上次在做内部教育訓練的時候,我講了這麼一句:
<b>一個job裡的stage都是串行的,前一個stage完成後下一個stage才會進行。</b>
顯然上面的話是不嚴謹的。
看如下的代碼:
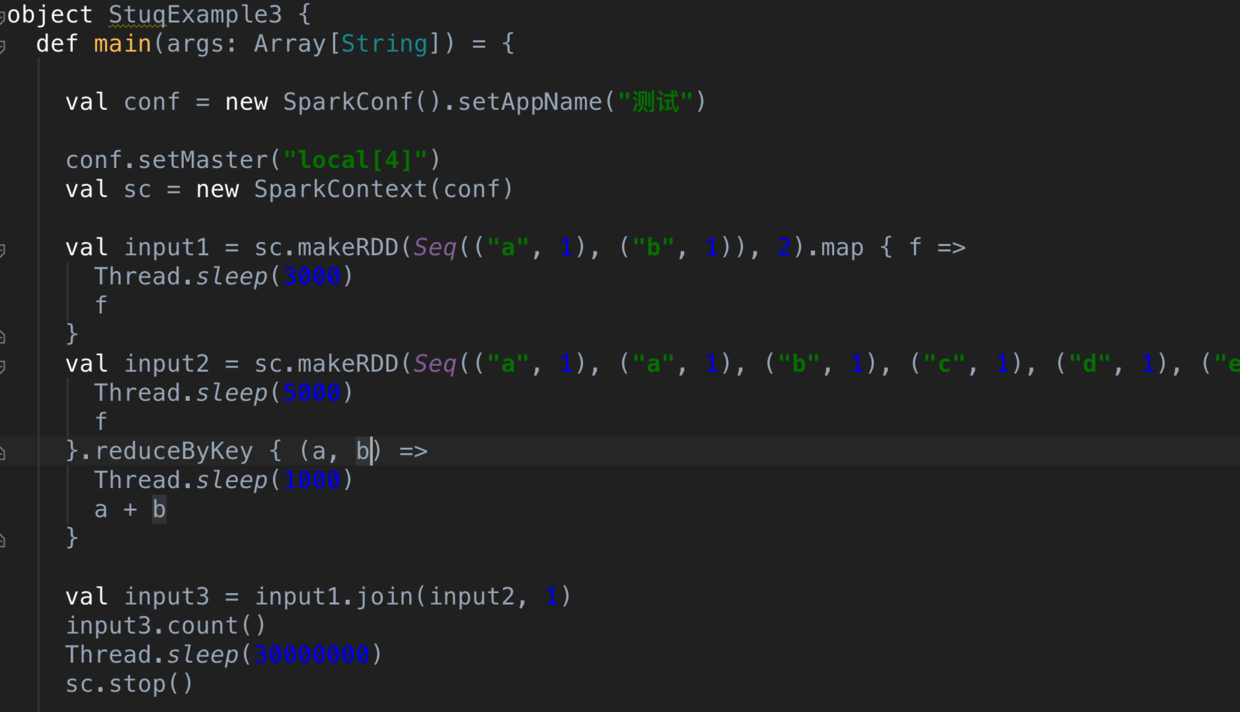
snip20160903_17.png
這裡的話,我們建構了兩個輸入(input1,input2),input2帶有一個reducebykey,是以會産生一次shuffle,接着進行join,會産生第二次shuffle(值得注意的是,join 不一定産生新的stage,我通過強制變更join後的分區數讓其發生shuffle ,然後進行stage的切分)。
是以這裡一共有兩次shuffle,産生了四個stage。 下圖是spark ui上呈現的。那這四個stage的執行順序是什麼呢?

snip20160903_11.png
再次看spark ui上的截圖:
snip20160903_16.png
我們仔細分析下我們看到現象:
首先我們看到 stage0,stage 1 是同時送出的。
stage0 隻有兩條記錄,并且設定了兩個partition,是以一次性就能執行完,也就是3s就完成了。
stage1 有四個分區,六條記錄,記錄數最多的分區是兩條,也就是需要執行10秒,如果完全能并行執行,也就是最多10s。但是這裡消耗了13秒,為什麼呢?點選這個13秒進去看看:
snip20160903_15.png
我們看到有兩個task 延遲了3秒後才并行執行的。 根據上面的代碼,我們隻有四顆核供spark使用,stage0 裡的兩個任務因為正在運作,是以stage1 隻能運作兩個任務,等stage0 運作完成後,stage1剩下的兩個任務才接着運作。
之後stage2 是在stage1 執行完成之後才開始執行,而stage3是在stage2 執行完成才開始執行。
現在我們可以得出結論了:
stage 可以并行執行的
存在依賴的stage 必須在依賴的stage執行完成後才能執行下一個stage
stage的并行度取決于資源數
我麼也可以從源碼的角度解釋這個現象:
snip20160903_18.png
我們看到如果一個stage有多個依賴,會深度便利,直到到了根節點,如果有多個根節點,都會通過submitmissingtasks 送出上去運作。當然spark隻是嘗試送出你的tasks,能不能完全并行運作取決于你的資源數了。
這裡再貢獻一張畫了很久的示意圖,展現了partition,shuffle,stage,rdd,transformation,action,source 等多個概念。