2017運維/devops線上技術峰會上,餓了麼運維負責人程炎嶺帶來題為“餓了麼redis cluster叢集化演進”的演講。本文主要從資料和背景開始談起,并對redis的治理進行分析,接着分享了redis cluster的優缺點,重點分析了corvus,包括commands、邏輯架構和實體部署等,最後分享了redis的運維和開發,并作了簡要總結,一起來瞧瞧吧。
以下是精彩内容整理:
近幾個月,運維事件頻發。從“爐石資料被删”到“mongodb遭黑客勒索”,從“gitlab資料庫被誤删”到某家公司漏洞被組合攻擊。這些事件,無一不在呐喊——做好運維工作的重要性。然而,從傳統it部署到雲,人肉運維已經是過去式,雲上運維該怎麼開展?尤其是雲2.0時代,運維已經向全局化、流程化和精細化模式轉變。與此同時,人工智能的發展,“威脅論”也随之襲來——運維是不是快要無用武之地了?如何去做更智能的活,當下很多運維人在不斷思考和探尋答案。
redis cluster在業内有唯品會、優酷藍鲸等很多公司都已經線上上有了一定規模的redis cluster叢集,那麼,餓了麼是怎樣從現有的redis技術遷移到redis cluster叢集上的呢?
背景和資料
2015-2016年是餓了麼的業務爆炸式增長階段,訂單量從幾十w到到峰值900w/天,在增長的過程中我們也遇到了一些問題,我們有服務化治理訴求、應用性能和穩定訴求、人肉運維成本訴求,并且還要為未來的paas平台池化準備。
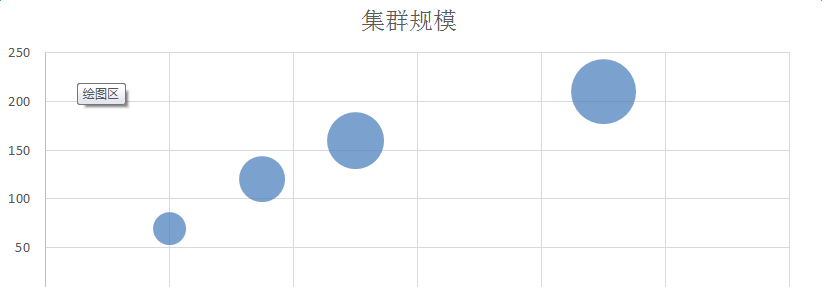
橫坐标是訂單量,縱坐标是叢集數量,在多機房下整個叢集規模是double的,可以看到,千萬訂單的叢集規模大概在200個,在一個機房内我們有近200套叢集,近4t資料在redis裡面,整個節點數大約在10000個左右。

上圖表示在高峰期時每天不同訂單量下,整個redis叢集承載ops的需求。
<b>使用場景</b><b></b>
外賣行業的使用場景要結合業務來看,所有需要高性能、高并發、降級資料庫場景下都用到了redis做緩存,包括使用者端、商戶端和物流配送,搜尋排序、熱賣、畫像等目前也是往redis裡推送,除了緩存外,還有各類cache、計數器、分布式鎖等。
為什麼會考慮向redis cluster演進呢?
因為redis存在很多問題,比如單點的記憶體上限受限制,将redis當成db或cache混用,共用一個redis、大key阻塞整個執行個體,經常需要擴容、擴容很痛苦,使用複雜且基礎環境非标、存在各種配置,監控缺失以及不能統一配置等諸多問題。
治理
由于redis請求量太大,打滿了機器網卡,是以在2016年5月啟動了治理redis的項目。
在自研選型部分,在ops推廣治理時我們與業内成熟技術做了比較,包括redis vs redis cluster,以及twenproxy vs codis vs redis cluster,比較了單節點的redis和redis
cluster,還有業内經過生産考驗的proxy,最後決定自研自己的redis cluster + proxy。
redis cluster 的優缺點
為什麼選擇redis cluster作為我們的底層存儲呢?
redis cluster自帶遷移功能,性能快、高可用,支援線上分片,豐富叢集管理指令等。自研proxy在初期快速在生産上應用時候可以省略掉這部分,讓redis cluster本身給我們提供這項功能就足夠了。
redis cluster也有一些不足:
client 實作複雜,需要緩存slot mapping關系并及時更新;
client不成熟導緻提高開發難度;
存儲和分布式邏輯耦合,節點太多時節點之間的檢測占大量網卡帶寬;
3.0.6版本前,隻能單個key遷移,并且同時隻允許一個slot處于遷移狀态。
corvus
圖中為corvus時序設計,可以看到,actor到後面的redis,中間的proxy、client和server是在corvus中實作的邏輯,proxy處理connect操作,接收使用者的請求發送到client,server最終實作指令的處理。我們分成三個分類,對于單key、特殊指令和多key的處理,對複合指令操作做了單獨操作,并對傳回結果做聚合,同時還有一些特殊指令,比如cluster指令的處理邏輯。
corvus封裝了redis cluster 協定,提供redis 協定,這樣用原來成熟的redis
client操作redis cluster叢集,接入到corvus,這時可以做到無縫的改動;擴容縮容應用無感覺,corvus服務是注冊的機制,對應用程式來說,連接配接是通過一層本地proxy,我們對應用程式提供sdk,但目前我們通過本地proxy連接配接接入corvus已經能夠滿足大部分應用;corvus實時緩存了slots mapping,它會不停的發送corvus notes去擷取redis node與slots mapping的關系,并更新到corvus本身的緩存中,還有multiple thread、lightweight和reuseport support等。
<b>corvus commands</b>
corvus支援pipeline;
modified commands,對複合指令做spring操作,我們已經對指令本身進行了修改,但可能對我們看監控資料有疑惑,統計端節點命中率與應用程式命中率可能不一樣;
restricted commands;
unsupported commands,比如對gu的處理,目前還沒有在redis cluster中使用gu的應用,暫時不會支援。
<b>corvus performance</b>
圖中為corvus的測試報告,這是很極端的壓測情況,set/get可以達到140萬qps資料。
