本節書摘來自華章出版社《短文本資料了解》一書中的第2章,第2.1節,作者:王仲遠 編著,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
知識庫包含概念、實體、屬性和關系,它在許多應用中的作用日漸突出。本章強調(概念和實體的)屬性知識對推測的重要性,并提出一種為百萬級的概念推導出屬性的方法。該方法将屬性和概念的關系量化為典型性(typicality),使用多個資料源來聚合計算這些典型度得分,這些資料源包括網頁文本、搜尋記錄和現有的知識庫。該方法創新性地将基于概念和實體的模式融合計算典型度得分,大量的實驗證明了該方法的可行性。
建立概念、實體和屬性的知識庫的目的在于賦予機器像人類一樣的推測能力。在推理這個任務中,輸入資料往往稀疏、噪點大且包含歧義。人類能很好地了解這樣的文本是因為人類具備抽象的先驗知識。類似的,知識庫旨在為機器提供這樣的先驗知識,進而使其能夠調用知識來完成思考判斷。可見,知識庫是實作人工智能必不可少的元素。
一個知識庫包含一系列的概念、實體和屬性的關系。在這些關系中,如下三類尤為重要:
. isa:子概念和概念的關系(如it company isa company)。
. isinstanceof:實體和概念的關系(如microsoft isinstanceof company)。
. ispropertyof:屬性和概念的關系(如color ispropertyof wine)。
本章強調屬性和概念的關系(ispropertyof)對基于知識的推測尤其重要。然而,為了完成推斷,機器不僅僅需要了解概念的屬性,還需要知道每個屬性的典型性。本章将重點介紹一種自動擷取屬性并為其打分的方法。該方法的産出為一個大型的資料庫,如表21所示,整個資料庫包含百萬級的概念、屬性以及屬性的得分。這些分數對推測尤為重要,它們被定義為如下的典型度得分。
. p(c|a)表示概念c在屬性a上的典型度。
. p(a|c)表示屬性a在概念c上的典型度。
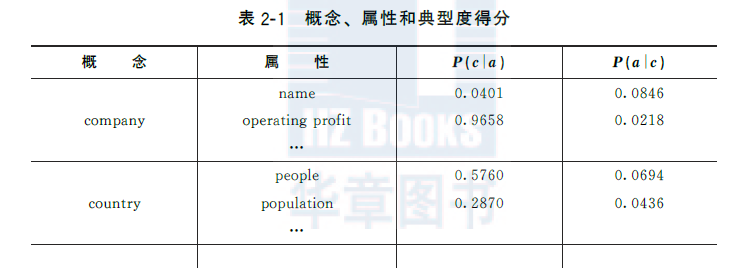
如表2.1所示,company不是name的典型概念,因為很多别的概念都有name這個屬性。相比之下,company更像是operating profit的典型概念。這些典型性被量化為表中的得分:
p(company|operating profit)>p(company|name)
(2.1)
從另一個角度而言,當人們談論一個company時,更傾向于被提到的是它的name,而不是operating profit,是以:
p(operating profit|company)
(2.2)
如表2.1所示,式(2.2)中兩項的典型度得分差異為006,遠小于式(21)中兩項的典型度得分差異09,這與人類的認知一緻。
至此,本章闡述了概念、屬性和典型度得分對基于知識推測的重要性。直覺地,給出短文本
“capital city,population”,人們會聯想到country。給出“color,body,smell”,人們則會聯想到wine。然而在大多數情況下,屬性和概念的關聯并不那麼直覺。以圖21為例,假設在網頁上看到該圖,人們能否很容易地推測出這張表格的标題?
根據單一屬性,如website,人類無法準确推測圖表含義。然而,如圖21所示,當系統看到更多屬性時,它所推測到的候選概念将減少。當圖表呈現出6個或7個屬性時,系統能夠以較高的置信度擷取正确的概念。而典型度得分p(c|a)和p(a|c)在這一過程中扮演着十分重要的角色。

下面是另外一個例子。
the coolpix p7100is announced the powerful lens with 71x zoom offers high resolution(10mp)images
假設讀者不知道coolpix p7100為一款相機,他是否能夠根據語境推測到其講述的是相機呢?也許可以。那麼具有知識庫的機器能否完成相同的推測呢?假設通過自然語言處理技術,lens、zoom、resolution都被标注為知識庫中的屬性詞,且隻有camera和smart phone包含這些屬性。那麼,機器隻需了解機率p(camera|lens;zoom;resolution)大于p(smart phone|lens;zoom;resolution),便可成功完成推
測。換言之,機器需要知道camera是上述屬性更加典型的概念。
通過典型度得分,機器很容易便可完成上述推測。典型度得分的目的在于為屬性尋找最可能的概念。更具體地說,需要找到概念c(,使其滿足
c(=argmaxcp(c|a)
其中a=(lens,zoom,resolution),為一系列屬性。p(c|a)可以用樸素貝葉斯模型得到:
p(c|a)=p(a|c)p(c)p(a)∝p(c)•∏a∈ap(a|c)
至此,該問題被轉化為尋找一系列的典型度得分p(c|a)。
為支援上述的機器推測問題,本章将專注于如下兩個任務:擷取屬性和為屬性打分。這些任務在機率知識庫probase[166,153]上完成。該知識庫包含了大量的概念、實體和isa關系。本章的方法有如下貢獻:
. 該方法創新性地為屬性擷取典型度得分。本章将論證帶有典型度得分的概念和屬性對很多實際應用意義重大。在這項工作中,典型度得分被诠釋為兩個方面:頻率(frequency)和家族相似度(family resemblance),它們将被表示為機率得分。
.該方法在擷取屬性的時候能夠處理歧義。消歧是一項很大的挑戰,且在過往的屬性提取方法中很少被強調。例如,當機器試圖擷取wine的屬性時,它會錯誤地将短文“the mayor of bordeaux”中的“mayor”标注為wine的屬性。事實上,bordeaux一詞包含歧義,它不僅是酒的名字,還指法國西南的一個小城市。本章的工作針對基于實體的屬性提取中的歧義,改進基于概念的屬性提取方法,使其不受歧義的影響。
.該方法從多個來源擷取資料,并使用一種新的排序方法合并這些不同來源的資料。每個資料源和方法都有其獨特特征。例如,name這個屬性可能會被基于概念的屬性提取方法識别,但不能通過基于實體的方法擷取。biography這個屬性則恰恰相反。因而,通過使用不同的方法和資料源有助于得到更加全面的屬性資訊,并幫助解決歧義、噪聲、偏見和覆寫率的局限性。本章将對通過不同資料源提取到的屬性進行比較,并提出一種新的排序算法來合并這些屬性提取的結果。在這一問題上,現有的方法使用了回歸[47]來聚合結果,但需要人為評估确定某些數值。而新提出的排序算法沒有這一需求。
本章結構如下:2.2節介紹為百萬級概念擷取屬性的方法;2.3節闡述為屬性标記權重、聚合權重的方法;本章相關工作的讨論和結論将分别在2.4節和2.5節給出。