最近在學習使用阿裡雲的推薦引擎時,在使用的過程中用到很多推薦算法,是以就研究了一下,這裡主要介紹一種推薦算法—基于物品的協同過濾算法。
itemcf算法不是根據物品内容的屬性計算物品之間的相似度,而是通過分析使用者的行為記錄來計算使用者的相似度。該算法認為物品a和物品b相似的依據是因為喜歡物品a的使用者也喜歡物品b。
基于物品的協同過濾算法實作步驟:
1、計算物品之間的相似度
2、根據物品的相似度和使用者的曆史行為記錄給使用者生成推薦清單
下面我們一起來看一下這兩部是如何實作的:
一、計算物品之間的相似度
通過查詢一下資料,itemcf的物品相似度計算模型如下:
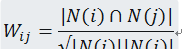
公式中|n(i)|表示喜歡物品i的使用者數,|n(j)|表示喜歡物品j的使用者數, |n(i)∩n(j)|表示同時喜歡物品i和物品j的使用者數。從上面的公式我們可以看出物品i和物品j相似是因為他們共同别很多的使用者喜歡,相似度越高表示同時喜歡他們的使用者數越多。
下面舉例講解一下相似度的計算過程:
假設使用者a對物品a,b,d有過評價,使用者b對物品b,c,e有過評價,如下圖:
a : a b d
b : b c e
c : c d
d : b c d
e : a d
根據上面使用者的行為建構:使用者——物品倒排表:例如:物品a有使用者a和e做過評價。
a : a e
b : a b d
c : b c d
d : a c d e
e : b
根據上面的倒排表我們可以建構一個相似度矩陣:

圖 1.1 計算物品的相似度
圖中最左邊的是使用者輸入的使用者行為記錄,每一行代表使用者感興趣的物品集合,然後對每個物品集合,我們将裡面的物品兩兩加一,得到一個矩陣。最終将這些矩陣進行相加得到上面的c矩陣。其中ci記錄了同時喜歡物品i和j的使用者數。這樣我們就得到了物品之間的相似度矩陣w。
二、根據物品的相似度和使用者的曆史行為記錄給使用者生成推薦清單
itemcf通過下面的公式計算使用者u對一個物品j的興趣:
這裡的n(u)代表使用者喜歡的物品的集合,s(j,k)是和物品j最相似的的k個物品的集合,wij是物品j和i的相似度,r_ui代表使用者u對物品i的興趣。該公式的含義是,和使用者曆史上最感興趣的物品月相似的物品,越有可能在使用者的推薦清單中獲得比較高的排名。
下面是查閱資料找到的一些優化方法:
(1)、使用者活躍度對物品相似度的影響
即認為活躍使用者對物品相似度的貢獻應該小于不活躍的使用者,是以增加一個iuf(inverse user frequence)參數來修正物品相似度的計算公式:
用這種相似度計算的itemcf被記為itemcf-iuf。
itemcf-iuf在準确率和召回率兩個名額上和itemcf相近,但它明顯提高了推薦結果的覆寫率,降低了推薦結果的流行度,從這個意義上說,itemcf-iuf确實改進了itemcf的綜合性能。
(2)、物品相似度的歸一化
karypis在研究中發現如果将itemcf的相似度矩陣按最大值歸一化,可以提高推薦的準确度。其研究表明,如果已經得到了物品相似度矩陣w,那麼可用如下公式得到歸一化之後的相似度矩陣w':
最終結果表明,歸一化的好處不僅僅在于增加推薦的準确度,它還可以提高推薦的覆寫率和多樣性。用這種相似度計算的itemcf被記為itemcf-norm。