今天補充一篇HBase叢集的搭建,這個是高可用系列遺漏的一篇部落格,今天抽時間補上,今天給大家介紹的主要内容目錄如下所示:
基礎軟體的準備
HBase介紹
HBase叢集搭建
單點問題驗證
截圖預覽
那麼,接下來我們開始今天的HBase叢集搭建學習。
在準備好基礎軟體後,我們來介紹一下HBase的相關背景。
在使用HBase的時候,我們需要清楚HBase是用來幹什麼的。HBase是一個分布式的、面向列的開源資料庫,就像Bigtable利用了Google檔案系統(File System)所提供的分布式資料存儲一樣,HBase在Hadoop之上提供了類似于Bigtable的能力。HBase是Apache的Hadoop項目的子項目。HBase不同于一般的關系資料庫,它是一個适合于非結構化資料存儲的資料庫。另一個不同的是HBase基于列的而不是基于行的模式。它是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化存儲叢集。
接下來我們來看看HBase的使用場景,HBase有如下使用場景:
大資料量 (100s TB級資料) 且有快速随機通路的需求。
例如淘寶的交易曆史記錄。資料量巨大無容置疑,面向普通使用者的請求必然要即時響應。
容量的優雅擴充。
大資料的驅使,動态擴充系統容量的必須的。例如:webPage DB。
業務場景簡單,不需要關系資料庫中很多特性(例如交叉列、交叉表,事務,連接配接等等)。
優化方面:合理設計rowkey。因為hbase的查詢用rowkey是最高效的,也幾乎的唯一生産環境可行的方式。是以把你的查詢請求轉換為查詢rowkey的請求吧。
在搭建HBase叢集時,既然HBase擁有高可用特性,那麼我們在搭建的時候要充分利用這個特性,下面給大家一個HBase的叢集搭建架構圖,如下圖所示:
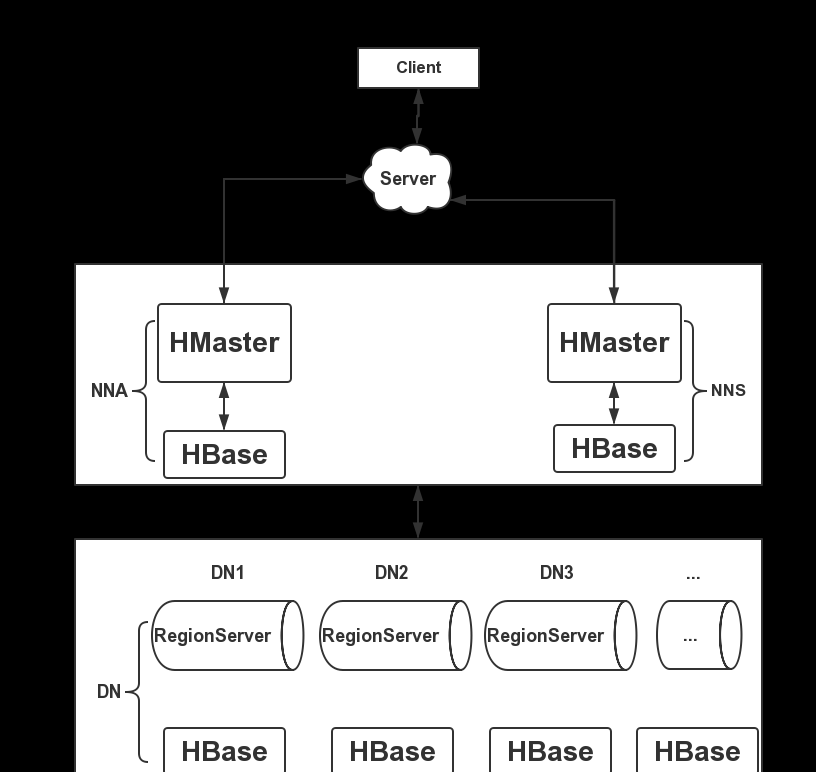
這裡由于資源有限,我将HBase的RegionServer部署在3個DN節點上,HBase的HMaster服務部署在NNA和NNS節點,部署2個HMaster保證叢集的高可用性,防止單點問題。下面我們開始配置HBase的相關配置,這裡我使用的是獨立的ZK,未使用HBase自帶的ZK。
hbase-env.sh
hbase-site.xml
<a></a>
regionservers
在配置完成叢集後,我們開始啟動叢集,需要注意的時,在啟動叢集之前確定各個節點之間的時間是同步的,或者時間差不能太大,若時間差太大,會導緻HBase啟動失敗。下面我們在NNA節點輸入啟動指令,指令内容如下所示:
然後,我們在NNS節點上在啟動一個HMaster程序,啟動指令如下所示:
然後,我們在各個節點輸入jps指令檢視相關啟動程序,各個節點分布的程序如下表所示:
節點
程序
NNA
HMaster
NNS
DN1
RegionServer
DN2
DN3
截圖如下所示:

HBase的Web管理界面,預設端口是16010,這裡我先啟動的是NNA的HMaster,所提NNA節點HMaster對外提供服務,截圖如下所示:
下面我kill掉NNA節點的HMaster程序,指令如下所示:
然後,我們在檢視相應的服務,由于我們使用了ZK,它會選擇一個主服務出來,即NNS節點對外提供HMaster服務,截圖如下所示:
通過驗證,HBase的高可用性正常,避免存在單點問題。
下面給出HBase資料庫的截圖預覽,如下圖所示:
這裡需要注意的是,在搭建HBase叢集的時候需要保證Hadoop平台運作正常,各個節點的時間差不能相差太大,最後時間能夠同步。否則會導緻HBase的啟動失敗。另外,如果在啟動HBase叢集時,提示不能解析HDFS路徑,這裡将Hadoop的core-site.xml和hdfs-site.xml檔案複制到HBase的conf檔案目錄下即可。
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行讨論或發送郵件給我,我會盡我所能為您解答,與君共勉!
<b></b><b></b><b></b><b></b>
聯系方式:
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),友善管理者稽核,謝謝!