<b>2016-12-09 來源:infoq 作者:蕭少聰</b>
在大資料火遍it界之前,大家對資料資訊的挖掘通常聚焦在bi(business intelligence)之上。bi具有着明确的分析需求,清晰地知道需要處理哪些資訊,并且如何最終獲得多元度的sql類型資料,這種多元度的分析對應的是olap處理技術。在實際商業分析應用中,公司複雜資訊模型、多樣化的分析需求會給資料庫帶來極大的技術挑戰。
對于阿裡而言,實作olap、進行線上大規模并行處理,是一個無法規避的技術問題。為此,阿裡雲研發了hybriddb方案,它基于資料庫greenplum的開源版本,并且吸收postgresql精髓。那麼為什麼會有hybriddb的誕生?它經曆了怎樣的研發曆程?它的應用場景和情況是怎樣的?帶着這些問題,infoq對阿裡的資料庫專家蕭少聰先生進行了采訪,以下文字整理自采訪文稿。
資料庫領域中大家經常會看到兩個詞:oltp及olap。
舉例說明,比如進行一次交易,資金從a帳戶轉帳到b帳戶,這整個過程就是一次交易事務。如果過程中有任何系統錯誤,交易會復原a帳戶中的金額都回恢到操作前的狀态,這就是on-line transaction processing聯機事務處理過程(oltp)的操作。在oltp場景中使用者并發操作量會很大,要求系統實時進行資料操作的響應,在查詢時往往也是隻會檢索一條或幾條明确的目标資料,以實作使用者的業務互動。
olap意思是on-line analytical processing聯機分析處理,顧名思義就是主要針對于資料的分析彙總操作。如我們的業務系統中每天都需要出銷售日報,這個操作需要對當天所有資料進行彙總,并需要進行計算,以得到全天收入、産品銷售排名、分時段的銷售量,甚至與過去30天及去年當天進行對比,這樣的操作都屬于olap。
業界早期使用資料時,尤其是oltp場景下,通常選擇非分布式的關系型資料庫,如mysql、sqlserver、oracle、postgresql即可滿足大部份的需求。
從技術角度而言,olap場景,不僅涉及的資料量大而且要求分析的結果實時傳回,對應的sql查詢十分複雜。如何做到技術性能和業務功能權衡,對于資料庫而言是一個重大考驗。
已有的兩個主流開源資料庫,mysql和postgresql都是針對oltp環境的,在olap線上分析需求下它們的性能明顯不足。特别是mysql在大規模分析操作時多表join的性能是目前網際網路使用者的一大痛點。
在olap發展的早期,其操作并沒有專門的資料庫支撐,直接就與oltp業務放在同一個資料庫中完成。但随着業務量的增加,olap每次要分析的資料量越來越大,這樣的分析操作執行時就會導緻資料庫的業務交易下降。是以業界開始将oltp、olap拆分成兩套不同的資料庫進行處理,oltp資料庫中的資料通過etl軟體持續或定期抽取到olap資料庫,讓業務交易與報表分析進行分離。
而新的問題很快又到來了,聯互網爆發後資料量也激增,oltp的業務庫可以儲存比較少的資料量如3個月到半年,但olap的資料量将可能要儲存幾年甚至更多。單台服務服務的性能上限已經無法滿足olap分析資料持續增加所帶來的壓力,是以催生出如阿裡hybriddb這樣的大規模并行處理(massive parallel processing,mpp)分布式olap資料庫。
在提供hybriddb方案之前,我們會給使用者提供如分庫分表等處理方案,但這樣的方案對于sql查詢内容不确定的olap業務并不友好。當使用者需要進行多個資料表的組合操作時,由于資料需要跨伺服器進行大規模的聚合,性能十分低下。
這個問題在hybriddb中也同樣會出現,所幸的是,greenplum database開源項目中借助平行的資料擴充技術及interconnect的專用協定,通過自定義的網絡協定有效地解決了網絡瓶頸的問題。這也是我們選擇基于greenplum database開源項目的原因之一。
簡單來說,mpp是一種平衡的性能擴張模型。以hybriddb的模型為列,每個節點可存放的資料量及計算能力為1core / 8gb mem / 80gb ssd(即将開放500gb hdd版本),如果使用者80gb以内的資料在這樣的計算單元中,可以在毫秒内查詢出結果,那将資料計算能力及容量平衡擴充到上百tb甚至pb時,使用者查詢“等比”資料量時依然可以達到毫秒級别。
mpp分布式olap資料庫系統架構已經發展了有10多年之久,十分成熟,目前使用這類系統的企業都是中大型公司。olap是一個很大的市場,有别于如同emr(hadoop)的大資料分析市場,它要求海量資料的sql查詢在幾分鐘、幾秒,甚至毫秒級傳回結果,是以對于伺服器、網絡及資料庫軟體本身的架構都提出了很高的要求。
阿裡一直都在使用并研究olap,實際上在2009年左右開始使用greenplum,如果沒有記錯,那個時候的規模應該是國内甚至全亞洲最大的gpdb叢集。
研發之路并不是一帆風順,甚至一度突圍失敗。一方面,彼時greenplum還處在萌芽期,隻釋出了4年。另一方面,greenplum沒有開源,既無法掌握更為深入的資料,又不得不考慮價格因素。你可以想象阿裡所在行業對于資料可靠性的要求以及規模量,使得對于資料庫的選擇會有多個次元的考慮。
不過早期的經曆還是給我們留下了寶貴的經驗。當年的很多運維經驗我們都進行了收集,并在現有平台中變成了我們的監控項,通過自動化運維的手段進行資源調配及故障預警,這對我們平台的穩定性提供了很重要的經驗。
同時針對以前遇到的很多讓我們技術同學不了解的原理性問題,通過greenplum database的源代碼我們進行了重點分析,并找到了問題的答案。有很多之前遇到過的問題,通過源碼可以明确發現已經由廠商進行了修複,而有一些問題可能與我們的業務場景有關,結合源碼我們也進行了核心的優化。
2015年10月greenplum database由pivotal開源後,阿裡雲postgresql核心團隊便開始進行深度的調研,于2016年開始進行産品的研發工作,到今年7月份我們對使用者開放了公測邀請并準備正式商業化的工作。
生态:基于10年商業資料庫建立的生态是寶貴的财富,讓使用者的使用變得更為便捷。
成熟:經過我們深度的壓力測試(過程還是十分暴力的,在此不表^_^),我們驗證了greenplum本身的穩定性,同時gpdb提供豐富的sql支援、程式設計接口易于進行擴充,這些都展現了她的成熟度。
開源:隻有掌握源碼才可以協助使用者最快地解決問題,同時greenplum基于postgresql,基于這一點,使用者可以使用統一的postgresql的jdbc或.net驅動開發oltp及olap的軟體,減少不同資料庫協定之間的學習成本及研發複雜度。
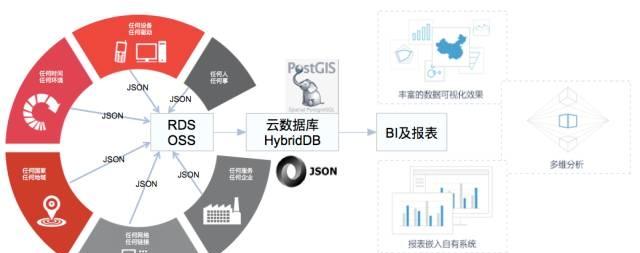
hybriddb基于開源greenplum database(核心實際上就是postgresql)項目的mpp分布式資料倉庫,與postgresql不同,hybriddb可以實作橫向擴充,提供使用者需要的百gb到百tb的高性能分析能力。接下來結合項目說明實際應用。
我們有一個廣告行業的使用者,他們給使用者提供線上的資料分析業務,同時也會将他們的産品進行線下私有環境的軟體售賣。每天他們都需要進行過億資料的彙總分析,增量資料也都在千萬級别,目前通過使用hybriddb進行他們線上業務的支援。
一些單表的查詢在毫秒級别就可以輸出結果,而很多需要多表join的複雜查詢也在數秒内就會有結果傳回。同時這個使用者給 hybriddb 提出 hyperloglog 的功能需求後,我們在2周内就給予了這個功能的支援,使得使用者在進行資料預估分析的操作性能提高幾十倍。與此同時使用者線上使用 hybriddb 開發的産品,也可以十分便捷地運作線上下的開源或商業版本的 greenplum 上,避免了在不同資料庫平台上需要重新開發應用系統的工作量。
在阿裡雲官網上,hybriddb 歸結在 “資料庫” 和 “分析” 兩個類目。阿裡内部已經有業務開始使用 hybriddb ,主要是看重它對sql的豐富支援,同時可以支援gis資料類型及基于事務一緻性的存儲過程。
<b>hybriddb最大的三個特色:</b>
基于成熟的gpdb及postgresql生态,軟開發合作夥伴進行一次軟體開發,即可在雲上雲下同樣使用,免去遷移的煩惱,更容易實作混合雲中的資料分析支援。
支援多種混合資料類型(多達23種)的sql統一查詢,包括:傳統資料類型:字元、數字、浮點、日期等;非結構化資料:json、xml;特殊功能資料類型:gis地理資訊資料、ipv4/v6網絡資料、hyperloglog預估分析資料。
支援混合的資料存儲,包括:行存、列存、ssd/hdd本地存儲、oss雲存儲,未來更将支援“存儲計算分離”,使用者可以更為靈活在進行資源的購買及配置設定。
<b>那麼,hybriddb在olap讀取中都做了哪些優化?</b>
優化方面從引擎底層我們針對阿裡雲的硬體及網絡特點,進行的源碼級别的深度優化,特别是在網絡排程上進行了針對性的處理,提高跨網絡資料節點的吞吐能力。同時在使用者業務層中對特殊資料類型進行擴充,如果物聯網中的json資料類型是greenplum database所不支援的,hybriddb通過直接支援這一資料類型,避免使用者自行進行非結果化的解析,同時提供基于函數的json屬性級索引,提高資料庫處理json的檢索性能。
