本文首先對物聯網進行了模型抽象,着重和大家剖析了mongodb解決方案,包括文檔模型、高可用複制集、分片叢集和aggregation&mapreduce,最後分享了全新的mongodb特性。
以下為内容整理:
mongodb是文檔型資料庫,其核心的三大優勢是靈活文檔模型 、高可靠複制集、 高可擴充分片叢集。在最新的
db engine rank 的排名中,mongodb 排在第4,是非關系型資料庫領域的領頭羊。
<b>物聯網模型抽象</b>
物聯網離我們越來越近,這主要得益于雲計算和移動網際網路技術的發展。物聯網技術已經應用于智能家居、車聯網等領域,我們進行模型抽象出物聯網應用的共性,很多裝置(assets)通過智能的傳感器采集很多資料并發到雲端,這些裝置不斷的産生日志、資料、事件并發到雲端,資料在雲端進行存儲計算後,會産生很多結果以接口的形式提供出去,友善我們開發更多的手機app和web應用。
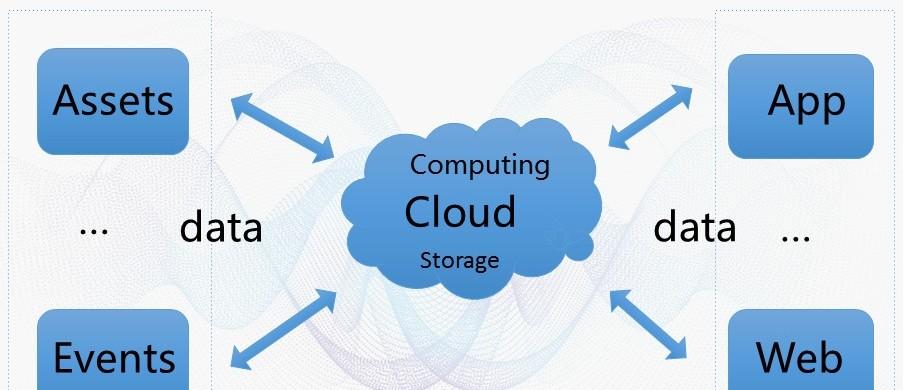
<b>物聯網存儲需求</b>
<b></b>

mongodb 解決方案
文檔模型
<b>json </b><b>格式</b>
json格式的好處:
最接近真實對象模型,對開發人員友好。
schema free,增加和删除字段非常靈活,直面靈活多變的需求,快速疊代。
數組、内嵌文檔支援,資料聚集,讀寫性能提升。
應用場景比如裝置增加新特性;事件日志,數組+内嵌文檔。
<b>schema free</b>
随時動态增加字段如圖。
增加字段無需變更表結構。
在mongodb3.2版本推出了文檔校驗,使其兼備靈活和嚴禁的特性。
<b>内嵌</b>
使用mongodb可以把所有的記錄作為這個裝置的元素,以數組的形式存儲起來,還可以劃分,把每分鐘彙報按小時為機關聚合存儲,這樣可以達到更少的文檔、更快的查詢。
<b>gridfs</b>
mongodb 單個文檔不能超過16mb,更大的文檔可以使用 gridfs 來存儲,例如物聯網裡 ota 更新檔案、圖檔視訊等的存儲。
gridfs原理:
檔案内容分成多個文檔存儲在fs.chunks集合。
檔案元資訊存儲在fs.files集合。
功能支援
<b>資料壓縮</b>
mongodb3.0之後推出了新的存儲引擎wiredtiger,wiredtiger存儲引擎對資料的壓縮支援非常好,使用者原來自建的mongodb使用 mmapv1,遷到雲上後換成wiredtiger,磁盤的容量通常能下降到原來的10%-30%。
mongodb對索引的支援非常豐富,下面重點介紹物聯網場景裡經常被使用到的位置索引和ttl索引,位置索引可用于建構各種基于地理位置的應用,而 ttl 索引可以實作裝置曆史資料自動過期的功能。
<b>位置索引</b>
mongodb的位置索引可以針對一個字段,mongodb支援兩種類型的位置索引字段,點和更靈活的位置,隻要字段是這種資料結構,就可以建立位置索引。建立位置索引後,就可以使用mongodb的near和geowithin查詢操作服務。
<b>ttl </b><b>索引</b>
因為後端的存儲資料有限,隻能存儲最近的資料,我們可以讓mongodb支援讓指定資料在某段時間後過期。
ttl索引有兩種應用模式:指定某段時間後過期和指定時間戳過期。mongodb對ttl索引的支援是有限制的,針對date類型字段建索引。mongodb在執行ttl索引時,背景過期邏輯每分鐘執行一次。
高可用複制集
高可用複制集特性如下:
自動故障檢測,自動failover
資料多副本存儲,保證資料安全
多節點可同時提供讀服務
以三節點複制集為例,會有一個primary和兩個secondary,複制集裡的所有成員通過選舉協定選出primary,預設情況下,所有資料都是寫到primary且隻能通過primary寫,讀也是通過primary來讀。三節點資料存儲三份,可以容忍兩個副本失效,保證了資料的高可靠。當primary挂掉後,另外兩個secondary會發起新選舉,保證服務正常進行。
