你是否遇到過資料庫伺服器的out of memory(oom)現象?就是資料庫的程序把作業系統記憶體耗盡,觸發作業系統對資料庫程序執行kill -9操作。作業系統對某個資料庫程序的kill,會導緻整個資料庫執行個體所有執行個體重新開機,所有連接配接會斷開,造成一定時間的資料庫不可用。oom對資料庫服務影響較大,應該盡量避免。
在我們的hybriddb for pg 雲服務中,也可能遇到使用者執行個體耗盡所有可用記憶體的情況。一般情況下,我們會采用cgroup機制來限制使用者的記憶體使用,同一執行個體在同一主機上的所有程序會放入一個cgroup。當資料庫執行個體使用的記憶體總量超出限制時,會觸發作業系統從cgroup中找出耗記憶體較多的程序,執行kill -9,這會導緻我們上面說的資料庫服務暫時不可用。這裡作業系統的kill操作我們稱為oom kill。
發生oom的因素一般是應用的并發連接配接數過多、大對象的存取操作、查詢用到過多的臨時記憶體,執行個體記憶體過小等。從雲服務提供者的角度看,我們無法提前預知或限制使用者的使用行為。通常是發生oom kill後,監控程式檢測到作業系統錯誤日志,我們才會進行處理,而此時往往已經對使用者業務造成了影響。就是說,我們無法避免oom的發生。但能不能更好的處理oom,避免oom kill這種嚴重後果呢?本文将對此進行讨論。
hybriddb for pg 是基于greenplum開發的。為盡量避免oom kill,greenplum提供了resource manager記憶體限制功能。通過設定resource manager參數,可以限制整個執行個體可以申請的記憶體。其背後的機制是,在每次資料庫核心執行malloc系統調用,申請作業系統記憶體時,用一個全局變量累加記錄申請的記憶體量,并它記錄的執行個體記憶體申請總量是否已經超限,如果超限則報錯。
greenplum這種方法看似可行,但在我們的雲服務中卻不宜采用。這是因為,作業系統并不是在malloc被調用的時候,把實際的實體記憶體傳回給調用者,而是等到調用者實際使用(例如做記憶體拷貝操作)時,才配置設定實體記憶體給它。也就是說。記錄的malloc記憶體總量,是虛拟記憶體使用量(可以從top指令輸出中virt字段,檢視一個程序的虛拟記憶體),并不能反映資料庫實際使用的記憶體(實際使用記憶體量可以從top指令輸出中的rss字段得到)。如果按這種方法做限制,使用者實際可用記憶體會比他購買的規格記憶體記憶體少的多。在我們的一個測試中發現,malloc記錄的記憶體有時是執行個體實際使用記憶體的兩倍以上!
既然使用resource manager記錄和限制記憶體使用的方法不可行,有沒有更優雅的方式盡量避免oom kill呢?使用hybriddb的使用者,如果線下使用過greenplum,可能會發現,在大量使用記憶體時,線下會觸發oom kill的場景在hybriddb可能并未觸發(雖然還是會有sql報錯,但并沒有觸發執行個體重新開機)。另一方面,使用者可以實際使用到hybriddb規格标稱的記憶體。實際上hybriddb使用了獨特的的方式處理oom,較大程度上避免了oom kill被觸發。下面我們介紹一下hybriddb的方法。
下圖是個hybriddb執行個體的例子。主節點、兩個子節點分布位于不同的linux主機上。每個節點都使用cgroup限制了記憶體,例如,每個節點限制使用8g記憶體。
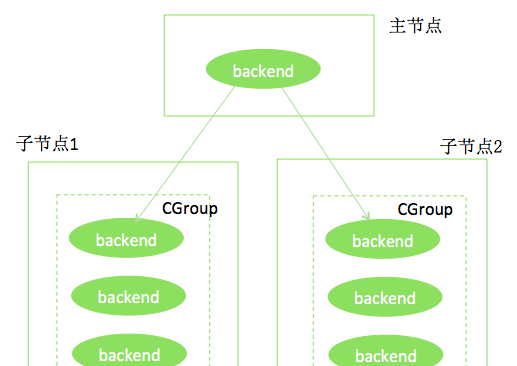
我們假設上述執行個體的某個節點使用了超過8g的記憶體,如果按原有機制,此節點所在主機的作業系統,會找出此執行個體對應cgroup中使用記憶體較多的程序,執行kill -9,此節點的所有程序重新開機,暫時不可用。更嚴重的是,這可能使整個hybriddb叢集不可用!為避免這種情況,hybriddb使用了如下方法:
a. 建立一個獨立的cgroup,限制例如10g的記憶體,如下圖所示。

b. 将執行個體的cgroup記憶體限制提升20%,即如果使用者執行個體的節點規格是8g的記憶體,則在cgroup中,提升為9.6g。這樣做的目的是為下面的操作留存空間。
c. 啟動一個腳本,實時監控(例如每秒鐘掃描一次)主機所有cgroup的記憶體水位。作業系統提供了機制,在cgoup狀态資訊中可以查到記憶體的水位資訊。當發現某個cgroup的水位過高(例如超過了100%的規格可用記憶體,如8g)時,将記憶體使用最高的程序移入公用cgroup。如果記憶體水位未降低到指定水位,如規格記憶體的80%,則繼續在此cgroup中取出記憶體占用高的程序,放入公用cgroup。如下圖所示。
d. 啟動另一個獨立的腳本,不斷擷取公用cgroup中的程序,對這些程序發送特殊的信号;hybriddb程序收到這些信号,将執行類似cancel query一樣的操作,撤銷目前正在進行的查詢,同時傳回給使用者如下的提示:
這個步驟如下圖所示。
e. b中提到的記憶體監控腳本在記憶體降低到指定水位(如規格記憶體的80%)後,則進入到另一狀态,即開始将程序從公用cgroup移動回原cgroup,直到水位上升到預設水位(如100%規格記憶體)。如下圖所示。
上述方法的優勢有:
1)由于在執行個體記憶體不斷增長的過程中,實時的監控記憶體使用,在記憶體超限時,觸發查詢的撤銷操作,保護了執行個體,避免的執行個體的整體不可用。
2)使用者可以通過出錯資訊獲知記憶體不足導緻查詢失敗,進而做進一步處理。如果觸發了oom kill,使用者隻能看到連接配接斷開、執行個體重新開機,但無法獲知發生現象的原因,是以通常會誤以為是網絡連接配接問題。
3)由于一台機器的所有執行個體都共享一個公用cgroup,而這個cgroup一般10g左右就滿足使用了,是以它并不會增加多少成本。另外雖然為使用者提升了20%的記憶體,但由于超出規格記憶體時就開始做查詢撤銷操作了,是以實際上執行個體并不會長時間多用記憶體。
4)這種方法實作簡單。僅需要編寫兩個監控腳本,并在hybriddb核心中增加對特殊信号的支援。
需要注意的是,如果公用cgroup的記憶體也耗盡了,是會觸發oom kill的。也就是說這種方法并不會完全避免oom kill,但從實踐看,大大降低了oom kill的發生幾率。
hybriddb對oom的處理方式,雖然沒能避免oom,但大大減少了oom kill的發生,避免了整個hybriddb叢集不可用的危險後果。可以說這是一種更優雅的oom處理方式。當然,作為hybriddb的使用者,仍然要從應用層做工作,提前降低oom發生的幾率,例如,降低并發度、調優大量使用臨時記憶體的查詢、更新執行個體規格等。