現在計算機普遍使用多處理器進行運算,并且為了解決計算機儲存設備和處理器的運算速度之間巨大的差距,引入了高速緩存作為緩沖,
緩存雖然能極大的提高性能,但是随之帶來的緩存一緻性的問題,
例如,當多個處理器同時操作同一個記憶體位址,可能會導緻各自的緩存資料不一緻,由此産生沖突問題,
記憶體模型就是定義一套充分必要的規範,這些規範使得其他處理器對記憶體的寫操作對目前處理器可見,或者目前處理器的寫操作對其他處理器可見。
類似實體上的計算機系統,java虛拟機規範中也定義了一種java記憶體模型,即java memory model(jmm),來屏蔽掉各種硬體和作業系統的記憶體通路差異,以實作讓java程式在各種平台下都能達到一緻的并發效果。
這套規範包含:
線程之間如何通過記憶體通信;
線程之間通過什麼方式通信才合法,才能得到期望的結果。
對于java的并發程式設計,線程間采用的是共享記憶體通信,
在共享記憶體的并發模型裡,線程之間共享程式的公共狀态,線程之間通過寫-讀記憶體中的公共狀态來隐式進行通信。
先看一下java記憶體模型對應的記憶體結構:
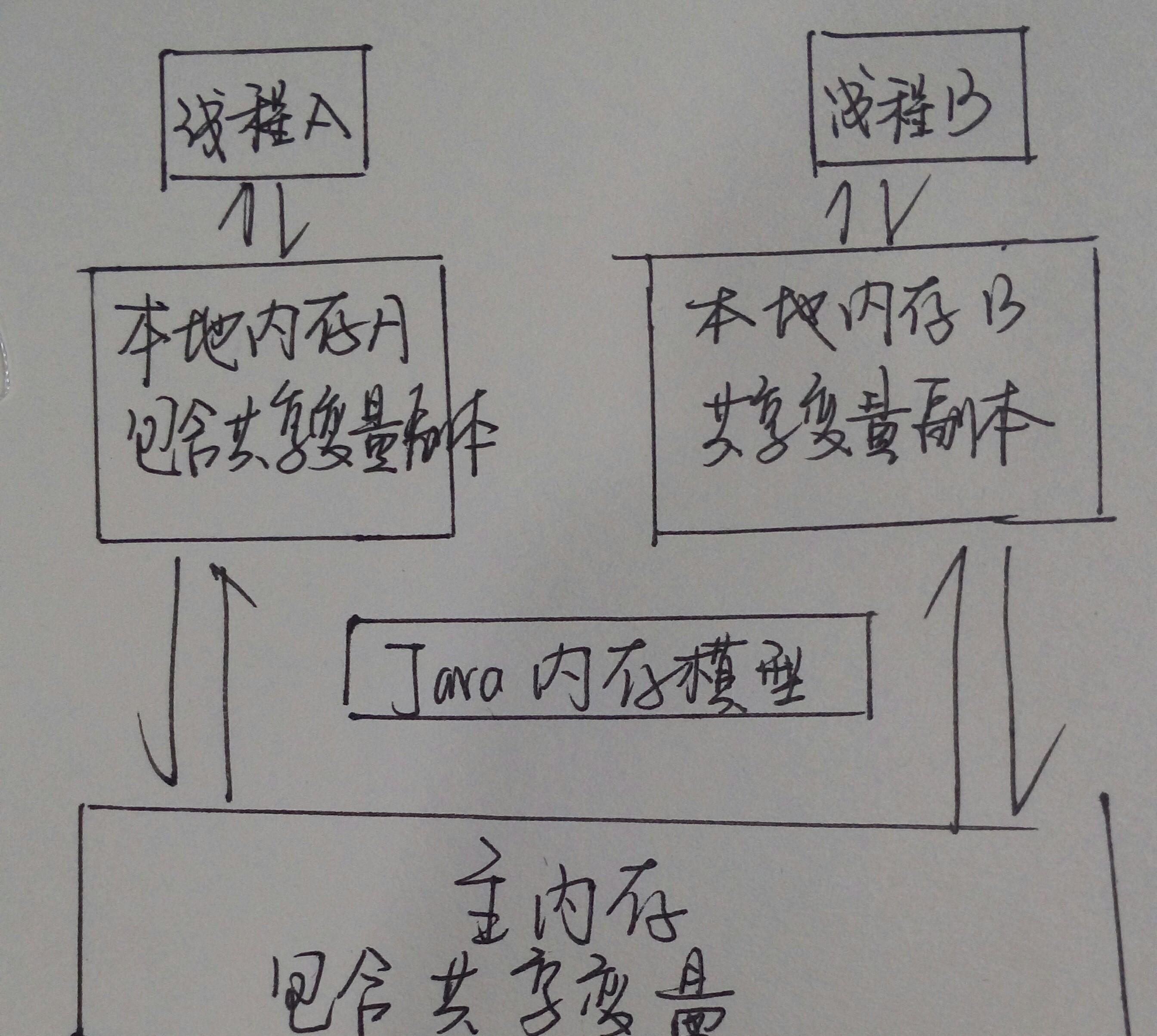
線程之間的共享變量存儲在主記憶體中,每個線程都有一個私有的本地記憶體,本地記憶體中存儲了該線程以讀/寫共享變量的副本。
本地記憶體是一個抽象的概念,包括緩存、寫緩沖區、寄存器等,
一個線程對 volatile 變量的寫一定對之後對這個變量的讀的線程可見,
即線程對 volatile 變量的讀一定能看見在它之前最後一個線程對這個變量的寫。
volatile包含以下語義:
(1)java記憶體模型不會對valatile指令的操作進行重排序:這個保證對volatile變量的操作時按照指令的出現順序執行的。
(2)volatile變量不會被緩存在寄存器中(隻有擁有線程可見)或者其他對cpu不可見的地方,每次總是從主存中讀取volatile變量的結果。
為了實作這些語義,java 規定,(1)當一個線程要使用共享記憶體中的 volatile 變量時,如圖中的變量a,它會直接從主記憶體中讀取,而不使用自己本地記憶體中的副本。(2)當一個線程對一個 volatile 變量進行寫時,它會将這個共享變量的值重新整理到共享記憶體中。
volatile 變量保證的是一個線程對它的寫會立即重新整理到主記憶體中,并置其它線程的副本為無效,它并不保證對 volatile 變量的操作都是具有原子性的。
