之前有說過要設計一個工作流排程器。開發一個完善的工作流排程器應該并不是一件簡單的事情。但是通過spark streaming(基于transfomer架構的理念),我們可能能簡化這些工作。我在這塊并沒有什麼經驗,這隻是一個存在于腦海中的東西。
下面是azkaban的架構圖:
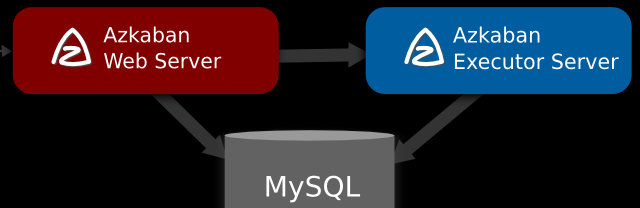
也就是說要搭建一個穩定可靠的azkaban的工作流排程器,你可能需要
兩台 互為主備mysql
兩台executor server
一台web server
你需要做架構設計,考慮webserver 和 executor server的通訊問題
擴充性問題。executor 能夠動态調整?
穩定性問題。畢竟24小時運作的
然而,我們其實是不需要關注這麼多東西的。我們真正關注的是:
web ui
工作流的生成,解析,運作和存儲
實作業務邏輯,也就是工作流的生成,解析,運作和存儲等操作。
實作管理頁面邏輯
指定需要的資源cpu/記憶體,就能run起來這個transformer
我搜羅了一圈,發現spark streaming 是能夠滿足該需求的一個estimator。
這得益于,spark streaming 從某個角度而言就是個定時任務排程系統,也就是我們說的微批處理。對于工作流排程器而言,無非就是每個周期(duration)在driver端啟動線程掃描mysql,實作任務的分發和執行。
那如果實作一個類似azkaban 能夠的做的事情,前面我們提到,要做三件事情,分别對應為:
實作業務邏輯,也就是工作流的生成,解析,運作和存儲等操作。其中生成,解析,存儲 三個環節可以放在driver端,也可以都放在executor 端。也就是說:driver的設計可重可輕。重的設計可由driver讀取mysql 并且解析成工作流任務,然後發送給executor 去執行。輕的設計driver僅僅是讀取mysql,然後就簡單将id分發給各個executor,各個executor 負責解析執行和回報結果。
增強 spark streaming ui,添加管理頁面,實作azkaban web server類似界面。
按标準的spark streaming 程式送出該實作到叢集即可完成部署。
我們看到,我們真正做到了隻關注核心業務邏輯的實作,所謂部署,安裝,運作等環節都實作了平台化(其實estimator完成了)。 而且實作了資源的細粒度(cpu/記憶體)劃分,而不再是以伺服器為基本單元。
事實上,我們也可以将一個spark streaming當做一個crontab 任務,這樣就自然具有了一個分布式的crontab系統,并且提供更友好的管理,甚至能将任務本身融入到crontab中。
spark streaming 不一定是最合适的estimator,你可以自己實作一套類似的estimator,最終形成所謂的 azkaban on yarn的程式。
![資料遷移方法資料遷移原則資料遷移之雙寫方案資料遷移之級聯同步方案[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)