2017運維/devops線上技術峰會上,阿裡雲應用運維專家誇父帶來題為“同城容災架構剖析”的演講。本文主要從部署目标和要求開始談起,接着着重對架構進行分析,然後又重點對任務分解進行說明,并對單雙機房的部署進行了對比,最後分享了容災演練方式。一起來了解下吧。
以下是精彩内容整理:
近幾個月,運維事件頻發。從“爐石資料被删”到“mongodb遭黑客勒索”,從“gitlab資料庫被誤删”到某家公司漏洞被組合攻擊。這些事件,無一不在呐喊——做好運維工作的重要性。然而,從傳統it部署到雲,人肉運維已經是過去式,雲上運維該怎麼開展?尤其是雲2.0時代,運維已經向全局化、流程化和精細化模式轉變。與此同時,人工智能的發展,“威脅論”也随之襲來——運維是不是快要無用武之地了?如何去做更智能的活,當下很多運維人在不斷思考和探尋答案。
從曆史來看,單機房出現網絡級故障、電源級故障都時有發生,阿裡雲在北京、香港機房等都出現過故障,從業界來看,對于機房級别,類似于雲上engine級别的容災是非常有必要的,下面我們來具體了解下我們的業務系統是怎樣做雙機容災的。
目标&要求
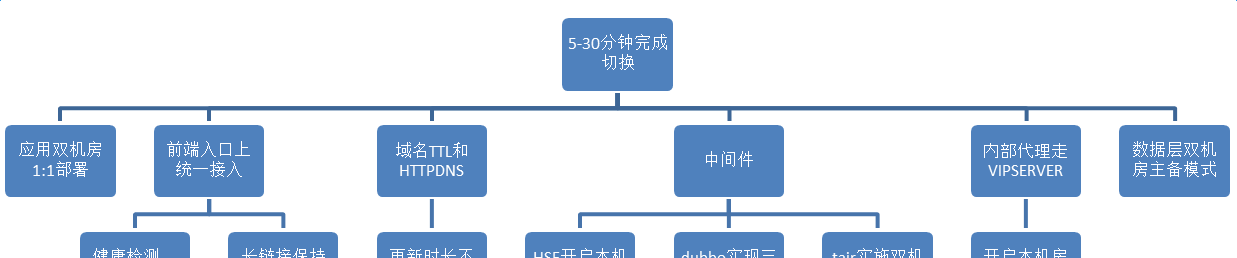
我們的目标就是在一個機房出現斷網或斷電的情況下,能夠在5~30分鐘完成從a機房切換到b機房。最初當a機房單獨部署時,我們要把所有應用從a機房完全copy一份部署到b機房,從架構層面看,要将所有流量放到最前面機房級入口上,是以我們将所有前端的流量,包括open api流量、頁面級的流量等全部切到統一接入,統一接入就是tengine proxy,并且我們在域名層ttl和httpdns都做了設定,全網的更新時間不能超過5分鐘;還有很多中間件的部分,包括hsf開啟本機房優先、dubbo實作三機房部署和tair實施雙機房單叢集等20多個中間件;另外,内部代理走vipserver,開啟本機房優先政策;還有資料層雙機房主備模式。
我們到底要做什麼呢?
首先設立目标,5~30分鐘完成切換,從應用層來說,我們要實作雙機房部署,從流量層來說,我們需要從兩邊機房引入流量,這是一個雙活的概念,不是一主一備。
架構設計

我們将所有流量全部向上提了一層,接統一接入層的http應用。最初的架構并不是這樣的,是按照一個頻道一個頻道接入的,按1:1的模式,這樣的架構的好處是互不影響,任何一組機器挂掉,隻影響一個子產品對外提供的服務,但做雙機容災采用這種方案的話,複雜度太高,是以我們接入統一接入層。
針對接入統一接入的http應用,統一接入層有分流政策,天然支援應用多機房部署。流量進入統一接入後,通過vipserver進行分流,vipserver自帶健康檢查,當應用或者網絡出現問題,自動切斷流量。
我們還有很大部分是rpc類型的應用,類似今天注冊中心、注冊發現的這種,不像前端流量直接打進來,其實是注冊到注冊中心,由注冊中心告訴服務注冊者或消費者真正的服務在哪裡,我們認為它并不适合統一接入,流量大且對時間要求高,是以我們單獨對這組機器做了兩個vip,分在兩三個機房,對dubbo注冊中心域名dubbo.aliyun-inc.com進行adns智能解析,當機房出現故障,adns會自動踢掉有問題的vip。
在做規則時,架構分為三層,包括web應用層、中間件層和資料庫層。我們選取兩個比較有代表性的中間件來講:
從事實角度來講,tair的改造量是最大的,tair有雙機房單叢集模式、雙機房雙叢集模式,應用隻在一個機房時,有些用雙機房雙叢集模式,有一些用雙機房單叢集,經過技術判斷和排查,發現當使用雙機房部署時,可以用雙機房雙叢集,但涉及代碼改造量會非常大,因為需要保證兩個叢集資料的一緻性,而雙機房單叢集也有缺陷,比如a機房出現斷網斷資料情況下,tair資料裡是有50%資料要丢失,意味着選擇雙機房單叢集就要忍受資料丢失,如果對資料要求非常高,必須選擇雙機房雙叢集,如果業務對資料一緻性要求較高,但對于資料的丢失可以忍受,那就可以用選擇雙機房單叢集。
