如果有這樣的一個需求:master 有3個庫a,b,c ,d,由于某種原因,現在需要将其中2個庫b,c單獨拆分出來,單獨一個執行個體。 如果是你,打算怎麼做呢? 常見的做法就是,單獨搭建一個隻有b,c庫的執行個體,然後隻複制master的b,c庫,過濾掉a,d庫。那麼複制過濾就應運而生了,replicate-*-do-db/table 等。
為了搭建這一套環境(隻複制master的b,c庫),部分人會在my.cnf中這樣配置:
當然,按照大家的慣性思維,認為這樣是沒有錯的。不幸的是,災難已經來臨。
官方文檔:
mysql 會認為<code>b,c</code> 為一個庫名,而不是2個庫。
然而,這裡不僅僅有一個複制過濾參數,一共包括:
這裡面可以随意組合,且不同組合有不同的含義,為了徹底搞清楚他們直接的關系,下面我們一起來一窺究竟。
注意1:庫級别的規則,隻針對binlog_format='statement or mixed‘ 注意2:如果是binlog_format=‘row’,不受庫級别規則限制,隻受表級别規則限制。
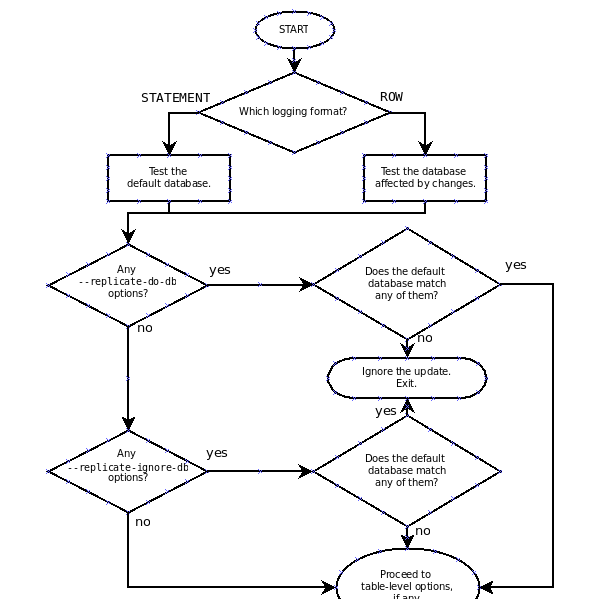

注意: 以下測試和結論,前提都是row_format='mixed'
在db level 中,當binlog-format=statement 時,過濾以use db為主(不允許跨庫)。為rows模式是:不以use db為主(允許跨庫)
不管binlog格式是statement,還是rows模式,table level的判斷都是 不以use db為主(可以跨庫的)
總的流程走向:先判斷db-level,如果db-level 判斷完成後需要exit,則退出。如果db-level判斷完成後,沒有exit,則再判斷table-level
在db-level中,如果有replicate-do-db,則判斷replicate-do-db,将不會走到replicate-ignore-db這層。 如果判斷replicate-do-db符合條件,則判斷table-level。 如果不符合,則exit
在db-level中,如果沒有replicate-do-db,但是有replicate-ignore-db。 流程則是:符合replicate-ignore-db規則,則exit,不符合,則走到table-level層繼續判斷
在table-level中,判斷邏輯順序自上而下為:replicate-do-table -> replicate-ignore-table -> replicate-wild-do-table -> replicate-wild-ignore-table
在table-level中, 從第一個階段(replicate-do-table)開始,如果符合replicate-do-table判斷規則,則exit。如果不符合,則跳到下一層(replicate-ignore-table)。 然後以此内推,直到最後一層(replicate-wild-ignore-table)都不符合,則最後判斷是否有(replicate-do-table or replicate-wild-do-table),如果有,則ignore & exit。如果沒有,則execute & exit
說明:以下測試,均以statement格式為例。 rows模式參見原理同樣可以證明,這裡就不解釋。
第一種情況:設定replicate_do_db=a,b
do-db
ignoare-db
do-db & ignore-db
do-table
ignore-table
wild-do-table
wild-ignore-table
do-table & ignore-table
do-table & wild-ignore-table
wild-do-table & wild-ignore-table
do-db & do-table
do-db & wild-do-table
do-db & ignore-table
do-db & wild-ignore-table
最常見場景: db-db & do-ignore-db & wild-do-table & wild-ignore-table
實戰: wild-do-table & ignore-table & wild-ignore-table
由于組合太多,就不一一列舉。
以上情況,還可以衍生出各種場景群組合,隻要弄懂了原理,基本都沒有問題。