kafka 作為 high throughput 的消息中間件,以其性能,簡單和穩定性,成為目前實時流處理架構中的主流的基礎元件。
當然在使用 kafka 中也碰到不少問題,尤其是 failover 的問題,常常給大家帶來不少困擾和麻煩。
是以在梳理完 kafka 源碼的基礎上,盡量用通俗易懂的方式,把 kafka 發生 failover 時的機制解釋清楚,讓大家在使用和運維中,做到心中有數。
這裡讨論 kafka 的 failover 的前提是在0.8版本後, kafka 提供了 replica 機制。
對于0.7版本不存在 failover 的說法,因為任意一個 broker dead 都會導緻上面的資料不可讀,進而導緻服務中斷。
下面簡單的介紹一下 0.8中加入的 replica 機制和相應的元件,
基本思想大同小異,如下圖 (ref.2):
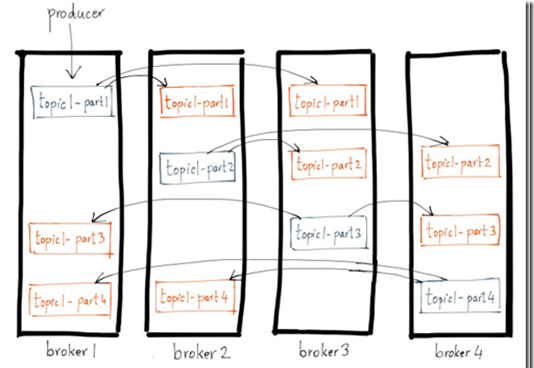
圖中有4個 kafka brokers,并且topic1有四個 partition(用藍色表示)分布在4個 brokers 上,為 leader replica;
且每個 partition 都有兩個 follower replicas(用橘色表示),分布在和 leader replica 不同的 brokers。
這個配置設定算法很簡單,有興趣的可以參考kafka的design。
為了支援replica機制,主要增加的兩個元件是,replica manager和controller, 如下圖:

每個 broker server 都會建立一個 replica manager,所有的資料的讀寫都需要經過它 ,
0.7版本,kafka 會直接從 logmanager 中讀資料,但在增加 replica 機制後,隻有 leader replica 可以響應資料的讀寫請求 。
是以,replica manager 需要管理所有 partition 的 replica 狀态,并響應讀寫請求,以及其他和 replica 相關的操作。
大家可以看到,每個 partition 都有一個 leader replica,和若幹的 follower replica,那麼誰來決定誰是leader?
你說有 zookeeper,但用 zk 為每個 partition 做 elect,效率太低,而且 zk 會不堪重負;
是以現在的通用做法是,隻用 zk 選一個 master 節點,然後由這個 master 節點來做其他的所有仲裁工作。
kafka 的做法就是在 brokers 中選出一個作為 controller,來做為 master 節點,進而仲裁所有的 partition 的 leader 選舉。
下面我們會從如下幾個方面來解釋 failover 機制,
先從 client 的角度看看當 kafka 發生 failover 時,資料一緻性問題。
然後從 kafka 的各個重要元件,zookeeper,broker, controller 發生 failover 會造成什麼樣的影響?
最後給出一些判斷 kafka 狀态的 tips。
除了要打開 replica 機制,還取決于 produce 的 request.required.acks 的設定,
acks = 0,發就發了,不需要 ack,無論成功與否 ;
acks = 1,當寫 leader replica 成功後就傳回,其他的 replica 都是通過fetcher去異步更新的,當然這樣會有資料丢失的風險,如果leader的資料沒有來得及同步,leader挂了,那麼會丢失資料;
acks = –1, 要等待所有的replicas都成功後,才能傳回;這種純同步寫的延遲會比較高。
是以,一般的情況下,thoughput 優先,設成1,在極端情況下,是有可能丢失資料的;
如果可以接受較長的寫延遲,可以選擇将 acks 設為 –1。
首先無論是 high-level 或 low-level consumer,我們要知道他是怎麼從 kafka 讀資料的?
kafka 的 log patition 存在檔案中,并以 offset 作為索引,是以 consumer 需要對于每個 partition 記錄上次讀到的 offset (high-level和low-level的差別在于是 kafka 幫你記,還是你自己記);
是以如果 consumer dead,重新開機後隻需要繼續從上次的 offset 開始讀,那就不會有不一緻的問題。
但如果是 kafka broker dead,并發生 partition leader 切換,如何保證在新的 leader 上這個 offset 仍然有效?
kafka 用一種機制,即 committed offset,來保證這種一緻性,如下圖(ref.2)
log 除了有 log end offset 來表示 log 的末端,還有一個 committed offset, 表示有效的 offset;
committed offset 隻有在所有 replica 都同步完該 offset 後,才會被置為該offset;
是以圖中 committed 置為2, 因為 broker3 上的 replica 還沒有完成 offset 3 的同步;
是以這時,offset 3 的 message 對 consumer 是不可見的,consumer最多隻能讀到 offset 2。
如果此時,leader dead,無論哪個 follower 重新選舉成 leader,都不會影響資料的一緻性,因為consumer可見的offset最多為2,而這個offset在所有的replica上都是一緻的。
是以在一般正常情況下,當 kafka 發生 failover 的時候,consumer 是不會讀到不一緻資料的。特例的情況就是,目前 leader 是唯一有效的 replica,其他replica都處在完全不同步狀态,這樣發生 leader 切換,一定是會丢資料的,并會發生 offset 不一緻。
kafka 首先對于 zookeeper 是強依賴,是以 zookeeper 發生異常時,會對資料造成如何的影響?
