1.資料挖掘的基本任務
資料挖據的基本任務包括利用分類與預測、聚類分析、關聯規則、時序模式、偏差檢驗、智能推薦等方法,幫助企業提取資料中蘊含的商業價值,提高企業的競争力。
2.資料挖掘的過程
2.1 定義資料挖掘目标
(1) 分析挖掘使用者資料,建立使用者畫像與物品畫像等
(2) 基于使用者畫像實作動态商品智能推薦,幫助使用者快速發現自己感興趣的商品,同時確定給使用者推薦的也是企業所期望的,實作使用者與企業的雙赢。
(3) 對平台客戶進行群體細分,了解不同客戶的貢獻度與消費特征,分析哪些客戶是最有價值的,哪些是需要重點的,對不同價值的客戶采取不同的營銷政策,将有限的資源投放到最有價值的客戶身上,實作精準化營銷。
(4) 基于商品的曆史銷售情況,綜合節假日、氣候和競争對手等影響因素,對商品銷售量進行趨勢預測,友善企業準備庫存。
2.2 資料抽樣
2.3 資料預處理
2.4 挖掘模組化
2.5 模型評價
3.常用的資料挖據模組化工具
3.1 sas enterprise miner
(1) 資料擷取工具
(2) 資料抽樣工具
(3) 資料篩選工具
(4) 資料變量轉換工具
(5) 資料挖據資料庫
(6) 資料挖掘過程
(7) 多種形式的回歸工具
(8) 為建立決策樹的資料剖分工具
(9) 決策樹浏覽工具
(10) 人工神經元網絡
(11) 資料挖據的評價工具
在sas/em中,可利用具有明确代表意義的圖形化的子產品将這些資料挖掘工具單元組成一個資料流程圖,并以此來組織你的資料挖掘過程。對于有經驗的資料挖掘專家,sas/em提供大量的選項,可讓有經驗的資料分析人員進行精細化調整分析處理。
3.2 ibm spss modeler
3.3 python
3.4 sql server
3.5 rapidminer
3.6 weka
3.7 knime
knime是一個基于eclipse平台開發,子產品化的資料挖掘系統。它能夠讓使用者可視化建立資料流(也就常說的pipeline),選擇性的執行部分或所有分解步驟,然後通過資料和模型上的互動式視圖研究執行後的結果。可以擴充使用weka中的算法,同時knime也提供基于資料流的方式來組織資料挖掘過程,每個節點都有資料的輸入/輸出端口,用接收或輸出計算結果。
3.8 tipdm
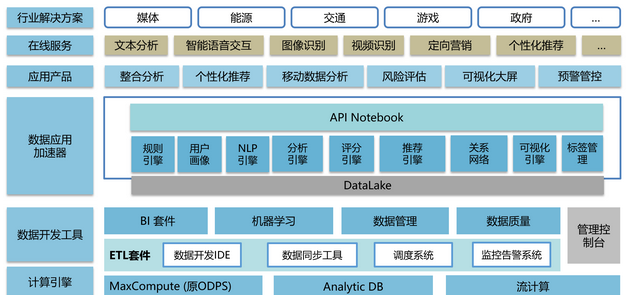
4.數加平台
數加的生态體系組成如下:
![筆試面試題目:滑動視窗(二)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)