本文曾發表于2013年4月的《程式員》雜志
近年來,随着使用者數和PV的增加,淘寶網的後端伺服器數量增長很快;并且我們知道,Web頁面延遲時間和轉化率之間有着直接的關聯。出于提升系統吞吐量、降低成本、減少頁面延遲、提升使用者浏覽體驗、提高交易轉化率的考慮,淘寶網在性能優化領域做了很多嘗試。本文将從應用性能分析、基礎設施優化、應用自身優化、前端性能優化這四個方面,對淘寶網的優化嘗試做一個總結。
- 應用性能分析
- 1.前台應用介紹
淘寶網前台應用是指商品詳情、店鋪、購物車等買家直接可以看到和使用的應用,這類應用PV較高,伺服器數量較多。從技術實作來說,淘寶前台應用都使用Velocity模闆引擎渲染HTML,頁面平均大小大于100KB,WebServer不儲存資料,資料來自于後端的DB、RPC服務、消息中間件、Tair、SearchEngine、TFS等外部系統,除了寫日志、讀取配置和共通模闆,磁盤讀寫很少,而相對于後端系統來說可處理的最大吞吐量較低,單台虛拟機平均TPS不到200。根據分析,這些應用都屬于CPU密集型應用。
- 2.度量關鍵名額
優化工作開始前,要先給系統做次體檢,拿到關鍵名額,然後針對關鍵名額進行優化,這樣在優化工作完成後,更容易度量成果。關鍵名額有吞吐量、頁面大小、響應時間和每請求記憶體數。
A.吞吐量
通過線上環境單機壓測,可以得到伺服器預設最大負載情況下,應用單機的最高真實吞吐量。線上壓測的方法有兩種:對于所有HTTP請求都具備幂等性的系統,可以使用開源的AB、http_load等工具,回放前一天的流量給伺服器,逐漸增加壓力,當系統負載達到預設值時就得到了應用目前最高吞吐量;對于所有HTTP請求不完全具備幂等性的系統,可以采用Nginx引流的方式,将其他伺服器的流量引到同一台伺服器,以達到增加負載、得到最高吞吐量的目的。
B.頁面大小、響應時間
頁面大小和HTTP請求響應時間可以通過分析伺服器通路日志得到。
C.每請求記憶體數
淘寶前台應用都是Java應用,記憶體使用較多,垃圾回收很容易成為瓶頸,是以設定這一名額來衡量應用的記憶體使用情況。每請求記憶體數的計算方法是:JVM機關時間内申請的記憶體/伺服器機關時間内處理的請求數。
- 3.查找應用瓶頸
瓶頸是系統中比較慢的部分,在瓶頸完成前其他部分需要等待,是以優化工作可以從分析瓶頸開始;應用代碼的執行也符合2/8原則,即20%的代碼執行會消耗80%的資源,找到這20%的代碼去做優化才會有效果。自底向上,查找應用瓶頸可以分為下面幾個部分:
A.系統瓶頸
使用top、sar、vmstat、mpstat、iostat等系統工具、JDK源生工具去分析CPU、IO、Memory在壓測時的表現,關注目前程序的Thread、鎖、打開File數、Socket數、GC表現等情況,看哪一塊存在問題或者會先成為瓶頸;對于關鍵代碼,使用Perf等工具檢視熱點和CPU緩存命中率。經過分析,CPU計算的通用瓶頸在字元串的查找、拼接、替換,字元位元組的編碼、解碼轉換,壓縮、解壓縮操作,外部調用的瓶頸在IO開銷、序列化和反序列化操作。
B.代碼瓶頸
對于運作态的Java代碼,業界有很多工具可以用來查找瓶頸,比如收費的JProfiler、YourKit等,免費的TPTP、NetBeansProfiler、VisualVM等,我們使用淘寶開發的适合線上運作的TProfiler工具(已開源),同時支援剖析和采樣兩種方式,可以得到對象建立排行和Java代碼執行次數、執行時間排行。排在前邊的熱點代碼,極有可能就是代碼瓶頸所在,如下表所示:
| 方法資訊 | 執行時間 | 執行次數 | 總時間 |
| com/xxx/web/core/NewList:execute() | 61 | 3102 | 190067 |
| com/xxx/web/core/PerformScreen:performScreen() | 18 | 4822 | 87822 |
| com/xxx/core/DefaultSearchAuction:doMultiSearch() | 43 | 708 | 30357 |
| com/xxx/core/DefaultSearchCatManager:doSearch() | 4 | 1248 | 4552 |
C.子產品瓶頸
基于前邊的熱點代碼排行資料按子產品做歸類統計,可以得出每一個子產品的CPU資源消耗比重,如下圖所示:
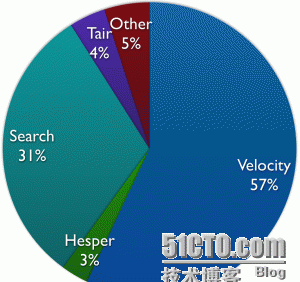
這樣就可以得出:Velocity模闆引擎是此應用的瓶頸子產品,需要着重優化。
- 基礎設施優化
- 1.軟體更新
