本章中,我們将首先學習如何用r語言挖掘頻繁模式、關聯規則及相關規則。然後,我們将使用基準資料評估所有這些方法以便确定頻繁模式和規則的興趣度。本章内容主要涵蓋以下幾個主題:
關聯規則和關聯模式概述
購物籃分析
混合關聯規則挖掘
序列資料挖掘
高性能算法
關聯規則挖掘算法可以從多種資料類型中發現頻繁項集,包括數值資料和分類資料。根據不同的适用環境,關聯規則挖掘算法會略有差異,但大多算法都基于同一個基礎算法,即apriori算法。另一個基礎算法稱為fp-growth算法,與apriori算法類似。大多數的與模式相關的挖掘算法都是來自這些基礎算法。
将找到的頻繁模式作為一個輸入,許多算法用來發現關聯規則或相關規則。每個算法僅僅是基礎算法一個變體。
随着不同領域中的資料集大小和資料類型的增長,提出了一些新的算法,如多階段算法、多重雜湊演算法及有限掃描算法。
資料挖掘的一個最受歡迎的任務就是發現源資料集之間的關系,它從不同的資料源(如購物籃資料、圖資料或流資料)中發現頻繁模式。
為了充分了解關聯規則分析的目的,本章中所有算法均用r語言編寫,這些代碼使用算法的标準r添加包(如arules添加包)進行說明。
在衆多的領域應用中,頻繁模式挖掘經常用于解決各種問題,比如大型購物中心的市場調查可以通過分析購物交易資料來完成。
頻繁模式是經常出現在資料集中的模式。頻繁模式挖掘的資料類型可以是項集、子序列或子結構。是以,頻繁模式也可稱為:
頻繁項集
頻繁子序列
頻繁子結構
接下來的章節将詳細介紹這3種頻繁模式。
當從給定的資料集中發現重複出現的有意義的規則或關系時,這些新發現頻繁模式将作為一個重要的平台。
為了提高挖掘資料集的效率,提出了不同的模式。本章列舉了以下幾種模式,後面将給出它們詳細的定義。
封閉模式
最大模式
近似模式
緊湊模式
判别式頻繁模式
頻繁項集的概念來源于真實的購物籃分析。在諸如亞馬遜等商店中,存在很多的訂單或交易資料。當客戶進行交易時,亞馬遜的購物車中就會包含一些項。商店店主可以通過分析這些大量的購物事務資料,發現顧客經常購買的商品組合。據此,可以簡單地定義零個或多個項的組合為項集。
我們把一項交易稱為一個購物籃,任何購物籃都有組元素。将變量s設定為支援門檻值,我們可以将它和一組元素在所有的購物籃中出現的次數做比較,如果這組元素在所有購物籃中出現的次數不低于s,我們就将這組元素稱為一個頻繁項集。
若一個項集包含有k個項,則該項集稱為k項集,其中k是非零整數。項集x的支援計數記為support_count(x),表示給定資料集中包含項集x的計數。
給定一個預先定義的最小支援度門檻值s,如果support_count(x)≥s,則稱項集x為頻繁項集。最小支援度門檻值s是一個可以自定義的參數,可以根據領域專家或經驗進行調整。
頻繁項集也經常應用于許多領域,如下表所示。
如果某個項集是頻繁的,那麼該項集的任何一個子集也一定是頻繁的。這稱為apriori原理,它是apriori算法的基礎。apriori原理的直接應用就是用來對大量的頻繁項集進行剪枝。
影響頻繁項集數目的一個重要因素是最小支援計數:最小支援計數越小,頻繁項集的數目也越多。
為了優化頻繁項集生成算法,人們提出一些其他概念:
閉項集:給定資料集s,如果y∈s, x y,則support_count (x) ≠ support_count (y),那麼x稱作閉項集。換言之,如果x是頻繁的,則x是頻繁閉項集。
最大頻繁項集:如果y∈s, x y,x是最大頻繁項集,則y是非頻繁的。換言之,y沒有頻繁超集。
限制頻繁項集:若頻繁項集x滿足使用者指定的限制,則x稱為限制頻繁項集。
近似頻繁項集:若項集x隻給出待挖掘資料近似的支援計數,則稱為近似頻繁項集。
top-k頻繁項集:給定資料集s和使用者指定的整數k,若x是前k個頻繁項集,則x稱為top-k頻繁項集。
下面給出一個事務資料集的例子。所有項集僅包含集合d = {ik |{k∈[1,7]}中的項。假定最小支援度計數為3。
