postgresql , hybriddb , htap , oltp , olap , 混合場景 , oracle , 企業痛點 , 資料庫痛點
随着it行業在更多的傳統行業滲透,我們正逐漸的在進入dt時代,讓資料發揮價值是企業的真正需求,否則就是一堆廢的并且還持續消耗企業人力,财力的資料。
傳統企業可能并不像網際網路企業一樣,有大量的開發人員、有大量的技術儲備,通常還是以購買it軟體,或者以外包的形式在存在。
資料的核心 - 資料庫,很多傳統的行業還在使用傳統的資料庫。
但是随着it向更多行業的滲透,資料類型越來越豐富(諸如人像、x光片、聲波、指紋、dna、化學分子、圖譜資料、gis、三維、多元 等等。。。),資料越來越多,怎麼處理好這些資料,怎麼讓資料發揮價值,已經變成了對it行業,對資料庫的挑戰。
對于網際網路行業來說,可能對傳統行業的業務并不熟悉,或者說網際網路那一套技術雖然在網際網路中能很好的運轉,但是到了傳統行業可不一定,比如說用于科研、軍工的gis,和網際網路常見的需求就完全不一樣。
除了對資料庫功能方面的挑戰,還有一方面的挑戰來自性能方面,随着資料的爆炸,分析型的需求越來越難以滿足,主要展現在資料的處理速度方面,而常見的hadoop生态中的處理方式需要消耗大量的開發人員,同時并不能很好的支援品種繁多的資料類型,即使gis可能也無法很好的支援,更别說諸如人像、x光片、聲波、指紋、dna、化學分子、圖譜資料、gis、三維、多元 等等。
那麼我們有什麼好的方法來應對這些使用者的痛處呢?
且看apsaradb産品線的postgresql與hybriddb如何來一招左右互搏,左手線上事務處理,右手資料分析挖掘,解決企業痛處。
以oracle資料庫為例,系統具備以下特點
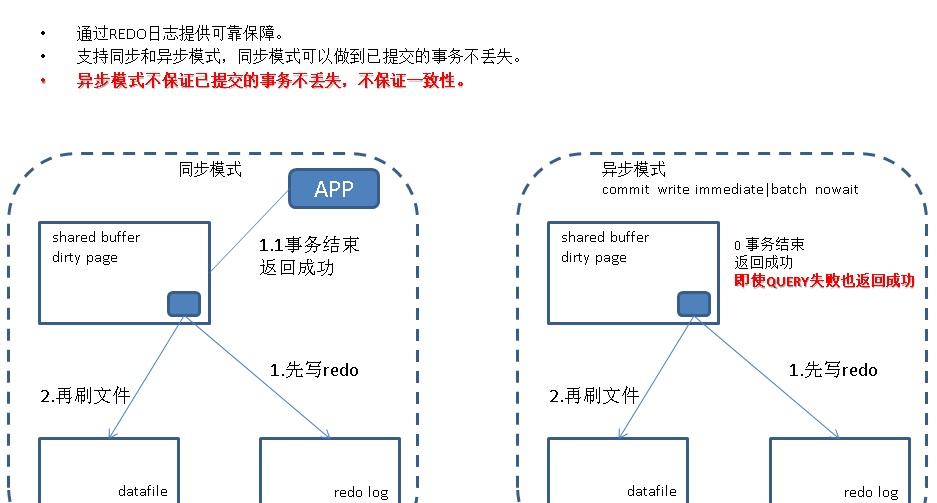
通過redo日志提供可靠保障。
支援同步和異步模式,同步模式可以做到已送出的事務不丢失。
異步模式不保證已送出的事務不丢失,不保證一緻性。
通過主備模式以及叢集套件提供高可用支援
通過共享存儲,rac叢集套件提供高可用支援, 注意應用連接配接設計時,不同的instance連接配接的應用應該通路不同的資料塊,否則可能會因為gc鎖帶來性能嚴重下降。
通過共享存儲,主機叢集套件提供高可用支援

通過存儲層遠端增量鏡像提供異地容災
通過主備模式以及增量複制提供異地容災
通過歸檔和基礎備份提供線上備份以及時間點恢複功能
awr報告,通常包括
top sql、wait event stats、io time、db time
pl/sql程式設計,c嵌入式sql,sql:2013标準
支援pl/sql開發語言
支援c嵌入式開發
sql: 2013
gis
多種索引支援
資料類型豐富
with, connect by, with, grouping set, rollup, cube
many building functions, op, aggs
sql hint、物化視圖、rls(行安全政策)
通過rac和共享存儲,擴充主機的方式擴充,支援cpu并行計算
注意應用連接配接設計時,不同的instance連接配接的應用應該通路不同的資料塊,否則可能會因為gc鎖帶來性能嚴重下降。
比如oracle 12c提出的pdb
通常按核收費,按特性收費,license 昂貴
随着使用者資料量的增長,資料庫的處理能力逐漸成為瓶頸。
以oracle為例,傳統的非mpp架構資料庫,在執行大資料量運算時,受制于硬體限制,對于olap場景顯得很吃力。
以oracle為例,傳統的資料庫沒有機器學習套件,即使有,也受制于它的架構,無法發揮應對資料挖掘分析需求。
rac的擴充能力受到共享存儲的限制,存儲容易成為瓶頸
rac的模式下面,必須確定app不會跨執行個體通路相同的資料塊,否則gc鎖沖突嚴重,性能比單節點下面明顯。
支援的服務端程式設計語言僅pl/sql,c。
不支援進階的類型擴充,函數擴充,op擴充,索引擴充。
不适合企業快速發展的it需求。
昂貴
除了對資料庫基本的增删改查需求,備份恢複容災需求外。企業對資料處理的要求越來越高。
比如很多時候,使用者可能要實時的對資料進行清洗、分析、或者根據資料觸發事件。
随着更多的業務接入it系統,使用者需要存儲越來越多的非結構化的資料、貼近實際需求的資料(比如人像、化學分子式、x光片、基因串、等等現實世界的資料屬性),很多資料庫在這種情況下顯得力不從心,隻能靠應用程式來處理,由于資料離計算單元越來越遠,效率變得低下。
1. llvm、cpu并行計算
2. 聚合算子複用
3. brin索引接口
比如jsonb、圖檔、人像、化學分子式、基因串、gis、路由等。
使用pipelinedb可以與kafka, jstrom, postgresql無縫結合,以及标準的sql接口,相容postgresql.
