本篇分享最近把elasticsearch當作時序資料庫來用的心得。
• 需求
需求是這樣的:提供一個背景,選使用者畫像标簽(多選),點确認後彈出“選出了xxx個使用者”,再繼續點就把使用者dump出來、推送消息。現在要做這個背景的資料倉庫層。
詳細分析一下需求:
1. 我們的使用者畫像走流式計算,每秒大量更新,是以對插入/更新性能要求很高。
2. 查詢條件翻譯成sql就是類似 select count(*) from `table` where (`tags` like '%tag1%') and (`tags` like '%tag2%') and (`tags` like '%tag3%') and ...,正常資料庫算起來比較慢。
需要一個資料倉庫,支援大量插入/更新、大量導出、快速多字元串比對查詢。
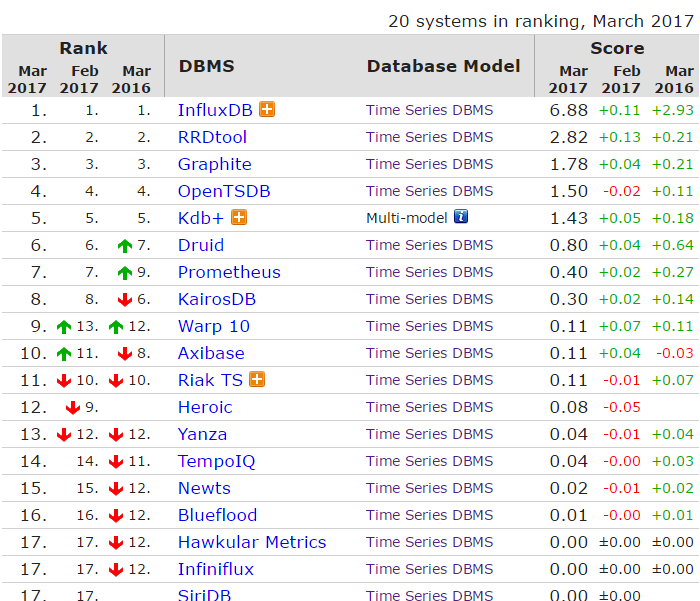
很不幸的是,單機版influxdb在壓測環節爆了,頂不住插入/更新的量。而分布式influxdb又閉源了。接下來嘗試了一下elasticsearch,于是就有了這篇文章了。
• es能幹這個事麼?
還真能。
1. 插入/更新性能高
es通過bulk接口,可以做到批處理,擁有相當高的插入/更新性能。
2. 查詢效率高
3. 導出效率高
用es的scroll接口可以做到這麼一件事:1)進行一個查詢,指定翻頁大小、本次查詢的索引儲存時間,擷取一個scroll_id;2)通過scroll_id不斷地翻頁。可以實作大批量導出一個查詢的所有資料,不需要重複計算。
4. 高可用與橫向擴充能力
就不贅述了。
• 實作與優化
1. 用了3個node組成的叢集,全ssd。3個剛好是滿足高可用的最小master node數量。每個node的記憶體開到31g。
2. es前面頂一層logstash,logstash開一個http-input和elasticsearch-output,用http keep-alive來接流量。關鍵配置有:
1)input.http.threads預設是4,要開大;
2)output.elasticsearch.action => "update",output.elasticsearch.doc_as_upsert => true,這樣可實作upsert操作;
3)pipeline.workers跟pipeline.output.workers開到跟核數一緻;
4)pipeline.batch.size跟output.elasticsearch.flush_size适度開大。
3. 整個流程是資料怼logstash、logstash怼es,是以會有es的資料延後幾秒才更新的情況,這樣可能會引起一些問題,需要務必留意。
4. es5.0取消了ttl,是以資料的過期要另外處理。
5. es的scroll查詢中,通過配置_source來提取部分字段,可以大幅降低網絡i/o。
• 一些驚喜
我們往es裡存的标簽是沒去重的原始資料,就是說一個使用者的标簽可能長這樣:
a b a a a c d a
而es本質上是個搜尋引擎,使用預設的bm25算法搜尋使用者,排在前面的就自然是重度使用者。
非常不錯。
• 總結
elasticsearch除了用來幹搜尋、運維監控之外,還能用來當時序資料庫。在這個case裡,算是對influxdb等時序資料庫産品做降維打擊了,真乃居家旅行、殺人越貨的神器。
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)