<b>corvus </b><b>邏輯架構</b><b></b>
可以看到,底層存儲用redis cluster,web console通過後端ruskit操作redis cluster,當我們注冊redis cluster時,appid存儲在storage裡,監控部分我們通過esm agent發送到grafana,corvus本身也會采集server log發送到statsd去收集,corvus agent去部署時首先要初始化corvus agent注冊到host console裡,通過corvus agent去拉起或回收某一套redis cluster,huskar是我們的集中配置管理,對應到我們後端的zk技術。
<b>corvus </b><b>實體部署</b><b></b>
corvus的實體部署如圖所示,上面是應用程式端,應用程式連接配接到本地的corvus服務端口,corvus服務端口作為本地的sam port,一個corvus執行個體對應到redis cluster的一些master節點,會部署在不同的實體伺服器上,根據不同的和數去建立corvus服務執行個體以及redis節點。
這裡有兩層proxy,首先連接配接本地的sam,也就是go proxy,go proxy這層提供應用服務化、本地接入,corvus是redis cluster proxy這一層,兩層proxy意味着兩層的性能損耗,在這個基礎上,我們也做了針對redis cluster相同的直連的性能損失,對比來看,proxy層性能損耗相比運維成本以及服務化成本而言,是可以接受的。
redis 運維和開發
<b>redis</b><b>運維</b><b></b>
我們将redis移交資料庫團隊運維
統一redis 實體部署架構
标準化redis/corvus
伺服器以及單機容量
設定redis 開發設計規範
設定redis資源申請流程,做好容量評估
完善監控,監控分corvus和redis
cluster兩部分,跟進全鍊路壓測,從最前端打進來,到底層的redis和資料庫
根據壓測結果做隔離關鍵叢集,比如整個外賣後端和商戶的redis,将它們做單獨隔離,redis cluster本身對網卡要求很高,分專用資源和公共資源,專用資源的corvus或redis cluster機器獨棧給到appid,公共資源是混布情況,我們隻需監控網卡流量、cpu等
更新萬兆網卡,新采購的伺服器都是萬兆配置
<b>redis </b><b>開發約定</b><b></b>
redis開發約定如下:
key 格式約定:object-type:id:field。用":"分隔域,用"."作為單詞間的連接配接,對于整個field怎樣分隔,我們有很多種改法;
禁止大k-v,我們基于全鍊路壓測,比如一套叢集有多種類型的pattern的key,其中某一個的key value很長,占用記憶體很大,我們就要告訴開發者像這種使用姿勢是不對的,須被禁止;
隻用作cache, key
ttl設定;
做好容量評估,由于redis
cluster的遷移限制,是以前期我們要做好容量評估,比如整套叢集申請100g,我們需要計算需要的記憶體容量以及所在的應用場景負載;
設定叢集上限,規定redis
cluster叢集數不超過200,單個節點容量4~8g;
接入統一為本地goproxy
<b>redis </b><b>改造</b><b></b>
我們要定義一個節奏,對redis進行改造,具體如下:
1.
将redis 遷移cluster
2.
完善system、redis、corvus監控
3.
對線上redis拆分、擴容
4.
非标機器騰挪下線
5.
大key、熱節點、大節點掃描,比如同一個redis cluster叢集某個節點明顯高于其它節點,我們會做節點分析和key的分析等
6.
網卡bond,多隊列綁定
7.
修改jedis源碼,加入matrix埋點上報etrace,就可以在etrace看到每個應用trace到整條鍊路到哪一個端口,它的響應時間、請求頻次、命中率等。
經驗總結
對于redis我們可謂經驗豐富,總結如下:
redis 更适合cache,cluster下更不合适做持久化存儲
一緻性保證,不做讀寫分離(盡管corvus支援)
單執行個體不宜過大,節點槽位要均衡
發現問題,複盤,積累經驗
不跨機房部署,性能優先
異地多活通過訂閱消息更新緩存
大部分的故障都是由于hot-key/big-key
關心流量,必要時立刻更新萬兆
<b>遺留問題</b><b></b>
目前redis還不夠自動化,某些操作還是分成多個步驟來實作,大叢集reshard擴容慢;遇到版本更新問題時,可以新起一條叢集;sam->corvus->redis鍊路分析,應用程式在etrace上通路端口會很慢,需要從redis和corvus層層自證等;多活跨機房寫緩存同步;我們通過定時任務的發起aof/rdb來保證資料盡快恢複,實際上我們是關閉掉的;冷資料也是不夠完善的,還有叢集自愈,當遇到問題時我們可以快速拉起另外一套叢集将資料更新過去,或者通過資料更新預熱将緩存更新過去。
<b>池化</b><b></b>
我們在根據全鍊路壓測時的一些特性或資料去做叢集隔離,分放公共池和專用池,以及對整個池内資源做buffer的監控;資源申請隻需關注容量以及使用方式,無需關心機器;另外,新申請以及擴容縮容按組(group)操作,運維操作自動化,不需要登入到某個機器上執行某個指令。
<b>開發自助</b><b></b>
我們最終的目标是在緩存部分實作開發自助,具體步驟如下:
開發自助申請redis 資源
填入demo key/value,自動計算容量
狀态,告警推送,對線上實時運作情況的透明化
各類文檔齊全
目前我們還做不到,需要ops團隊幹預開發。