hybriddb基于開源的mpp資料庫gpdb打造,有許多特點
支援彈性的增加節點,擴容時按表分區粒度進行,是以不堵塞其他表分區的讀寫
支援sql标準以及諸多olap特性,
支援行列混合存儲、多級分區、塊級壓縮、多節點并行計算、多節點資料并行導入、
支援豐富的資料類型,包括json、gis、全文檢索、語感、以及常見的文本、數值類型。
支援madlib機器學習庫,有上百種常見的挖掘算法,通過sql調用udf訓練資料集即可,結合mpp實作了多節點并行的挖掘需求
支援資料節點間透明的資料重分布,廣播,在進行多表join時,支援任意列的join,
支援随機分布,或按列分布,支援多列哈希分布,
支援哈希分區表、範圍分區表、多級分區
支援使用者使用python \ java編寫資料庫端的udf
支援使用r用戶端通過pivotalr包連接配接資料庫,并将r的分析請求自動轉換為madlib庫或sql請求,實作r的隐式并行分析,同時資料和計算在一起,大幅提升了性能
支援hll等估算資料類型,
支援透明的通路阿裡雲高性能對象存儲oss,通過oss ext插件,可以透明的并行通路oss的資料,
支援postgresql生态,吸納更多已有的postgresql生态中的特性
在企業中,通常會有專門的分析師崗位,分析師在做模組化前,需要經曆很多次的試錯,才能找到比較好的,可以固定的分析模型。
試錯期間,根據分析師的想法,結合業務表現,分析師可能需要對資料反複的訓練,這就對資料庫有兩種要求
1. 實時響應
2. 不幹擾正常業務
實時響應對于mpp來說并不能,通常一個query下去,毫秒級就可以響應,不需要等待任務排程。
而不幹擾正常業務,這一點,可能就需要好好商榷了,因為一個query可能把資源用光,當然,我們可以通過hybriddb的資源組來進行控制,比如給分析師的query資源優先級降到最低,盡量減少對業務的幹擾。
另外我們還有一種更加徹底的方法,資料共享,你可以把需要試錯的資料集放到oss中,然後啟用一個空的postgresql執行個體或者hybriddb執行個體,這些執行個體與生産執行個體完全無關,但是它可以去通路oss的資料,建立外部表即可,分析師可以使用這些執行個體,對資料集進行分析,不會影響生産。
通過rds_dbsync, dts, 或者雲上bi、etl廠商提供的etl接口,幾乎可以将任意資料源的資料實時的同步到hybriddb進行分析。
通過 oss 高速并行導入導出
<a href="https://help.aliyun.com/document_detail/35457.html?spm=5176.8115115.382043.8.9yeco0">https://help.aliyun.com/document_detail/35457.html?spm=5176.8115115.382043.8.9yeco0</a>
<a href="https://github.com/aliyun/rds_dbsync">https://github.com/aliyun/rds_dbsync</a>
https://yq.aliyun.com/articles/66902
原理與oracle類似,同時支援使用者自由選擇同步或異步模式,異步模式犧牲了資料可靠性,提升性能,同時不影響一緻性。
使用者可以根據事務對可靠性的要求,選擇副本數。
比如涉及使用者賬戶的事務,至少要求2個副本。
而對于與使用者無關的日志事務,1個副本,甚至異步都可以。
給使用者設計應用時,提供了最大的靈活度。
postgresql的高可用的方案與oracle類似,支援共享存儲的方案,同時還支援流式複制的多副本方案,可以做到資料的0丢失。
hybriddb的高可用方案,為mirror的方式,同步複制,資料0丢失。
master的fts負責資料節點的failover和failback。
master節點的ha則交由上層的叢集應用來解決。
對于多機房容災,postgresql和hybriddb在資料庫層面支援流式的複制解決方案。
同時還支援傳統的存儲或檔案系統層面的鏡像容災。
對于存儲在oss對象存儲中的資料,備份的隻是ddl,即外部表的建表語句。
而對于存儲在資料庫中的資料,使用的備份方法與oracle類似,支援redo的增量備份,也支援資料塊級别的增量備份(具體見我寫過的塊級增量備份文檔)。
每個節點并行的進行。
與oracle類似,支援常見的名額top sql、wait event stats、io time、db time
同時支援對long query進行監控,包括long query的執行計劃翻轉,執行樹中每個節點耗費的時間,對buffer産生的操作,實體讀等