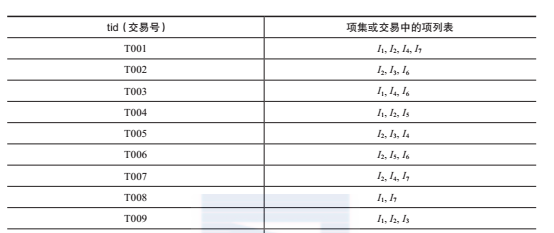
那麼,可以得到頻繁項集l1 = {ik | k∈{1, 2, 4, 6, 7}}和l2 = {{i1, i2},{i1, i4},{i2, i4}}。
頻繁子序列是元素的一個有序清單,其中每個元素包含至少一個事件。一個例子是某網站頁面通路序列,具體而言,它是某個使用者通路不同網頁的順序。下面給出了頻繁子序列的兩個例子。
消費者資料:某些客戶在購物商城連續的購物記錄可作為序列,購買的每個商品作為事件項,使用者一次購買的所有項作為元素或事務。
網頁使用資料:通路www曆史記錄的使用者可作為一個序列,每個ui/頁面作為一個事件或項目,元素或事務定義為使用者通過一次滑鼠的單擊通路的頁面。
序列中包含的項數定義為序列的長度。長度為k的序列定義為k序列。序列的大小定義為序列中項集的數目。當滿足1≤j1≤j2≤…≤jr-1≤jr≤v,且a1bj1, a2bj2, …, arbjr,則稱序列s1=為序列s2=的子序列或s2為s1的超序列。
在某些領域中,研究任務可借助圖論來進行模組化。是以,需要挖掘其中常見的子圖(子樹或子格)。例如:
網絡挖掘:網頁視為圖的頂點,網頁之間的連結視為圖的邊,使用者的頁面通路記錄用來構造圖。
網絡計算:網絡上具有計算能力的任何裝置作為頂點,這些裝置之間的互相連接配接作為邊。由這些裝置和裝置之間的互相連接配接組成的整個網絡視為圖。
語義網絡:xml元素視為頂點,元素之間的父/子關系視為邊。所有的xml檔案可視為圖。
圖g表示為:g = (v, e),其中v表示頂點的集合,e表示邊的集合。當v′v且e′e,圖g′= (v′, e′)稱為g=(v, e)的子圖。下圖給出一個子圖的例子。圖中,左邊是原始圖及其包含的頂點和邊,右邊是删除多條邊(或删除多個頂點)後的子圖。

基于已發現的頻繁模式,可以挖掘關聯規則。根據關系的興趣度的不同側重點,可以進一步研究以下兩種類型的關系:關聯規則和相關規則。
關聯分析可以從海量資料集中發現有意義的關系,這種關系可以表示成關聯規則的形式或頻繁項集的形式。具體的關聯分析算法将在後面一個章節中給出。
關聯規則挖掘旨在發現給定資料集(事務資料集或其他序列-模式-類型資料集)中的結果規則集合。給定預先定義的最小支援度計數s和置信度c,給定已發現的規則x→y support_count (x→y)≥s且confidence (x→y)≥c。
當x∩y=(x、y不相交),則x→y是關聯規則。規則的興趣度通過支援度(support)和置信度(confidence)來測量。支援度表示資料集中規則出現的頻率,而置信度測量在x出現的前提下,y出現的可能性。
對于關聯規則,衡量規則可用性的核心度量是規則的支援度和置信度。兩者之間的關系是:
support_count(x)是資料集中包含x的項集數。
通常,在support_count(x)中,支援度和置信度的值表示為0~100的百分數。
給定最小支援度門檻值s和最小置信度門檻值c。如果support_count (x→y) > s且confidence (x→y)≥c,則關聯規則x→y稱為強規則。
對于關聯規則含義的解釋應當慎重,尤其是當不能确定地判斷規則是否意味着因果關系時。它隻說明規則的前件和後件同時發生。以下是可能遇到不同種類的規則:
布爾關聯規則:若規則包含項出現的關聯關系,則稱為布爾關聯規則。
單維關聯規則:若規則最多包含一個次元,則為單維關聯規則。
多元關聯規則:若規則至少涉及兩個次元,則為多元關聯規則。
相關關聯規則:若關系或規則是通過統計相關進行測量的,滿足給定的相關
性規則,則稱為相關關聯規則。
定量關聯規則:若規則中至少一個項或屬性是定量的,則稱為定量關聯規則。
在某些情況下,僅僅憑借支援度和置信度不足以過濾掉那些無意義的關聯規則。此時,需要利用支援計數、置信度和相關性對關聯規則進行篩選。
計算關聯規則的相關性有很多方法,如卡方分析、全置信度分析、餘弦分析等。對于k項集x={i1, i2 …, ik},x的全置信度值定義為: