redis是一個key-value存儲系統。和memcached類似,它支援存儲的value類型相對更多,包括string(字元串)、list(連結清單)、set(集合)、zset(sorted set有序集合)和hash(哈希類型)。這些資料類型都支援push/pop、add/remove以及取交集并集和差集及更豐富的操作,而且這些操作都是原子性的。
本文将對redis資料的編碼方式和底層資料結構進行分析和介紹,幫助讀者更好的了解和使用它們。
redis中資料對象的定義如下:
其中type對應了redis中的五種基本資料類型:
encoding則對應了 redis 中的十種編碼方式:
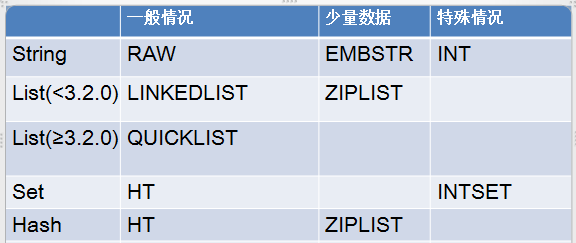
type和encoding的對應關系如下圖:
raw編碼方式使用簡單動态字元串來儲存字元串對象,其具體定義為:
從len字段可以判斷并不不依賴于'0',故可以用與儲存二進制對象。
從free字段可以判斷其空間配置設定是采用預配置設定的方式,避免字元串修改時頻繁配置設定釋放記憶體。具體配置設定算法為:
int編碼方式以整數儲存字元串資料,僅限能用long類型值表達的字元串。
當robj中的lru值沒有意義的時候(執行個體沒有設定maxmemory限制或者maxmemory-policy設定的淘汰算法中不計算lru值時), 0-10000之間的obj_encoding_int編碼的字元串對象将進行共享。
具體算法如下:
從redis 3.0版本開始字元串引入了embstr編碼方式,長度小于obj_encoding_embstr_size_limit的字元串将以embstr方式存儲。
embstr方式的意思是 embedded string ,字元串的空間将會和redisobject對象的空間一起配置設定,兩者在同一個記憶體塊中。
redis中記憶體配置設定使用的是jemalloc,jemalloc配置設定記憶體的時候是按照8,16,32,64作為chunk的機關進行配置設定的。為了保證采用這種編碼方式的字元串能被jemalloc配置設定在同一個chunk中,該字元串長度不能超過64,故字元串長度限制obj_encoding_embstr_size_limit = 64 - sizeof('0') - sizeof(robj)為16 - sizeof(struct sdshdr)為8 = 39。
采用這個方式可以減少記憶體配置設定的次數,提高記憶體配置設定的效率,降低記憶體碎片率。
連結清單(list),哈希(hash),有序集合(sorted set)在成員較少,成員值較小的時候都會采用壓縮清單(ziplist)編碼方式進行存儲。
這裡成員"較少",成員值"較小"的标準可以通過配置項進行配置:
壓縮清單簡單來說就是一系列連續的記憶體資料塊,其記憶體使用率很高,但增删改查效率較低,是以隻會在成員較少,值較小的情況下使用。
其典型結構如下:
在redis 3.2版本之前,一般的連結清單使用linkdedlist編碼。
在redis 3.2版本開始,所有的連結清單都是用quicklist編碼。
兩者都是使用基本的雙端連結清單資料結構,差別是quicklist每個節點的值都是使用ziplist進行存儲的。
整數集合(intset)是集合鍵的底層實作之一:
當一個集合隻包含整數值元素, 并且這個集合的元素數量不多時, redis 就會使用整數集合作為集合鍵的底層實作。
字典是redis中存在最廣泛的一種資料結構不僅在哈希對象,集合對象和有序結合對象中都有使用,而且redis所有的key,value都是存在db->dict這張字典中的。
redis 的字典使用哈希表作為底層實作。
一個哈希表裡面可以有多個哈希表節點,而每個哈希表節點就儲存了字典中的一個鍵值對。
哈希表的定義如下:
redis計算hash值和索引的方式為:
一個字典裡面儲存了兩個hash表結構,用于哈希表的擴充收縮操作(rehash)。
随着操作的不斷執行,哈希表儲存的鍵值對會逐漸地增多或者減少,為了讓哈希表的負載(used/size)維持在一個合理的範圍之内,當哈希表儲存的鍵值對數量太多或者太少時,程式需要對哈希表的大小進行相應的擴充或者收縮。
具體算法為:
為字典的 ht[1] 哈希表配置設定空間,這個哈希表的空間大小為:
第一個大于等于(擴充時)或者小于等于(收縮時) ht[0].used * 2 的 2^n(2 的 n 次方幂);
将儲存在 ht[0] 中的所有鍵值對 rehash 到 ht[1] 上面:rehash指的是重新計算鍵的哈希值和索引值,然後将鍵值對放置到 ht[1]哈希表的指定位置上;
當 ht[0] 包含的所有鍵值對都遷移到了 ht[1] 之後(ht[0] 變為空表),釋放 ht[0] ,将 ht[1] 設定為 ht[0],并在 ht[1] 新建立一個空白哈希表,為下一次 rehash 做準備。
一次性完成 rehash 過程時間可能很長,redis采用漸進式 rehash 的方式完成整個過程。
每次對字典執行添加、删除、查找或者更新操作時,程式除了執行指定的操作以外,還會順帶将 ht[0] 哈希表在 rehashidx 索引上的所有鍵值對 rehash 到 ht[1] , 并将 rehashidx 的值增一;
直到整個 ht[0] 全部完成 rehash 後,rehashindex設為-1,釋放 ht[0] , ht[1]置為 ht[0], 在 ht[1] 建立一個新的空白表。
跳躍表(skiplist)編碼方式為有序集合對象專用,有序集合對象采用了字典+跳躍表的方式實作。其定義如下:
其中字典裡面儲存了有序集合中member與score的鍵值對,跳躍表則用于實作按score排序的功能。
跳躍表以有序的方式在階層化的連結清單中儲存元素,在一般情況下情況下效率和平衡樹媲美, 比起平衡樹來說,跳躍表的實作要簡單直覺得多。
一般的跳躍表結構如下圖所示:

跳躍表的基本原理是每一個節點建立的時候層數為随機值,層數越高的幾率越小,redis中每升高一層的機率為1/4。也就是說,一個跳躍表裡,一般情況下,每一層的節點數為下一次的 1/4,相當于是一個“随機化”的平衡樹。
具體的算法在此就不詳細贅述了,與一般的跳躍表實作相比,有序集合中的跳躍表有以下特點:
允許重複的 score 值:多個不同的 member 的 score 值可以相同。
進行對比操作時,不僅要檢查 score 值,還要檢查 member:當 score 值可以重複時,單靠 score 值無法判斷一個元素的身份,是以需要連 member 域都一并檢查才行。
每個節點都帶有一個高度為1層的後退指針,用于從表尾方向向表頭方向疊代:當執行 zrevrange 或zrevrangebyscore這類以逆序處理有序集的指令時,就會用到這個屬性。
知其然,更要知其是以然。
隻有深入了解了redis資料的編碼方式和底層資料結構,我們才能更好的了解使用它。在做疑難問題分析和業務優化時,才能更加有的放矢。