對于hybriddb,使用resource queue控制不同使用者對資源的使用
資料庫功能方面,postgresql超越了傳統資料庫所能cover的資料類型、檢索、和資料的運算。
1. 資料庫程式設計
服務端支援plpgsql、python、java、r、javascript、perl、tcl 等開發語言
plpgsql與oracle pl/sql功能不相上下
2. sql相容性
3. 文法例子
with, connect by(用with支援), with, grouping set, rollup, cube
postgis、jsonb
sql plan hint、物化視圖、rls(行安全政策)
多種索引支援(btree, hash, brin, gin, gist, sp-gist, rum, bloom)
支援全文檢索、模糊查詢、正則比對(走索引)
資料類型豐富(常用類型、數組、範圍、估值類型、分詞、幾何、序列、地球、gis、網絡、大對象、比特串、位元組流、uuid、xml、jsonb、複合、枚舉、。。。。。。)
4. 支援oracle相容包插件
5. 支援插件、支援fdw(透明通路外部資料)、支援language擴充
6. 支援多個聚合函數共用sfunc,提升性能
7. 擴充能力
支援使用者自定義資料類型、操作符、索引、udf、視窗、聚合
服務端支援plpgsql、pljava等開發語言
内置豐富的函數、操作符、聚合、視窗查詢
多種索引支援(btree),支援函數索引,支援partial index
支援全文檢索、字元串模糊查詢(fuzzystrmatch)
資料類型豐富(數字、字元串、比特串、貨币、位元組流、時間、布爾、幾何、網絡位址、數組、gis、xml、json、複合、枚舉、。。。。。。)
支援oracle相容包插件orafunc
3. 支援列存、行存、混合存儲
4. 支援隐式并行計算
5. 支援機器學習庫
6. 支援支援oss_ext(透明通路oss對象資料)
7. 支援hll資料評估插件
8. 擴充能力
1. 計算能力
由于傳統資料庫,比如oracle并非mpp架構,在執行大資料量運算時,受制于硬體限制,對于10tb以上的olap場景很吃力。
1.1 解決辦法
postgresql 多cpu并行計算,解決tb級本地實時分析需求
postgresql 資料通過redo日志實時流式同步到hybriddb,解決pb級别olap場景需求。
2. 資料挖掘分析能力
由于傳統資料庫,比如oracle沒有機器學習套件,即使有,也受制于它的架構,無法發揮應對資料挖掘分析需求。
2.1 解決辦法
postgresql和hybriddb都内置了madlib機器學習庫,支援幾百種挖掘算法。
通過r,python服務端程式設計,支援更多的挖掘需求。
3. 擴充能力
3.1 解決辦法
postgresql fdw based sharding + multimaster,支援單元化和水準擴充需求
hybriddb mpp天然支援水準擴充
4. 可程式設計能力
4.1 解決辦法
postgresql, hybriddb 支援plpgsql, c, python, java等多種語言的服務端程式設計。
支援資料類型、索引、函數、操作符、聚合、視窗函數等擴充。
在dt時代,讓資料發揮價值是企業的真正需求,否則就是一堆廢的并且還持續消耗企業人力,财力的資料。
使用本方案,可以讓企業更加輕松的駕馭暴增的資料,不管是什麼資料類型,什麼資料來源,是流式的還是線上或離線的資料分析需求,統統都能找到合理的方法來處置。
1. 高度相容傳統資料庫,如oracle
包括資料類型,過程語言,文法,内置函數,自定義函數,自定義資料類型
2. 解決了傳統資料庫如oracle方案的痛點
3. 計算能力
4. 資料挖掘分析能力
5. 擴充能力
hybriddb mpp 天然支援水準擴充
6. 可程式設計能力
7. 支援估值類型
快速的輸出pv,uv,count(distinct)等估值。
8. 共享一份資料,建構多個分析執行個體
通常在企業中有分析師的角色,分析師要對資料頻繁的根據不同的分析架構進行分析,如果都發往主庫,可能導緻主庫的計算壓力變大。
使用者可以将曆史資料,或者次元資料存放到共用的存儲(如oss),通過fdw共享通路,一份資料可以給多個執行個體加載分析。可以為分析師配備獨立的計算執行個體,資料則使用fdw從共享存儲(如oss)加載,與主庫分離。
9. hybriddb優勢
支援ao列存,塊級壓縮,機器學習,混合存儲,mpp水準擴充,隐式并行,r,java服務端程式設計語言支援,pb級别資料挖掘需求。
postgresql是一個 "很有愛" 的資料庫,用心學習它,用心回報社會吧。
