本節書摘來自華章出版社《多核與gpu程式設計:工具、方法及實踐》一書中的第2章,第2.4節, 作 者 multicore and gpu programming: an integrated approach[阿聯酋]傑拉西莫斯·巴拉斯(gerassimos barlas) 著,張雲泉 賈海鵬 李士剛 袁良 等譯, 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
模式不僅可以幫助選擇合适的工作負載分解方法,還可用于程式的開發,這正是程式結構模式的目标。接下來的一節将讨論和分析幾個最著名的模式。
并行程式結構模式可以分為兩大類。
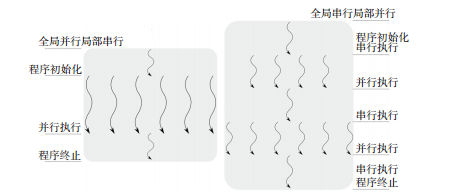
全局并行局部串行(globally parallel locally sequential,gpls):gpls表示應用程式可以并發執行多個任務,每個任務串行執行。這類模式包括:
單程式多資料
多程式多資料
主/從
map-reduce
全局串行局部并行(gslp):gslp表示應用程式串行執行,當需要時,一些單獨的部分可以并行執行。這類模式包括:
fork/join
循環并行
兩種分類的差別在圖2-12的描述中更加明顯。gpls模式更易于提供更高的可擴充性,尤其對于無共享的體系結構。而gslp常用于将串行程式變為并行時,并行的通常是最影響性能的部分。
對單程式多資料(single program multiple data,spmd)模式,執行平台的所有節點都運作相同的程式,但它們或者将相同的操作用于不同資料,或者執行程式中不同的執行路徑。
将所有的應用邏輯儲存在一個程式中促進了更簡單及無故障的開發,使spmd成為受程式員歡迎的選擇。典型的程式結構包括下面的步驟。
程式初始化:這個步驟通常包括将程式部署到并行平台,并初始化負責多線程或程序通信及同步的運作時系統。
擷取唯一的辨別符:辨別符通常從0開始計數,枚舉使用的線程或程序。一些情況下,辨別符可以是向量而不是标量(如cuda)。辨別符生命周期與其辨別的線程或程序一緻。辨別符也可以是持久的,即在整個程式過程中都存在,或者在需要時動态産生。
運作程式:執行與唯一id一緻的執行路徑,這裡可能包括工作負載或資料配置設定、角色多樣化等。
關閉程式:關閉線程或程序,可能需要将部分結果合并産生最終結果。
spmd方法很友善,但也有缺點:所有應用程式的代碼和靜态(即全局)資料都要在所有節點複制。這可能是一個優勢,但當所有上述條目都不需要時,這也會是個不足。
spmd很靈活足,以覆寫大部分的情況,隻有在下列情況下有不足:
若執行平台是易異構的,則需要根據節點的體系結構布局不同的執行檔案。
應用程式記憶體需求非常嚴苛以至于需要降低上載到每個節點的程式邏輯以保證基本的要件。
多程式多資料(mpmd)模式通過允許可能來自于不同工具鍊的不同執行檔案被組合成一個應用程式來覆寫上述情況。每個計算幾點都可以運作自己的程式邏輯處理自己的資料集,但可能仍要遵從前一節識别出的步驟序列。
大部分主要的并行平台都支援mpmd模式,一個特别的例子是cuda,其程式被編譯為單獨的檔案,但實際包含兩種不同的二進制:一個給cpu主機,一個給gpu協處理器。
大部分情況下,隻需要将不同執行檔案映射到合适的計算節點的配置檔案。這種例子将在5.5.2節中展示。
主/從範例将計算節點的任務分為兩種,主節點的職責包括:
将工作發放給從節點
從從節點收集計算結果
代表從節點執行i/o職責,例如給它們發送需要處理的資料或通路一個檔案
與使用者互動
對最簡單的形式,主/從模式隻包含一個主節點和若幹個從節點。然而,這種安排不能随節點數擴充,因為主節點可能成為瓶頸。這種情況可以使用包含多個主節點的階層化方法,每個主節點控制一部分可用機器,對更進階主節點負責。這種安排如圖2-13b所示。
主/從結構概念非常簡單,并能自然地應用到許多問題,前提是總體計算能分解為不需要節點間通信的分離且獨立的片段。一個額外的好處是這種結構能提供隐式的負載均衡,即它将工作負載配置設定給空閑節點,以確定工作配置設定時極少甚至沒有不均衡情況。

工作負載可用多種多樣的方式描述,從最特殊的,如為已知函數的執行提供參數,到最一般的,如提供具有任何種類計算組合的類執行個體。