<b>連接配接通路</b>
mongodb裡面有connection string uri,所有driver都支援connection string uri方式連接配接,這個通用的連接配接串包含通路mongodb的使用者密碼資訊,可以指定多個節點的位址,可以指定鑒權資料庫的資訊。通過這種方式,隻要在這個連接配接串裡指定後端多個節點或指定 replicaset 參數,正确連接配接複制集後,使用者用戶端連接配接到這個複制集後,會跟複制集的每一個成員建立一個心跳關系,會不斷的監測後端複制內建員的變化情況,當後端出現主備切換時,driver 能自動感覺。
<b>writeconcern</b>
mongodb通過writeconcern保證資料高可靠,預設情況下,mongodb 使用{w: 1}的 writeconcern 級别,當資料寫到 primary 就像用戶端傳回。對于非常重要的資料,可在寫入時設定writeconcern: { w: “majority”},就會寫到後端複制內建員的大多數,再向用戶端傳回,保證資料在有節點當機時也能不丢失。
<b>readpreference</b>
mongodb通過readpreference實作讀寫分離,可以指定讀寫對象。
可擴充分片叢集
可擴充分片叢集可以實作海量資料存儲、高并發寫入,例如物聯網裡大量裝置彙報的日志資料。
mongodb為了實作分片叢集,引入了兩個新的元件mongos和config servers,config servers存儲分片叢集的中繼資料。首先配置好某個集合,按照某個key進行分片,接下來一條寫請求就會到mongos上,mongos去config servers上查詢路由表,把請求路由到後端的分片上,就實作了分片叢集的功能。
<b>shardkey</b>
mongodb支援範圍分片,每一個範圍在mongodb的分片叢集裡成為一個chunk,每一個chunk就會分到後面的shard上,優點是能很好的支援範圍查詢需求。
mongodb支援hash分片,針對key先計算一次hash值,再根據hash值進行範圍分片,優點是能均勻的将寫請求分散到不同的分片。
選擇集合的 shardkey 時并沒有一個很完美的方案,需要使用者根據資料分布特性、請求特性來選擇最優的 shardkey,使用時應該盡量避免以下三個問題:
key 基數太小造成 jumbo chunk
寫入分布不均,造成熱點
scatter/gather 查詢影響效率
<b>負載均衡</b>
mongodb在mongos中有balancer的任務,會周期性的掃描每個shard目前負責的chunk的數量,balancer根據shard持有的chunk數量自動負載均衡,balancer
運作時,要盡量主要如下2個問題。
合理設定 balancer 視窗,避開業務通路高峰期
備份時關閉 balancer,避免出現資料不一緻的狀态
資料分析
<b>内建支援</b>
aggregation
pipeline支援很多的運算符,傳統關系型資料庫單表能做的aggregation pipeline都可以做;mongodb支援mapreduce,可以在mongodb的集合上寫mapreduce的任務,資料分析後,又寫回mongodb。
<b>外部架構</b>
通過mongodb spark connector,可直接在mongodb資料集上運作 spark ,與阿裡雲 e-mapreduce 完美結合。
mongodb 雲資料庫
<b>雲資料庫全鍊路監控</b>
圖為内部全鍊路監控視圖,可以精确的看到雲資料庫的每一個用戶端的每一個連接配接,可以看到上行下行的帶寬,請求速率,丢包率等,這對于查找線上問題是非常友善的。
<b>mongodb </b><b>核心優化</b>