如何評估query的響應時間?
需要買什麼樣的硬體能滿足為了業務xxx的需求?
這種問題在企業中非常常見,但是估計大多數是拍腦袋的回複,做得更好點,可能是根據業務的benchmark提供的資料,給一個拍腦袋的決定。
本文将針對資料庫的query展開,看看應該如何正确的評估query的響應時間。
對于資料庫來說,比如postgresql,支援非常多的access method,以及非常多的運算路徑和方法。
每種方法或路徑都有對應的成本評估算法。
算法可參考
src/backend/optimizer/path/costsize.c
不同的path,算法不同,算法中的因子也各不相同。
例如,全表掃描path,成本取決于需要掃描的塊的多少,掃描每個塊的成本;以及需要擷取的記錄數的多少,擷取每條記錄需要消耗的成本是多少。
評估query的響應時間,與資料庫優化器評估cost的道理是想通的。
你可以參考一下文檔,planner如何使用統計資訊評估path成本,裡面有很多例子。
<a href="https://www.postgresql.org/docs/9.5/static/planner-stats-details.html">https://www.postgresql.org/docs/9.5/static/planner-stats-details.html</a>
一張業務表有15個字段,平均行長度為100位元組,其中有一個pk字段為int類型,當資料量達到10000億時,使用pk查詢1條記錄需要多久的響應時間?
這個場景其實蠻簡單的,就是基于pk的查詢。
執行計劃也很簡單
按照索引掃描的path,成本分為
掃描索引塊的成本
掃描heap塊的成本
索引 get tuple cpu成本
heap get tuple cpu成本
基于pk的掃描,相比io的成本,cpu的成本幾乎可以忽略。
是以我們隻需要評估出需要掃描多少個資料塊,就可以大緻評估出query需要多長時間。
以b-tree索引掃描為例,如下
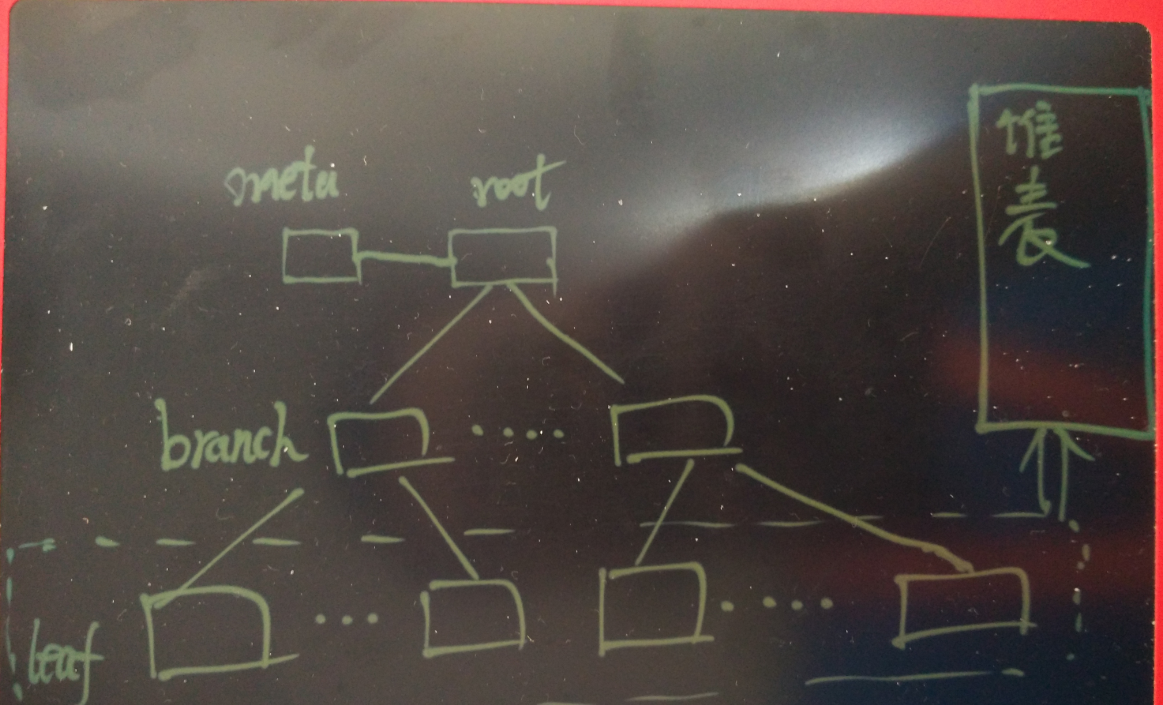
b-tree和b+tree
<a href="https://yq.aliyun.com/articles/54437">https://yq.aliyun.com/articles/54437</a>
深入淺出postgresql b-tree索引結構
<a href="https://yq.aliyun.com/articles/53701">https://yq.aliyun.com/articles/53701</a>
1. 評估單個索引頁的item數
b-tree索引頁,除了固定的頭和尾部資訊,剩下的就是value+ctid。
ctid為6個位元組,value則由列的類型決定。
例如int類型的索引,一個索引條目的大小=4+6=10位元組,每個條目還需要加上一些條目的head。
一個8k的資料塊,除掉頭部和尾部,可能能存下約400個條目。
2. 評估索引深度
一個頁的索引條目數固定了之後,就可以算出每個深度最多能支援的記錄數了。
以上面case為例, 隻有root page的索引,隻能存下400條。
2級索引則能存下400^2 的記錄數。
以此類推。
3. 評估索引掃描的掃描塊數
如果是pk查詢,索引掃描要掃描的塊數=metapage + level + heap page.
例如深入為2的索引,需要掃描4個塊。
4. 評估時間
因為索引都是離散的塊,離散掃描的時延完全由塊裝置決定。
例如機械盤的時延約等于8毫秒,掃描4個塊就是32毫秒。
ssd的掃描時延相比機械盤則很低。
回到前面的場景, 一張業務表有15個字段,平均行長度為100位元組,其中有一個pk字段為int類型,當資料量達到1萬億時,使用pk查詢1條記錄需要多久的響應時間?
評估索引層級
8kb 的塊,5級索引即可滿足 1萬億 的記錄數。
即使為機械盤,這類掃描的成本也隻需要56毫秒。
如果考慮分區表,假設每1000萬一個分區,則隻需要3級索引,40毫秒可以滿足需求。
其他的query,同樣也需要從執行計劃入手,評估出需要掃描的記錄數,以及需要掃描多少資料塊。 進而推算出需要的時間。
可能還有人會問,為什麼評估出來的query隻需要幾十毫秒,但是在生産中需要秒級傳回?
因為前面的評估是不考慮并發的,考慮并發的情況下,就會遇到資源争搶的問題,例如機械盤提供的iops有限,遇到争搶,等待的時間也要算上去。 并發達到100時,有些query可能就要等待上秒的時間了。
是以對于活躍資料非常龐大,又需要低延遲響應的場景,還是考慮ssd吧。
對于b+tree, 如innodb引擎,因為資料和索引值是在一棵樹裡面的,雖然隻在最下面一層存儲,但是也不可避免的造成一個page存儲的條目更加有限,比如一條記錄500位元組,8k的塊最多能存儲10幾條記錄,這樣的話1萬億需要7級索引。 前5級存儲400每頁,最後一級存儲18每頁。
通路7個資料塊,定位到一條記錄。
祝大家玩得開心,歡迎随時來 阿裡雲促膝長談業務需求 ,恭候光臨。
阿裡雲的小夥伴們加油,努力 做好核心與服務,打造最貼地氣的雲資料庫 。
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)