<a href="https://github.com/digoal/blog/blob/master/201612/20161228_01.md">《從天津濱海新區大爆炸、危化品監管聊聊 it人背負的社會責任感》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161230_01.md">《postgresql 重複 資料清洗 優化教程》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161231_01.md">《從難纏的模糊查詢聊開 - postgresql獨門絕招之一 gin , gist , sp-gist , rum 索引原理與技術背景》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161227_01.md">《從真假美猴王談起 - 讓套牌車、克隆x 無處遁形的技術手段思考》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161225_01.md">《恭迎萬億級營銷(圈人)潇灑的邁入毫秒時代 - 萬億user_tags級實時推薦系統資料庫設計》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161224_01.md">《dba專供 岡本003系列 - 資料庫安全第一,過個好年》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161223_01.md">《聊一下postgresql優化器 - in裡面有重複值時postgresql如何處理?》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161222_02.md">《從相似度算法談起 - effective similarity search in postgresql》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161222_01.md">《一場it民工 與 人販子 之間的戰争 - 隻要人人都獻出一點愛》</a>
<a href="https://github.com/digoal/blog/blob/master/201512/20151215_01.md">《"物聯網"流式處理應用 - 用postgresql實時處理(萬億每天)》</a>
<a href="https://github.com/digoal/blog/blob/master/201606/20160621_1.md">《為了部落 - 如何通過postgresql基因配對,産生優良下一代》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161220_01.md">《流計算風雲再起 - postgresql攜pipelinedb力挺iot》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161216_01.md">《分析加速引擎黑科技 - llvm、列存、多核并行、算子複用 大聯姻 - 一起來開啟postgresql的百寶箱》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161213_01.md">《金融風控、公安刑偵、社會關系、人脈分析等需求分析與資料庫實作 - postgresql圖資料庫場景應用》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161205_02.md">《實時資料交換平台 - bottledwater-pg with confluent》</a>
<a href="https://github.com/digoal/blog/blob/master/201611/20161126_01.md">《postgresql 在視訊、圖檔去重,圖像搜尋業務中的應用》</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161021_01.md">《基于 阿裡雲 rds postgresql 打造實時使用者畫像推薦系統》</a>
<a href="https://github.com/digoal/blog/blob/master/201611/20161124_02.md">《postgresql 與 12306 搶火車票的思考》</a>
<a href="https://github.com/digoal/blog/blob/master/201611/20161124_01.md">《門禁廣告銷售系統需求剖析 與 postgresql資料庫實作》</a>