mtaqe3也比較有資料,mtaqe3其實是一個隊列,隊列服務是不允許資料丢失的,是以mtaqe3是在兩個機房各設定了兩個機器,全部都是master,相當于消息寫入時随機寫入一個master到某個機房,如果全部都是雙master結構也有弊端,就是沒有備份,資料有可能在機器故障時丢失,對于我們的應用來說對于該場景的忍受度還可以,這也是基于業務來确定的,如果消息丢失可以重寫,雙master是被允許的。如果當有一條消息寫入到a機房,恰好有b機房的應用讀a機房讀到一半,a機房斷網了,這時消息就會丢失,相當于消費了一半,比如ecs的生産,場景是非常複雜的,取一條消息比如磁盤是多少、cpu是多少,鎖定消息後,它是串行的,後面還要燒ip、os和各種場景,它是要将這條消息取走消費一遍再塞回去,這是一個事務流的場景,可能會斷掉,斷掉後會有補償機制,最終結合業務場景和開發人員溝通,确定雙master架構,保證消息隊列能夠平穩正常運作。
任務分解
我們對整個項目進行任務分解,首先是系統梳理,到底有哪些系統需要做雙機容災;其次是資源申請,包括伺服器申請、人的申請等;接着是項目運作,還要做風險評估,怎樣去規避風險;從a機房将所有應用向b機房複制時,勢必要有很強大的工具支撐,光靠人力來支撐是無法完成的;所有事情做完後,通過容災演練來驗證項目是否達到預期目标,如果沒有,進行改進。
任務分解,在整個官網系統有上千個應用,幾千台伺服器,這麼多系統肯定是要分級别的,具體如下:
l1級别是最高的,比如官網首頁、售賣系統、管控系統和生産系統等一些核心業務必須要完成雙機房部署的;
l2比如背景系統、crm、工單和雲台等作為支撐系統,優先級次之,并不直接對使用者提供服務,但對于我們來說是非常重要的,對于客戶來說也是非常重要的;
l3比如像雲服、容器服務、編排服務和增值服務等,更多的是由開發同學自己維護和部署,這部分也是需要做的,但是我們需要提供工具,提供咨詢和服務;
l4比如像域名、備案和信安,這些都是強綁定的,暫時沒有辦法做,帶後面所有都完成後,這部分也會做掉,也會對使用者直接提供服務,比如域名買了需要備案等。
隻要涉及到使用者的需求,我們一定會做,嚴格以使用者的需求為需求,是以任務分解是非常重要的一步,是以我們要分階段去做:
1.
資源申請:我們要申請伺服器資源,成立聯合項目組,申請中間件及dba團隊支援;
2.
項目運作:建立項目組釘釘群同步改造進度,以項目周報的方式向所有老闆及相關同學同步進度,以雙周會的形式推進疑難問題解決及風險評估;
3.
工具支撐:開發了專門的工具平台使用者應用快速擴容,開發專門的工具使用者快速測試等;
4.
容災演練:制定機房級的斷網用以驗證同城容災的結果是否符合架構設計并發現隐藏問題。
上圖為我們開發出的專門的一鍵擴容工具,将應用填進去,将分組取出來,确定擴容機房,以線上一台模闆機作為擴容對象,完全克隆模闆機上的所有應用環境配置,可以實作機房級别的快速擴容,極大的提高了效率。後續我們可能會使用自定義鏡像去做,将線上一台機器打成自定義鏡像,新的機器用自定義鏡像開啟就好。
架構對比圖
圖中左側為單機房時架構,可以從架構中很清楚的看到,使用者進來的最前端有兩層,第一層是web層,包括首頁、賬号、售賣頁和支付、控制台等,第二層是open api網關,進來後經過登入和權限校驗向下釣,是一個非常簡化的官網架構圖。
圖中右側為雙機房架構,看起來很簡單,像是将單機房架構複制了一份,但是簡單的背後還是有很多事情要做的,中間件須橫跨兩個機房,要求a機房斷掉後,所有中間件要正常提供服務,所有的應用也能正常提供服務,流量最主要的切換在最上面一層,比如a機房斷網後,我們需要把放在a機房統一接入和openapi的流量全部切到b機房,為此我們專門做了一鍵切換工具,我們需要檢測在什麼情況下需要啟動切換,這是一個複雜的判斷過程。
容災演練
我們要制定演練的方式,具體如下:
斷網方式:将機房a内網全部通過acl隔離
斷網效果:被斷網的伺服器和其他機房無法進行通信,和本機房通信不受影響,和外圍通信(營運商)不受影響
流量切換:所有web類及openapi類操作直接通過idns智能判斷将機房a流量切到機房b
db切換:db采用rds的proxy實作自動主從切換
業務驗證:待db及流量切換完成後采用自動化測試或工具真實售賣、生産及管控進行業務驗證
圖中a機房連接配接b機房的路被斷掉了,中間件一半的機器被下線了,我們要求所有的中間件叢集化,允許一半機器在a機房一半在b機房,不論哪個機房斷電都不能影響整個機器的服務,後續我們考慮将zk去除掉,因為zk必須是三機房。容災演練是一個長期的過程,從架構的演進來講,我們後面更希望做異地容災,這是更高層的容災機制。