如果 zookeeper dead,broker 是無法啟動的,報如下的異常:
這種異常,有可能是 zookeeper dead,也有可能是網絡不通,總之就是連不上 zookeeper。
這種 case,kafka完全不工作,直到可以連上 zookeeper 為止。
其實上面這種情況比較簡單,比較麻煩的是 zookeeper hang,可以說 kafka 的80%以上問題都是由于這個原因
zookeeper hang 的原因有很多,主要是 zk 負載過重,zk 所在主機 cpu,memeory 或網絡資源不夠等
zookeeper hang 帶來的主要問題就是 session timeout,這樣會觸發如下的問題,
a. controller fail,controller 發生重新選舉和切換,具體過程參考下文。
b. broker fail,導緻partition的leader發生切換或partition offline,具體過程參考下文。
c. broker 被 hang 住 。
這是一種比較特殊的 case,出現時在 server.log 會出現如下的log,
server.log:
“info i wrote this conflicted ephemeral node [{"jmx_port":9999,"timestamp":"1444709 63049","host":"10.151.4.136","version":1,"port":9092}] at /brokers/ids/1 a while back in a different session, hence i will backoff for this node to be deleted by zookeeper and retry (kafka.utils.zkutils$)”
問題在于“the current behavior of zookeeper for ephemeral nodes is that session expiration and ephemeral node deletion is not an atomic operation.”
即 zk 的 session 過期和 ephemeral node 删除并不是一個原子操作;
出現的case如下:
在極端case下,zk 觸發了 session timeout,但還沒來得及完成 /brokers/ids/1 節點的删除,就被 hang 住了,比如是去做很耗時的 fsync 操作 。
但是 broker 1 收到 session timeout 事件後,會嘗試重新去 zk 上建立 /brokers/ids/1 節點,可這時舊的節點仍然存在,是以會得到 nodeexists,其實這個是不合理的,因為既然 session timeout,這個節點就應該不存在。
通常的做法,既然已經存在,我就不管了,該幹啥幹啥去;問題是一會 zk 從 fsync hang 中恢複了,他會記得還有一個節點沒有删除,這時會去把 /brokers/ids/1 節點删除。
結果就是對于client,雖然沒有再次收到 session 過期的事件,但是 /brokers/ids/1 節點卻不存在了。
是以這裡做的處理是,在前面發現 nodeexists 時,while true 等待,一直等到 zk 從 hang 中恢複删除該節點,然後建立新節點成功,才算完;
這樣做的結果是這個broker也會被一直卡在這兒,等待該節點被成功建立。
broker 的 failover,可以分為兩個過程,一個是 broker failure, 一個是 broker startup。
在談failover之前,我們先看一個更簡單的過程,就是新加一個全新的 broker:
首先明确,新加的 broker 對現存所有的 topic 和 partition,不會有任何影響;
因為一個 topic 的 partition 的所有 replica 的 assignment 情況,在建立時就決定了,并不會自動發生變化,除非你手動的去做 reassignment。
是以新加一個 broker,所需要做的隻是大家同步一下中繼資料,大家都知道來了一個新的 broker,當你建立新的 topic 或 partition 的時候,它會被用上。
首先明确,這裡的 broker failure,并不一定是 broker server 真正的 dead了, 隻是指該 broker 所對應的 zk ephemeral node ,比如/brokers/ids/1,發生 session timeout;
當然發生這個的原因,除了server dead,還有很多,比如網絡不通;但是我們不關心,隻要出現 sessioin timeout,我們就認為這個 broker 不工作了;
會出現如下的log,
controller.log:
“info [brokerchangelistener on controller 1]: newly added brokers: 3, deleted brokers: 4, all live brokers: 3,2,1 (kafka.controller.replicastatemachine$brokerchangelistener)”
“info [controller 1]: broker failure callback for 4 (kafka.controller.kafkacontroller)”
當一個 broker failure 會影響什麼,其實對于多 replicas 場景,一般對最終客戶沒啥影響。
隻會影響哪些 leader replica 在該 broker 的 partitions; 需要重新做 leader election,如果無法選出一個新的 leader,會導緻 partition offline。
因為如果隻是 follow replica failure,不會影響 partition 的狀态,還是可以服務的,隻是可用 replica 少了一個;需要注意的是,kafka 是不會自動補齊失敗的replica的,即壞一個少一個;
但是對于 leader replica failure,就需要重新再 elect leader,前面已經讨論過,新選取出的 leader 是可以保證 offset 一緻性的;
note: 其實這裡的一緻性是有前提的,即除了 fail 的 leader,在 isr(in-sync replicas) 裡面還存在其他的 replica;顧名思義,isr,就是能 catch up with leader 的 replica。
雖然 partition 在建立的時候,會配置設定一個 ar(assigned replicas),但是在運作的過程中,可能會有一些 replica 由于各種原因無法跟上 leader,這樣的 replica 會被從 isr 中去除。
