實時計算任意資料集上的任意函數,是一個令人望而卻步的問題。沒有單獨的工具可以提供完整的解決方案,相反,你必須使用各種工具和技術建構一個完整的大資料系統。
lambda架構的主要思想是将大資料系統建立為一系列的層,如圖1-6所示。每一層滿足屬性的一個子集,且通過該層的下一層所提供的功能來建構。雖然你通過整本書來學習如何設計、實作和部署每一層,但整個系統是如何有機結合在一起的高層思想是很容易了解的。
一切從query = function(all data)等式開始。理想情況下,你可以不斷運作這個函數來擷取結果。不幸的是,即使這是可能的,也需要占用大量的資源,并且相當昂貴。想象一下,每次你想要響應某人目前位置的查詢時,都必須要讀取1pb的資料集。
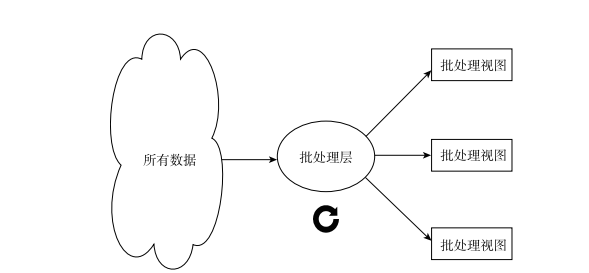
最顯而易見的替代方法是預先計算查詢函數。我們将預先計算的查詢函數稱為批處理視圖(batch view)。這不是動态計算查詢,而是從預先計算好的視圖中讀取結果。預先計算的視圖是有索引的,是以可以用随機讀取的方式進行通路。該系統看起來像是這樣的:
在該系統中,你在所有資料上運作一個函數來擷取批處理視圖。然後,當你想知道一個查詢的值時,隻需針對批處理視圖運作一個函數即可。批處理視圖可以使你很快地從中獲得所需要的值,而無須掃描所有資料。
這個讨論有點抽象,下面舉例說明。假設你正在建構一個網絡分析的應用程式(再次建構),并且想要查詢任一範圍天數内某個url的頁面浏覽量。如果你在所有資料上運作該查詢函數,最好掃描資料集中相應時間範圍内那個url的頁面浏覽量,并傳回結果的計數。
批處理視圖方法替代在所有頁面浏覽上運作一個函數的方式,來預先計算[url,day]鍵的索引,以獲得某天某個url頁面浏覽的計數。然後為了解決該查詢,從視圖中檢索相應時間範圍内的所有天的值,并将所有計數相加,以得到最終的結果。這種方法如圖1-7所示。
應該明确的是,到目前為止所描述的這種方法似乎缺了點什麼。建立批處理視圖顯然會是一個高延遲操作,因為它是在你的所有資料上運作一個函數。在批處理視圖結束時,很多新的資料将被收集但是沒有展示在批處理視圖中,并且這個查詢将過期許多小時。但是我們暫時忽略這個問題,因為它是可以解決的。假設過期幾個小時的查詢是可以的,那麼我們繼續探索通過在完整資料集上運作函數來預先計算批處理視圖的這個想法。
1.7.1 批處理層
lambda架構中實作batch view = function(alldata)等式的這部分被稱為批處理層。批處理層存儲資料集的主副本,并在主資料集上預先計算批處理視圖(見圖1-8)。

主資料集可以被視作一個非常大的記錄清單。
批處理層需要能夠做兩件事:存儲不可變的、不斷增長的主資料集;在該資料集上運作任意函數。最好使用批處理系統完成這種類型的處理。hadoop是批處理系統的一個典型例子,我們将在本書中使用hadoop來闡述批處理層的概念。
批處理層最簡單的形式可以用如下的僞代碼表示:
批處理層在while(true)中循環運作,不斷從頭開始重新計算批處理視圖。實際上,批處理層的功能并不僅限于此,相關内容會在本書後續章節予以介紹。這裡隻探讨批處理層的最好方式。
批處理層的優點是,使用起來很簡單。批處理計算可以編寫成例如單線程的程式,并且你可以毫不費力地擷取并行性。很容易在批處理層編寫魯棒性好的、高度可擴充的計算。批處理層可通過添加新機器進行擴充。
下面是批處理層計算的一個例子。不要擔心對代碼的了解問題—重點是展示一個天生具備并行性的程式是什麼樣子的:
這段代碼把給定的原始頁面浏覽的資料集作為輸入,為每個url計算頁面浏覽量。這段代碼的有趣之處在于—排程工作的所有并行性挑戰和結果的合并都已經為你做好了。由于算法是用這種方式寫的,是以它可以任意地分布在mapreduce叢集中,擴充到可用的不管多少數量的節點上。在計算結束時,輸出目錄将包含一些結果檔案。本書第7章将介紹如何編寫這樣的程式。
批處理層的功能是生成批處理視圖。下一步是在某個地方加載視圖,以便它們可以被查詢到—這個地方就是服務層。服務層(serving layer)是一個專用的分布式資料庫,用于加載批處理視圖,并可以對它進行随機讀取(見圖1-9)。當新的批處理視圖可用時,服務層會自動替換那些視圖,這樣更多的最新結果就是可用的了。
服務層資料庫支援批處理更新和随機讀取。最值得注意的是,它不需要支援随機寫操作—這是非常重要的一點,因為随機寫會在資料庫中導緻絕大多數的複雜性—因為不支援随機寫,是以這些資料庫非常簡單。簡單性使得它們是可預測的、魯棒性好的,易于配置,且操作簡單。elephantdb是你将在本書中學習使用的服務層資料庫,它隻有幾千行代碼。
批處理層和服務層支援對任意資料集上的任意查詢,當然是以查詢将過期幾個小時為代價的。一個新的資料片段從批處理層傳播到可以被查詢到的服務層,需要花費幾個小時。需要注意的是,除了低延遲更新,批處理層和服務層滿足了大資料系統所需的每個屬性(參見1.5節)。讓我們依次檢查一遍:
魯棒性和容錯性—當機器發生故障時,hadoop處理故障轉移。服務層在内部使用副本機制,確定伺服器當機時的可用性。批處理層和服務層也是可以容忍人為錯誤的,因為一旦出錯,你可以修複算法或删除壞資料,并從頭開始重新計算視圖。
可擴充性—批處理層和服務層均易于擴充。它們都是完全的分布式系統,擴充它們就像添加新機器一樣容易。
通用性—這裡描述的架構非常通用。你可以計算和更新任意資料集的任意視圖。
延展性—添加一個新的視圖就像對主資料集添加一個新函數一樣容易。由于主資料集可以包含任意資料,是以新類型的資料可以很容易地被添加進來。如果想微調一個視圖,你不必擔心支援應用程式中多個版本的視圖。你可以簡單地從頭開始重新計算整個視圖。
即席查詢—批處理層支援即席查詢。在某個位置,所有資料都是友善可用的。
最少維護—維護這個系統的主要元件是hadoop。hadoop需要一些管理知識,但操作起來相當簡單。正如前面所解釋的那樣,服務層資料庫是很簡單的,因為它們不進行随機寫操作。因為服務層資料庫有很少的活動部件,出錯的可能性不大。是以,服務層資料庫不太可能出錯,進而更容易維護。
可調試性—在批處理層運作時,你永遠都有計算的輸入和輸出。在傳統資料庫中,一個輸出可以替換原來的輸入—比如遞增一個值時。在批處理層和服務層,輸入是主資料集,輸出是視圖。同樣,所有中間步驟都有輸入和輸出。當出錯時,輸入和輸出可以給出調試所需要的所有資訊。
批處理層和服務層之美在于它們用一個簡單且易于了解的方法滿足了幾乎所有你想要的屬性—沒有并發問題要處理,擴充非常簡單。唯一沒有滿足的屬性是低延遲更新。在最後一層,速度層,會解決這個問題。
一旦批處理層完成預先計算批處理視圖,服務層即進行更新。這意味着唯一沒有在批處理視圖中展示的資料是運作預先計算期間新來的資料。為了實作一個完全的實時資料系統,剩下的任務要完成—也就是說,為了實時在任意資料上執行任意函數計算—彌補最後幾個小時的那些資料。這是速度層的目的。顧名思義,它的目标是確定新的資料按照應用程式的需求盡快展示在查詢函數中(見圖1-10)。
你可以認為速度層是類似于批處理層的,它基于接收到的資料生成視圖。兩者之間一個很大的差別是,速度層隻檢視最近的資料,而批處理層要立即檢視所有資料。另一個很大的差別是,為達到最小延遲的可能,速度層不會立即檢視所有新資料。相反,每當接收到新的資料,它就更新實時視圖,而不是像批處理層從頭開始重新計算視圖。速度層做增量計算,而不是像批處理層那樣進行重新計算。
我們可以将速度層上的資料流格式化成以下等式:
realtime view = function ( realtime view, new data)
實時視圖基于新資料和現有的實時視圖進行更新。
lambda架構總體被總結為以下三個等式:
這些想法的圖解如圖1-11所示。也就是說,不是隻需要對批處理視圖運作一個函數就可以得到查詢,而是需要通過檢視批處理視圖和實時視圖并将結果合并在一起,才能得到查詢。
速度層使用支援随機讀取和随機寫入的資料庫。因為這些資料庫支援随機寫,是以它們比在服務層使用的資料庫要高出幾個數量級的複雜性,無論是實作方面還是操作方面。
lambda架構之美在于,一旦資料通過批處理層到服務層,實時視圖中相應的結果就不再需要了。這意味着你可以丢棄不再需要的實時視圖。這是一個很好的結果,因為速度層遠比批處理層和服務層更複雜。lambda架構的這個屬性被稱為複雜性隔離,這意味着複雜性被推入一個隻存儲暫時結果的層中。如果有什麼差錯,你可以丢棄整個速度層的狀态,并且在幾小時内使一切恢複正常。
下面繼續建構網絡分析應用程式的例子—它支援一些天當中頁面浏覽量的查詢。請回顧一下批處理層從[url,day]到頁面浏覽量所生成的批處理視圖。
速度層儲存自己獨立的[url,day]到頁面浏覽量的視圖。而批處理層通過逐次計算頁面浏覽,重新計算批處理視圖。每當接收到新資料,速度層就通過增加在視圖中的計數值來更新自己的視圖。為解決一個查詢過程,你需要查詢所需的批處理視圖和實時視圖,來滿足指定的日期範圍,并将結果相加以得到最終計數。還有一項需要去做的工作,就是恰當地同步結果(相應内容将在本書後續的章節中介紹)。
一些算法很難增量地計算。批處理/速度層的分離,為你在批處理層上使用精确算法和速度層上使用近似算法提供了足夠的靈活性。批處理層多次重寫速度層,是以近似值得到修正,并且系統也顯示了最終準确性的屬性。例如計算獨立計數,如果獨立值的集合很大,這可能是很有挑戰性的。很容易在批處理層完成獨立值計數,因為你能立即看到所有資料,但在速度層你可以将hyperloglog集合作為一個近似值使用。
最終,性能和魯棒性兼得。因為批處理層糾正在速度層中的計算,是以在批處理層做準确計算且在速度層做近似計算的系統,呈現了最終的準确性。你得到的仍然是低延遲更新,但由于速度層是暫時的,實作該屬性的複雜性并不會影響結果的魯棒性。當涉及性能折中方案時,速度層的暫時特性給你提供了極大的靈活性。當然,因為用增量方式完成的計算是準确的,是以該系統是完全準确的。