map-reduce是主/從模式一個流行的衍生物,被google用來運作其搜尋引擎後,從此開始流行起來。map-reduce模式應用程式的運作上下文需要通過應用(映射)一個函數來處理大型獨立資料的集合(易并行)。所有局部計算的結果需要應用另一個函數進行歸約。
map-reduce模式正如google教程[48]所宣傳的,以如圖2-14所示的一般形式工作。使用者程式産生一個主程序監督整個過程,也會産生一些從程序,這些從程序不僅要負責處理輸入資料和中間結果,而且負責合并結果産生最終解答。
在實踐中,執行映射和歸約階段的工作者可以相同,兩種類型從程序之間的資料存儲可以是持久的(如檔案)或暫時的(如記憶體緩沖區)。
map-reduce模式和典型的主/從結構的主要不同在于這種規劃允許使用自動化工具,該工具負責應用程式的部署和負載均衡。apache hadoop項目是使用map-reduce引擎的一個架構。hadoop map-reduce引擎提供兩種類型的程序:jobtracker以及tasktracker,前者等價于圖2-14中的主線程,後者等價于圖2-14中的從線程。這些程序作為系統服務(守護程序)産生。jobtracker負責給tasktracker配置設定任務,并追蹤它們的進度和狀态(例如,如果它們當機,其工作會被排程到其他地方)。每個tasktracker為配置設定的任務維護一個簡單的先進先出(first-in first-out,fifo)隊列,并作為獨立的程序(即單獨的java虛拟機)執行這些任務。
圖2-14 map-reduce模式的一般形式。步驟包括産生主程序和從程序,主程序配置設定任務,由執行映射的從程序輸入資料,儲存局部結果,⑤歸約從程序讀取局部結果,⑥儲存最終結果
并行算法在運作時需要動态建立(fork)任務時可使用fork/join模式。這些子任務(程序或線程)通常需要在父程序或線程恢複執行之前終止(join)。
産生的任務可以通過産生新的線程或程序來運作,或者通過使用存在的線程池來處理它們。後者能最小化建立線程的開銷并可能最優地管理機器程序資源(通過将線程數和可用處理器核數相比對)。
在實際中,一個關于fork/join模式的例子(以并行快速排序算法的實作形式)如下所示:
第6行中的<code>partitiondata</code>函數調用将輸入資料分為兩個部分,一部分包含小于或等于中間點(pivot)的元素的元素,一部分包含大于或等于中間點的元素。pos索引指向中心點的位置,實際上分了兩個部分,分别跨越<code>[0,pos) 和[pos + 1,n)</code>範圍。兩個部分接續着并行排序,一個通過産生一個新任務(第7、8行),一個使用原本的線程或程序(第9行)。隻要被排序的數組大小超過thres,新的任務就會産生。
重申之前闡述的一點,新任務的産生并不需要建立新線程或程序來處理它。如果要排序的數組非常大,這可能是避免災難的秘訣,因為此時很有可能使作業系統崩潰。為了說明這可能産生多大的問題,下面考慮在執行代碼清單2-8所示的并行快速排序時有多少任務會産生。
如果用t(n)表示輸入大小為n時産生的任務總數(去掉第一個,根任務),假設<code>partitiondata</code>函數可以将輸入資料分為兩個相等的部分(最佳情況),則:
(2-25)
反向代入可以解決這個遞推關系。假設n和thres是2的幂,則當時
時以下展開式停止:
(2-26)
将這個k值代入式(2-26),當t(thres) = 0 時得到:
(2-27)
舉例來說,<code>n = 220</code>,<code>thres = 210</code> ,需要<code>210 - 1 = 1023</code>個任務。一個較好的方法是使用線程池執行産生的任務,這種方法在3.8節做了徹底的探讨。
将軟體移植到多核體系結構上是一個艱巨的任務。循環并行模式通過允許開發者移植已有的串行代碼來解決這個問題,移植過程會并行化支配執行時間的循環。
這種模式對openmp平台尤為重要,在這一平台上,在程式員的幫助下,循環半自動地并行化。程式員需要以指令的形式提供提示來幫助完成這個任務。
從提升問題的全新并行解法設計的意義上來說,循環并行模式的可用性有限,該模式注重的是串行到并行解法的演化。這也是性能收益通常較小的原因,但至少需要的開發投入也相應地很小。