本節書摘來自華章出版社《雲資料管理:挑戰與機遇》一書中的第一章,第1節,作者[美] 迪衛艾肯特·阿格拉沃爾(divyakant agrawal) 蘇迪皮托·達斯(sudipto das)阿姆魯·埃爾·阿巴迪(amr el abbadi) 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
<b>‖第1章</b>
簡 介
當代技術的快速發展導緻大規模資料中心(也稱為雲)中的使用者應用、服務和資料的數量急劇增加。雲計算已經使得計算基礎設施商品化,就像日常生活中的許多其他實用工具一樣,并且大大減少了創新型應用及其大規模部署之間的基礎設施障礙,進而可以支援分布在世界各地的大規模使用者。在雲計算出現之前,對一個擁有大規模使用者群的新應用的市場驗證,往往需要在計算基礎設施方面進行大規模前期投資才能使得應用可用。由于雲基礎設施的即用即付收費機制和彈性特征,即根據工作負載動态地增加或減少伺服器數量,大部分基礎設施風險都轉移到了雲基礎設施提供商身上,進而使得一個應用或服務能夠支援全球範圍内的使用者,影響更多人。例如foursquare、instagram、pinterest以及很多其他應用,在全世界範圍内有數百萬使用者通路,正是雲計算基礎設施才使得如此大規模的部署成為可能。
雖然雲平台簡化了應用程式的部署,但是服務提供商面臨着前所未有的技術和研究挑戰,即,開發以伺服器為中心的應用程式平台,能夠實作無限數量使用者的7×24小時的網絡通路。過去10年,很多技術領先的網絡服務提供商(如google、amazon和ebay)積累的經驗表明,雲環境下的應用程式基礎設施必須滿足高可靠性、高可用性和高可擴充性。可靠性是確定一個服務能夠連續通路的關鍵。同樣,可用性是指一個給定系統能夠正常工作的時間百分比。可擴充性需求代表系統處理逐漸增加的負載的能力,或者随着額外資源的增加(尤其是硬體資源),系統提高吞吐量的能力。可擴充性既是雲計算環境下的關鍵要求,同時也是一個重大挑戰。
一般來說,一個計算系統的硬體增加以後,如果其性能能夠随增加的資源成比例提高的話,該系統就是一個可擴充的系統。系統有兩種典型的硬體擴充方式。第一種方式是垂直擴充(vertically,或稱scale-up),垂直擴充是指增加單個伺服器的資源,或者用功能更強大的伺服器進行替換,一般涉及更多的處理器、記憶體和伺服器有更強的i/o能力。垂直擴充能夠有效地為現有的作業系統和應用子產品提供更多的資源,但是需要對硬體進行替換。此外,一旦超過一定規模以後,伺服器能力的線性增加會導緻開銷的超線性增加,進而導緻基礎設施代價大幅度增加。另外一種系統擴充方式是水準增加硬體資源,又稱為橫向擴充(horizontally,或稱水準擴充,scale-out)。水準擴充意味着無縫地增加更多的伺服器,并進行工作負載的配置設定。新伺服器可以逐漸添加到系統當中,這樣可以保證基礎設施的開銷(幾乎)是線性增加的,進而可以很經濟地建構大規模的計算基礎設施。但是,水準擴充需要高效的軟體方法來無縫地管理這些分布式系統。
随着伺服器價格的下降以及性能需求的不斷增加,可以用低成本的系統來建構大規模的計算基礎設施,部署高性能的應用系統,如網絡搜尋和其他基于網絡的服務。可以用數百台普通伺服器建構一個叢集系統,其計算能力往往可以超過很多強大的超級電腦。這種模型也得益于高性能連接配接器的出現。水準擴充模型還促使對高i/o性能的共享資料中心的需求日益增加,這種資料中心也是大規模資料處理所需要的。除了硬體和基礎設施的上述發展趨勢外,虛拟化(virtualization)也為大規模基礎設施的共享提供了優雅的解決方案,包括對單個伺服器的共享。水準擴充模式是當今大規模資料中心的基礎,構成了雲計算的關鍵基礎設施。谷歌、亞馬遜和微軟等技術引領者都證明,由于很多應用能夠共享相同的基礎設施,是以資料中心能夠帶來前所未有的規模效應。這3家公司不僅對公司内部的應用實作共享,同時還在各自的資料中心中提供amazon web services(aws)、google appengine和microsoft azure等架構來為第三方應用提供服務,這樣的資料中心稱為公有雲。
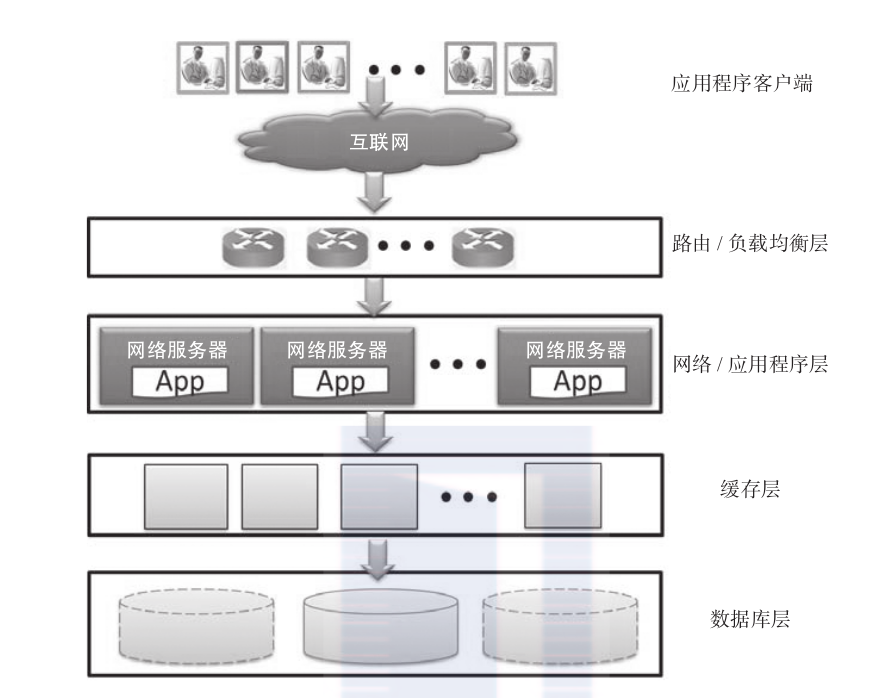
圖1-1展示了部署在雲基礎設施中的網絡應用的軟體棧示意圖。應用程式用戶端通過網際網路連接配接到應用程式(或服務)。應用程式接口往往是通過應用程式網關或者負載均衡伺服器來把請求路由到網絡和應用伺服器層的相應伺服器上。網絡層主要負責處理通路請求并對應用邏輯進行封裝。為了加快通路速度,頻繁通路的資料一般都存儲在由多個伺服器構成的緩沖層上。這種類型的緩沖一般是分布式的,并且由應用層來負責顯式管理。應用程式的持久化資料存儲在一個或多個資料庫伺服器中(這些伺服器組成資料庫層)。存儲在資料庫管理系統(dbms)中的資料構成了基準資料,即應用程式正常操作所依賴的資料。部署在大規模雲基礎設施中的大部分應用程式都是資料驅動的。資料和資料庫管理系統在整個雲軟體棧中都是不可或缺的組成部分。由于資料管理系統是整個軟體棧中的重要組成部分,是以資料往往被複制多份(參見圖中的虛線部分)。這種複制機制在一個dbms伺服器當機的情況下也能夠提供高可用性。另外一個挑戰是如何應對日益增長的資料量和通路請求。本書将主要關注雲軟體棧的資料庫層設計中面臨的諸多挑戰。
雲計算領域中資料庫管理系統廣泛使用的主要原因在于dbms的成功,尤其是關系型資料庫管理系統(rdbms)的巨大成功能夠滿足不同類型應用程式在資料模組化、存儲、檢索和查詢方面的要求。dbms成功的關鍵因素在于其所具備的諸多特性:完善的功能(用簡單、直覺的關系模型對不同類型應用程式進行模組化),一緻性(能有效地處理并發負載并保持同步),性能(高吞吐、低延遲和超過25年的工程應用經曆),以及可靠性(在各種失效情況下確定資料的安全性和持久性)。
雖然取得了巨大的成功,但是在過去10年間人們一直認為dbms和rdbms并不适合雲計算。主要原因在于,和雲服務中的網絡伺服器、應用程式伺服器等元件不同(網絡伺服器、應用程式伺服器可以很容易從少數伺服器擴充到成百上千甚至上萬台伺服器),dbms不容易擴充。實際上,現有的dbms技術無法提供足夠的工具和方法來對一個現有資料庫部署進行橫向擴充(從幾台機器擴充為很多機器)。
在雲計算平台中確定基于web的應用程式具有可擴充性的基本要求是能夠支援無限數量的終端使用者。因為系統的可擴充性僅能保證系統能夠擴充到更多的伺服器或使用者請求,是以可擴充性隻是一個靜态屬性。即,可擴充性無法確定系統的規模能随着使用者負載的浮動而動态變化。相反,系統彈性則是動态屬性,因為彈性允許系統在不當機的情況下通過增加伺服器進行動态擴充或者通過減少伺服器縮減規模。彈性是系統的一個重要屬性,其得益于底層雲基礎設施的彈性。
為了能夠水準擴充到數千台伺服器、具備彈性、可以跨越多個地理區域和具備高可用性,很多技術引領者都開發了具有自主知識産權的資料管理技術。從曆史來看,由于需求的巨大不同,資料管理任務往往被寬泛地分成兩大類。第一類是線上事務處理(oltp),或者是資料服務負載(主要側重于短小、簡單的讀/寫操作或事務)。另一類是決策支援系統(dss),或者稱為資料分析負載(主要側重于長時間的、隻讀的、複雜的分析處理操作)。兩類不同的任務負載對系統有不同的要求,針對每種工作負載,曆史上出現不同的系統架構。是以,為了應對不同種類的工作負載,兩種技術路線共同得以發展。本書主要關注前一個問題(oltp)在雲環境下是如何解決的。分析處理也得到了雲資料管理的重要推動,并且産生了很多重要的技術和系統。尤其是谷歌公司提出的mapreduce程式設計模型[dean and ghemawat, 2004],該程式設計模型适合用來在計算機叢集中對大規模資料集進行分析。簡單來說,mapreduce模式對大規模資料集進行劃分,并把每一塊映射到不同的伺服器上。每個伺服器負責處理一小塊資料,并把處理結果傳到一個reducer上,reducer負責收集來自不同mapper的所有結果,并對這些結果進行合并得到最終的輸出結果。由于谷歌公司的廣泛推廣以及開源系統hadoop[apache hadoop]的大受歡迎,mapreduce模式成為雲時代最受關注的新興技術。然而關于mapreduce和rdbms的争論一直不斷[dean and
ghemawat,2010,stonebraker et al.,2010],廣泛深入的研究也促進了mapreduce和基于hadoop的分析平台的快速發展。本書的剩餘章節将主要關注雲環境的資料服務系統。
早期開發的可擴充的資料服務系統是一類稱為“鍵–值存儲”的系統。bigtable [chang et al., 2006]、dynamo [decandia et al.,2007]和pnuts [cooper et al., 2008]等系統起到了引領作用,緊接着一系列開源系統湧現出來,這些開源系統或者是複制了這些内部(in-house)系統的設計思想,或者是受到這些内部系統的啟發。鍵–值存儲系統與rdbms的主要差別在于,傳統rdms資料庫中的所有資料都被視為是一個整體,dbms的主要職責是確定所有資料的一緻性。然而,在鍵–值存儲系統中,這種關系被分隔成主鍵和其相關的值,鍵–值對被視為獨立的資料單元或資訊單元。應用程式的原子性和一緻性以及使用者通路僅僅在單個主鍵級别得以保證。這種細粒度的一緻性允許鍵–值存儲系統對資料庫進行水準擴充,很友善地把資料從一台機器遷移到其他機器,能夠把資料分布到數千台伺服器上,同時能避免繁重的分布式同步,在部分資料不可用的情況仍然能夠繼續為使用者提供服務。此外,鍵–值存儲系統設計的目的是具有彈性,而傳統的dbms一般是用于具有靜态配置的企業基礎設施,其主要目的是對于給定的硬體和伺服器設施實作最高的性能。
所有最初的内部系統都是根據良好的需求而定制的,能夠适應特定應用的特點。例如,bigtable主要是用來進行索引結構的建立和維護,進而為谷歌搜尋引擎服務。同樣,dynamo的設計初衷是為亞馬遜電子商務網站的購物籃服務,雅虎的社交屬性促使了pnuts的誕生。是以,雖然這些系統都屬于鍵–值存儲系統,但是每個系統也都有自己的獨特設計。在本書後面的内容中,我們将詳細分析每一個系統,進而了解這些設計原則及其權衡。然而,可擴充性、系統彈性和高可用性等關鍵特點使得這些系統在各自的應用領域大受歡迎,在其他領域,hbase、cassandra、voldemort及其他開源系統也得到了廣泛使用。鍵–值系統的廣泛使用也預示着nosql運動的到來[nosql]。雖然單個鍵–值對粒度的原子性和一緻性已經能夠滿足實際應用的需求,但是在很多其他應用場景下這種通路模式還遠遠無法滿足實際要求。在這種情況下,需要由應用程式開發者來保證多個資料的原子性和一緻性。這就導緻在不同的應用棧中重複使用多實體同步機制。針對多個資料的通路控制的實作機制在很多開發者部落格[obasanjo,2009]及相關論壇中都有所讨論[agrawal
et al.,2010,dean,2010,hamilton,2010]。
總體來說,所面臨的關鍵挑戰是如何在保證較高性能、可擴充性和系統彈性的同時實作針對資料庫中多個資料片段通路的原子性。是以,在大規模資料中心中也要支援經典的事務[eswaran et al.,1976,gray,1978]概念。分布式事務已經有很多研究成果[通常是伺服器的大叢集)性能。這些基本的設計原則和各種設計方案是本書剩餘章節的主要讨論内容。特别是我們會分析各種各樣的系統和方法,其中有些是學術中的原型系統,有些是工業級的産品。這些方法經常利用一些巧妙的特性和應用程式的通路模式,或者對提供給應用層的功能加以限制。關鍵挑戰在于如何在增強鍵–值存儲系統功能的同時不降低系統性能、彈性和可擴充性。實際上,雲平台成功的主要原因在于其能夠在雲環境下保證資料管理的簡潔性、可擴充性、一緻性和系統彈性。
把dbms擴充到具有大規模并發通路使用者的大型應用尚存在一些挑戰,很多雲平台在為大量小規模應用提供服務時也面臨諸多挑戰。例如,microsoft windows azure、google appengine和salesforce.com等雲平台一般都要為成千上萬個應用提供服務,但是大部分應用可能隻占用一小部分存儲空間,并發請求的數量也隻占整個雲平台的很小比例。關鍵的挑戰在于如何以一種高成本效益的方式來為這些應用提供服務。這就導緻了多租戶技術的出現,多個租戶可以共享資源并在一個系統中共存。多租戶資料庫已經成為雲平台軟體棧中重要且關鍵的組成部分。這些租戶資料庫一般不是很大,是以可以在單個伺服器中運作。是以,dbms的全部功能都可以得到實作,包括sql操作和事務。然而,系統彈性、資源的有效共享和大量小租戶的統一管理等問題也非常重要。為了滿足這些需求,在資料庫層已經産生了多種虛拟化方法。硬體和系統軟體的虛拟化主要用于對大規模資料中心基礎設施進行共享和管理。然而,資料庫内部的虛拟化可以支援和隔離多個獨立的租戶資料庫,該技術引起了資料庫學術界和工業界的廣泛關注。本書後面的部分将主要讨論設計靈活的多租戶資料庫系統面臨的諸多挑戰。
雲計算和大規模資料中心的資料管理主要建立在基礎的計算機科學研究之上,包括分布式系統和資料庫管理。第2章中,我們主要提供分布式計算和資料庫的一些基本背景資料,尤其是分布式資料庫。第2章中涉及的很多主題都非常重要,有助于了解後面章節中的一些進階概念。但是對這些領域的文獻資料比較熟悉的讀者可以直接跳到第3章,第3章介紹雲環境下關于資料管理的早期研究工作,特别介紹了基本的技術發展趨勢以及取得的經驗教訓,并對一些特定的系統進行了重點講述。接下來讨論了如何在雲環境下支援原子操作(事務)。第4章讨論了一些新的嘗試,試圖将所需要的資料托管到一個地方,這樣就可以避免複雜的分布式同步協定,也能夠確定通路操作的原子性。第5章針對分布式事務和跨站點甚至跨資料中心的資料通路提供了通用的解決方案。第6章讨論多租戶的問題,并對雲環境下的實時遷移方法進行了探讨。第7章對相關經驗教訓進行了總結,并指出了未來的研究方案。
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)