volatile 變量的寫可以被之後其他線程的讀看到,是以我們可以利用它進行線程間的通信。如
1
2
3
4
5
6
7
<code>volatile</code> <code>int</code> <code>a;</code>
<code>public</code> <code>void</code> <code>set(</code><code>int</code> <code>b) {</code>
<code>a = b;</code>
<code>}</code>
<code>public</code> <code>void</code> <code>get() {</code>
<code>int</code> <code>i = a;</code>
線程a執行set()後,線程b執行get(),相當于線程a向線程b發送了消息。
volatile的語義,其實是告訴處理器,
不要将我放入工作記憶體,請直接在主存操作,多線程在通路該變量時,都将直接操作主存,這從本質上,做到了變量共享。
synchronized 關鍵字,代表這個方法加鎖,相當于不管哪一個線程a每次運作到這個方法時,都要檢查有沒有其它正在用這個方法的線程b(或者c d等),有的話要等正在使用這個方法的線程b(或者c d)運作完這個方法後再運作此線程a,沒有的話,直接運作。
它包括兩種用法:synchronized 方法和 synchronized 塊。
final關鍵字可以作用于變量、方法和類,我們這裡隻看final 變量。
final變量的特殊之處在于,final 變量一經初始化,就不能改變其值。
這裡的值對于一個對象或者數組來說指的是這個對象或者數組的引用位址。是以,一個線程定義了一個final變量之後,其他任意線程都拿到這個變量。
但有一點需要注意的是,當這個final變量為對象或者數組時,
雖然我們不能講這個變量指派為其他對象或者數組,但是我們可以改變對象的域或者數組中的元素。
線程對這個對象變量的域或者資料的元素的改變不具有線程可見性。
java記憶體模型對final有不用的重排序規則,final引用不能從構造函數内“逸出”。
![Java小案例——随機數猜測随機數猜測[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)