本節書摘來自華章出版社《多核與gpu程式設計:工具、方法及實踐》一書中的第2章,第2.5節, 作 者 multicore and gpu programming: an integrated approach[阿聯酋]傑拉西莫斯·巴拉斯(gerassimos barlas) 著,張雲泉 賈海鵬 李士剛 袁良 等譯, 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
一個自然出現的問題是,給定分解模式,如何最好地構造程式?問題的答案高度依賴于具體應用。另外,一些平台給開發者強加了特定的程式結構模式。例如,mpi使用spmd/mpmd模式,而openmp促進循環并行模式。
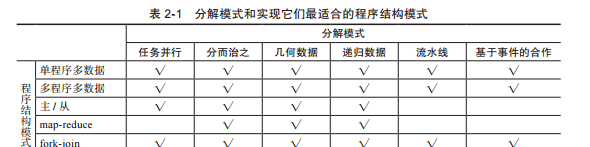
盡管如此,給定一個特定的分解模式,一些特定的程式結構模式更适合實作。表2-1總結了這些配對。
對2.2節的圖像卷積問題執行2d聚集步驟。最終的通信操作數量是多少?
對2.3.3節的熱擴散例子比較1d和2d分解,假設隻有一半的雙向通信連接配接可用,且n端口通信是可行的,即所有連接配接上的所有通信都可以在相同時間發生。
通信開銷如何影響流水線性能?考慮在流水線各級的常數通信開銷,推出式(2.16)~(2.18)的變種。
2.4.5節代碼清單2-8的并行快速排序所計算出的任務數,是基于每次調用partitiondata函數時輸入會均分成兩半這種最優情況假設。如果考慮最差情況(即一部分包括n-1個元素,另一部分包括0個元素),結果會怎樣呢?
使用一個簡單問題執行個體(例如一個小的整型數組)來追蹤代碼清單2-8并行快速排序的執行。對産生的任務建立甘特圖,假設有無限的可用計算節點來執行它們。可以計算出可獲得的加速比上限嗎?
![正運動技術多軸高性能脈沖+總線運動控制器ZMC4321、ZMC432是正運動推出的一款多軸高性能EtherCAT總線運動[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)