是以 isr <= ar;
如果,isr 中 沒有其他的 replica,并且允許 unclean election,那麼可以從 ar 中選取一個 leader,但這樣一定是丢資料的,無法保證 offset 的一緻性。
這裡的 startup,就是指 failover 中的 startup,會出現如下的log,
“info [controller 1]: new broker startup callback for 3 (kafka.controller.kafkacontroller)”
過程也不複雜,先将該 broker 上的所有的 replica 設為 online,然後觸發 offline partition 或 new partition 的 state 轉變為 online;
是以 broker startup,隻會影響 offline partition 或 new partition,讓他們有可能成為 online。
那麼對于普通的已經 online partition,影響隻是多一個可用的 replica,那還是在它完成catch up,被加入 isr 後的事。
note: partition 的 leader 在 broker failover 後,不會馬上自動切換回來,這樣會産生的問題是,broker間負載不均衡,因為所有的讀寫都需要通過 leader。
為了解決這個問題,在server的配置中有個配置,auto.leader.rebalance.enable,将其設為true;
這樣 controller 會啟動一個 scheduler 線程,定期去為每個 broker 做 rebalance,即發現如果該 broker 上的 imbalance ratio 達到一定比例,就會将其中的某些 partition 的 leader,進行重新 elect 到原先的 broker 上。
前面說明過,某個 broker server 會被選出作為 controller,這個選舉的過程就是依賴于 zookeeper 的 ephemeral node,誰可以先在"/controller"目錄建立節點,誰就是 controller;
是以反之,我們也是 watch 這個目錄來判斷 controller 是否發生 failover 或 變化。controller 發生 failover 時,會出現如下 log:
“info [sessionexpirationlistener on 1], zk expired; shut down all controller components and try to re-elect (kafka.controller.kafkacontroller$sessionexpirationlistener)”
controller 主要是作為 master 來仲裁 partition 的 leader 的,并維護 partition 和 replicas 的狀态機,以及相應的 zk 的 watcher 注冊;
controller 的 failover 過程如下:
試圖去在“/controller” 目錄搶占建立 ephemeral node;
如果已經有其他的 broker 先建立成功,那麼說明新的 controller 已經誕生,更新目前的中繼資料即可;
如果自己建立成功,說明我已經成為新的 controller,下面就要開始做初始化工作,
初始化主要就是建立和初始化 partition 和 replicas 的狀态機,并對 partitions 和 brokers 的目錄的變化設定 watcher。
可以看到,單純 controller 發生 failover,是不會影響正常資料讀寫的,隻是 partition 的 leader 無法被重新選舉,如果此時有 partition 的 leader fail,會導緻 partition offline;
但是 controller 的 dead,往往是伴随着 broker 的 dead,是以在 controller 發生 failover 的過程中,往往會出現 partition offline, 導緻資料暫時不可用。
a, 驗證topic 是否work?
最簡單的方式,就是用 producer 和 consumer console 來測試
producer console,如下可以往 localhost 的 topic test,插入兩條 message,
consumer console,如下就可以把剛寫入的 message 讀出,
如果整個過程沒有報錯,ok,說明你的topic是可以工作的
b, 再看看topic是否健康?
這樣會列印出 topic test 的 detail 資訊,如圖,
從這個圖可以說明幾個問題:
首先,topic 有幾個 partitions,并且 replicas factor 是多少,即有幾個 replica?
圖中分别有32個 partitions,并且每個 partition 有兩個 replica。
再者,每個 partition 的 replicas 都被配置設定到哪些 brokers 上,并且該 partition 的 leader 是誰?
比如,圖中的 partition0,replicas 被配置設定到 brokers 4和1上面,其中 leader replica 在 broker 1 上。
最後,是否健康?
從以下幾個方面依次表明健康程度,
isr 為空,說明這個 partition 已經 offline 無法提供服務了,這種 case 在我們的圖中沒有出現;
isr 有資料,但是 isr < replicas,這種情況下對于使用者是沒有感覺的,但是說明有部分 replicas 已經出問題了,至少是暫時無法和 leader 同步;比如,圖中的 partition0,isr 隻有1,說明 replica 4 已經 offline
isr = replicas,但是 leader 不是 replicas 中的第一個 replica,這個說明 leader 是發生過重新選取的,這樣可能會導緻 brokers 負載不均衡;比如,圖中的 partition9,leader是2,而不是3,說明雖然目前它的所有 replica 都是正常的,但之前發生過重新選舉。
c,最後就是看kafka的日志,kafka/logs
主要是看 controller.log 和 server.log,分别記錄 controller 和 broker server 的日志。
然後根據前面我給的每種異常的日志,你可以看出來到底是出現什麼問題。
本文章摘自部落格園,原文釋出日期:2015-11-17