<a href="https://github.com/digoal/blog/blob/master/201611/20161114_01.md">《聊一聊雙十一背後的技術 - 物流、動态路徑規劃》</a>
<a href="https://github.com/digoal/blog/blob/master/201611/20161115_01.md">《聊一聊雙十一背後的技術 - 分詞和搜尋》</a>
<a href="https://github.com/digoal/blog/blob/master/201611/20161117_01.md">《聊一聊雙十一背後的技術 - 不一樣的秒殺技術, 裸秒》</a>
<a href="https://github.com/digoal/blog/blob/master/201611/20161118_01.md">《聊一聊雙十一背後的技術 - 毫秒分詞算啥, 試試正則和相似度》</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161001_01.md">《postgresql 9.6 引領開源資料庫攻克多核并行計算難題》</a>
<a href="https://github.com/digoal/blog/blob/master/201609/20160929_02.md">《postgresql 前世今生》</a>
<a href="https://github.com/digoal/blog/blob/master/201609/20160906_01.md">《如何建立gis測試環境 - 将openstreetmap的樣本資料導入postgresql postgis庫》</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161004_01.md">《postgresql 9.6 單元化,sharding (based on postgres_fdw) - 核心層支援前傳》</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161005_01.md">《postgresql 9.6 sharding + 單元化 (based on postgres_fdw) 最佳實踐 - 通用水準分庫場景設計與實踐》</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161027_01.md">《postgresql 9.6 sharding based on fdw & pg_pathman》</a>
<a href="https://github.com/digoal/blog/blob/master/201610/20161024_01.md">《postgresql 9.5+ 高效分區表實作 - pg_pathman》</a>
<a href="https://github.com/digoal/blog/blob/master/201506/20150601_01.md">《postgresql 資料庫安全指南》</a>
<a href="https://github.com/digoal/blog/blob/master/201605/20160523_01.md">《postgresql 9.6 黑科技 bloom 算法索引,一個索引支撐任意列組合查詢》</a>
<a href="https://github.com/digoal/blog/blob/master/201607/20160725_01.md">《postgresql 使用遞歸sql 找出資料庫對象之間的依賴關系》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161203_01.md">《用postgresql描繪人生的高潮、尿點、低谷 - 視窗/幀 or 斜率/導數/曲率/微積分?》</a>
<a href="https://github.com/digoal/blog/blob/master/201612/20161201_01.md">《用postgresql找回618秒逝去的青春 - 遞歸收斂優化》</a>
<a href="https://yq.aliyun.com/articles/50922">《postgis 在 o2o應用中的優勢》</a>
<a href="https://yq.aliyun.com/articles/2999">《postgresql 百億地理位置資料 近鄰查詢性能》</a>