<b>除此之外,hybriddb還有哪些新意?</b>
hybriddb是雲上的資料倉庫,使用者如果在自己的私有環境中進行類似架構的部署,将需要富有經驗的架構師進行完整的規劃,同時還要聘用高水準的技術團隊進行持續管理。因為如果系統出現故障無法提供服務,将很可能影響到企業的決策分析,對于以資料分析的基礎的企業甚至會導緻業務中斷,通過使用雲資料庫hybriddb将免除這些煩惱。
将mysql和postgresql資料導入到hybriddb的這個流程實際上并沒有很深的資料難度,因為mysql和postgresql都支援基于的邏輯日志,我們隻需要進行解析并入庫就可以了。
在資料導入方面,我們借助oss分布式資料存儲的能力,實作了多計算節點的并行導入,每個計算單元(1core/8gbmem為一個計算單元)可以達到接近20mb/s的資料導入,如果使用者建構出一個64節點的 hybriddb 叢集将可以達到1gb/s的資料導入能力。在我們的實際使用者使用中,已經有使用者通過這個方法在4分鐘内導入了4億條資料。另一方面hybriddb還支援将資料存放到oss雲存儲,實作廉價的資料存儲方案,為使用者節省更多成本。
<b>本地存儲</b>
hybriddb的本地存儲分為行儲存和列存儲兩種方式。行存儲和列存儲各有長處。行存适合于近線資料的分析,特别是要求查詢結果傳回表中某幾跳符合條件記錄的所有字段的情況。列存适合用于資料的統計分析。
那麼兩者的适用情況是怎樣的呢?舉例說明:在行存的情況下,如果一個用于存放使用者的表中有20個字段,但我們隻要統計使用者年齡的平均值,這時資料庫要對使用者表進行全表掃描,周遊所有行的所有資料;
但如果使用列存,資料庫隻要定位到這一列,然後隻掃描這一列的資料就可以得到所有的結果,性能上相比列存理論上就會直接快20倍,加上hybriddb将資料分布式存儲到多個計算節點,性能将再次提高幾倍,達到100倍性能提升是十分常見。
hybriddb是混合兩者搭配使用的。使用者可以配搭進行使用,定義不同的表使用不同的存儲方式,讓使用者适應不同的業務場景,并進行資料生态周期的管理。如6個月内的資料可能要經常擷取全行資料,是以使用行存儲,6個月後的資料通過列存儲進行儲存提高分析彙總操作的查詢性能。
<b>外部存儲</b>
高性能的資料分析是在本地存儲完成的。oss作為外部存儲,hybriddb可以将oss中的csv格式化文本作為外部表進行資料查詢,同時還可以對這些外部表進行寫入操作。寫入到oss的資料可以提供給rds for postgresql或emr等雲資料庫服務進行讀取及處理,是以也同時實作了資料的無縫打通。
同時我們也将支援“存儲計算分析”的模型,在這樣模型上我們平時甚至可以隻通過oss進行資料的存儲,當需要進行計算時再開啟足夠的計算節點進行資料分析處理,計算處理結束後關閉計算節點資源以節省使用成本。

<b>紮根社群</b>
在greenplum database的開源社群我們會有很多的合作,甚至我們已經在向開源社群送出新功能及patch。同時greenplum也是postgresql開源資料庫生态重要的力量,我個人同時作為postgresql中國社群及使用者會的主席也當然會進行更多線上線下活動的支援。
<b>商業合作</b>
greenplum背後的公司是pivotal。是以同時也與pivotal有更多的商業合作。阿裡也會與pivotal方面進行持續的接觸,相信我們會有機會碰出絢麗的火花。
長期以來國外開源社群都認為中國使用者僅僅使用開源軟體,但是貢獻甚少。不過,随着阿裡的發展,我們已經開始反哺開源社群并共同建立生态。幾個月前,alisql的開源說明了阿裡對開源業界的支援。hybriddb同樣如此,雖然我們的版本才剛剛釋出,但在版本研發的過程中已經開始向社群共享代碼。
阿裡雲目前支援雲資料庫hybriddb,暫時沒有計劃去支援私有環境的greenplum資料庫。不過我們團隊的大神德哥,會繼續貢獻他在使用greenplum的經驗心得。希望對大家有所幫助。
使用者線上下可以使用greenplum的開源資料庫版本或商業版本,據我所了解也已經有很多資料庫服務商開始提供greenplum的技術支援,使用這個資料庫的使用者不需要再擔心未來上雲遷移的問題。同時,我們也會在未來結合postgresql及hybriddb提供一系列的使用教學視訊,讓使用者更快速地掌握産品的正确使用場景及方法。
<a href="http://mp.weixin.qq.com/s/tqkb1eegihpbeqdsrquceg" target="_blank"><b>原文連結</b></a>