要配置設定和初始化線程執行所需要的所有元件(運作時棧、線程控制塊等)。
為滿足該目的建立的線程池需要能夠滿足以下條件。
1.描述計算任務。
2.計算任務間通信。
3.辨別一個執行任務的線程。
4.通知任務執行的終止。
qt中初始化線程的方法是依照滿足上述幾個條件的原則來設計的:把一個計算任務描述為通過一個供線程執行的單一入口點的類來實作。可以通過定義一個抽象的類來建定接口的類型。
在一個或多個任務生成(生産)線程與執行(消費)它們的線程池間,<code>computationaltask</code>的具體派生類的通信執行個體是生産者–消費者模式一個典型的示例。這一問題可以利用3.5.2節計算數值積分中使用的方式來解決,核心的差別是這裡的目标是執行任意的任務,而不僅僅是單一類型的任務。
第三個和第四個需求可以通過唯一地辨別任務(例如通過任務id)并且強制線程使用相關聯的辨別符訓示執行狀态(即終止)來實作。基于前面的讨論,可以給出一個抽象類,作為送出給線程池的任意任務的基礎類,代碼清單圖3-26所示。
<code>taskid</code>資料成員用于唯一地辨別一個任務,不管它由哪一個線程執行。這看上去與上一節用到的設定(即主線程存儲子線程的引用這一方式)相沖突。
由于真正關心的是送出的任務,是以對一個線程池的引用對于主線程而言沒有意義。在任意時刻一個線程池線程可以執行任意任務(或者變為空閑)。
下面的代碼清單展示了一個基于<code>monitor</code>的自定義線程池類以及其對應的線程類。為了更為清晰地展示,每個代碼清單展示了單個類的代碼。實際的代碼分為兩個檔案:一個頭檔案和一個實作檔案。
<code>customthread</code>類是代碼的基礎架構,包含對<code>customthreadpool</code>單例對象的類級引用。每個類的執行個體獲得一個新的任務(第13~18行),并執行它(第16行),标記其完成狀态(第17行)。<code>customthread</code>執行個體一直執行直到獲得的傳回值是一個空任務的引用,這用來表示程式的終止。
代碼清單3-28中展示的<code>customthreadpool</code>類是一個<code>monitor</code>,它提供兩組方法:一組供任務生産者使用,另一組供線程池線程使用。除了構造函數和析構函數之外,所有的公共線程都開始于對象的加鎖。是以,一組等待條件保證了任務生産者線程将會在任務緩沖區已滿時阻塞,或者線程池線程在任務緩沖區為空時阻塞。
代碼清單3-28 定制的線程池類
一旦<code>customthreadpool</code>的執行個體被建立,建立一組<code>customthread</code>對象,相聯的線程(第40~44行)也會被生成。線程數量預設為16,但是實際的數目可以在類的構造函數中指定。這些線程的引用存儲在t數組中,于是<code>customthreadpool</code>的析構函數可以阻塞,直到完成所有送出的任務(第53~55行)。
<code>customthreadpool</code>對象維護一個循環隊列,儲存所有<code>computationaltask</code>對象。隊列通過下面的方法更新。
<code>schedule</code>:在隊列中存入一個任務引用。如果引用非空,則該任務被配置設定一個唯一的id,該值通過遞增靜态的<code>nexttaskid</code>變量(第73行和第74行)更新。這一id也作為句柄傳回“生産者”線程。
<code>get</code>:從隊列中移除并傳回一個任務引用。
這些方法都包含3.7.1節描述的典型的隊列操作語句。
一旦一個線程池線程完成了一個任務(亦即<code>compute</code>方法傳回),它就通過調用<code>complete</code>方法通知<code>monitor</code>,插入任務id到一個已完成任務集合中(第101行),并且等待一個送出的任務完成的任意“生産者”線程将被喚醒(第102行)。這個集合隻儲存已經完成的但是還未被向其生産者報告為完成任務的id(為了高效率)。任務生成線程可以通過調用<code>waittilldone</code>方法并傳遞任務id作為參數來檢查任務是否已經完成。在finished集合(第109行)中的失敗查找導緻了主調線程的阻塞。
隻有當第109行的條件失敗時,才表示找到了任務id,線程會從集合中删除這一id并傳回(第111行)。
作為應用<code>customthreadpool</code>類的一個執行個體,下面的程式生成一組計算mandelbrot分形集的獨立任務。由于加載操作可以被劃分并配置設定到數目固定的線程上,這并不是一個需要動态生成線程的問題的對策,是以這并不是最合适的示例。
<code>mandelbrot</code>集是複平面上由c=x+iy組成的一個點集,它由一組滿足如下遞歸公式的有界數列z0,z1,z2,…組成:
(3-1)
其中,當ma
著名的ndelbrot分形圖形計算如下,對于複平面上的每個點c,計算使得有界數列分叉的疊代次數n,分叉是指|zn|>2。數字n用于對該點僞着色。顯然,對于mandelbrot集,必須對不分叉的點限制疊代次數。
下面的程式将指令行中指定的複平面劃分為幾個不相交部分,并将其計算配置設定給不同的任務。每個部分都通過其左上角和右下角來辨別。圖3-12展示了任務初始化的方法。需要的參數包括:(a)需要計算的複平面子部分的左上角和右下角以及(b)左上角坐标,需要生成的圖像的像素高度和寬度。
代碼清單3-29展示的程式的關鍵點如下。
需要處理的複平面的子部分(通過第71~74行中提取的指令行參數指定),劃分為xparts*yparts個不相交的部分。對于每個部分,都生成一個獨立的任務(第107行)并且放置到<code>customthreadpool</code>對象隊列中(第108行)。
任務為<code>computationaltask</code>類的子類,即<code>mandelcompute</code>類的執行個體。計算主要集中在<code>compute和diverge</code>方法中。
在建立<code>customthreadpool</code>單例tp(第87行)後,主線程将生成的任務放置到tp的隊列中,并在一個數組中維護傳回的任務id(第108行)。在将生成的圖像存儲到檔案之中前,随後這些id用來檢查任務是否完成(第113~115行)。
一個<code>qimage</code>執行個體用于處理生成的圖像資料,并最終将完整的圖像存儲到檔案中(第118行)。<code>qimage</code>類中的所有方法都是可重入的,亦即可以在多線程中對其進行調用。因為每個線程都被組織為處理<code>qimage</code>對象的不同部分,是以這裡不用考慮競争條件。