淘寶之前的Web應用建構在Apache+mod_jk+JBoss4之上,軟體棧相對陳舊,新版本的特性和優化也無法利用。做了一次大的更新後,變成現在的Tengine+Tomcat7,在一些應用上實測吞吐量有近10%的提高,也驗證了Nginx使用epollIO模型帶來的優越性能。作業系統由原來的32位更新為64位,可識别的記憶體變大,增加記憶體後調大新生代堆大小4倍,某應用吞吐量提升達到70%,可見新生代大小對應用吞吐量非常的重要;淘寶有專門的JVM團隊和Linux核心團隊,使用taobao-jdk(更新檔開源)、淘寶核心、開啟JVM大記憶體頁後實測,某應用吞吐量提升40%;TCP初始擁塞視窗調優,對使用者平均下載下傳時間也有不錯的提升。在目前開源軟體百花齊放的形勢下,更新基礎軟體投入不大,卻能給系統性能帶來較大提升,非常劃算。唯一要面對的問題是更新周期會比較長,因為線上環境需要長時間的beta以保證新軟體的穩定。
- 2.JVM調優
根據前面的分析和實踐,吞吐量與GC有直接的關系,在頁面大小不變的情況下,調大新生代有益于提升吞吐量,減小頁面大小(每請求記憶體數)也能提升吞吐量。目前JDK7已經釋出,但G1垃圾回收器還在開發中,經過我們測試在GC表現上G1沒有比CMS更好,是以目前還是選擇響應時間優先的CMS垃圾回收器。我們的JVM部分行為參數和性能參數如下:
-Xms4g-Xmx4g-XX:PermSize=256m-XX:MaxPermSize=256m-Xmn2000m-XX:SurvivorRatio=10-XX:+UseConcMarkSweepGC-XX:+UseCMSCompactAtFullCollection-XX:+CMSParallelRemarkEnabled-XX:+CMSPermGenSweepingEnabled-XX:+CMSClassUnloadingEnabled-XX:+UseCMSInitiatingOccupancyOnly-XX:CMSInitiatingOccupancyFraction=82
除了基本的配置還可以做一些參數調優,比如在6u23之後預設開啟的壓縮指針,随着JDK7釋出帶來的分層編譯、大記憶體頁、逃逸分析等非常值得嘗試的優化。除了參數調優,應用代碼本身也可以調整,使其對GC更友好。在CMS垃圾回收機制下,MinorGC時業務線程會暫停25ms左右,MajorGC時業務線程會暫停500ms左右。使用者的請求被暫停500ms是不能接受的,是以優化原則就是減少MajorGC,也就是減少Young區晉升到Tenured區的對象數。可以通過JVM源生工具jstat觀察JVM各個分區間對象的遷移情況,然後合理配置設定堆每一個分區的大小、調整TenuringThreshold閥值。應用對象管理要盡可能縮短對象生命周期或盡可能少建立新對象,減少頁面模闆大小也是一個可行的辦法。我們開發了TBJMap工具(已開源),可以分析JVM堆每一個分區裡都有哪些内容,這對于優化應用代碼非常具有參考價值。JVM性能表現的最佳狀态是沒有MajorGC,在淘寶有些應用已經做到了這點。
- 3.二方包優化
每一個工程都依賴很多jar包,這些jar包如果用的比較頻繁對性能的影響至關重要,對二方包的優化不會随着業務代碼的改變而性能下降,可以說一次優化永久受益。二方包優化有兩個建議:可以做一次的工作不做多次,在beancopy的場景下使用CGLib代替BeanUtils,性能有超過20倍的提升;可以提前做的工作提前做,IP庫二方包優化過程中把很多備援操作提前處理掉,性能有接近1倍的提升。在技術選型時可以針對場景選擇更優的二方包,比如LMAX-Exchange開源的高性能并發架構Disruptor。另外,如果改變了原來的二方包,代碼不能送出回主幹,将來會遇到版本更新困難的問題。
- 4.模闆引擎優化
通過前面的分析可知,Velocity模闆渲染是最大的子產品瓶頸,除了減小模闆大小,還可以從模闆架構優化下手。因為Velocity是解釋型語言,性能相對較差;執行過程中還有大量的反射調用,效率可想而知;字元位元組的轉換也尤其消耗CPU。淘寶基于Velocity開發了文法相容的Sketch架構,将Velocity模闆編譯成Java類執行,減少了反射調用,内部用位元組存儲頁面,節約了從渲染到輸出的兩次編碼轉換。使用Sketch架構以後,很多應用整體吞吐量有超過20%的提升。另外,淘寶Sketch架構将于今年開源。
應用自身優化
- 1.壓縮模闆大小
在很多系統中,模闆大小和吞吐量成反比,如果能大幅減小模闆和HTML的大小,會給吞吐量帶來很大提升。最簡單的減小模闆方法,就是删除空行和多餘空格。對于URL比較多的頁面,去掉“http:”這五個可省略的字元、長URL壓縮、用URL别名代替全連結都可以帶來不錯的效果。如果for循環裡重複資料較多,可以把資料移到for循環之外,多次出現的隻渲染一次,浏覽器端渲染時再通過前端代碼把重複内容放回去,這種業務上的去重,往往能帶來很好的優化效果。
- 2.設定最佳并發
并發使用者數、資源使用率、吞吐量和響應時間的關系可以參考下圖:

當伺服器處于低負載區,随着并發使用者數的增加,資源使用率和吞吐量直線上升,響應時間沒有明顯的變化;當伺服器處于高負載區,随着并發使用者數的增加,資源使用率趨于飽和,吞吐量達到最高點後開始下降,響應時間開始有明顯的增加;這時并發使用者數繼續增加,伺服器則處于假死狀态,資源使用率繼續趨于飽和,吞吐量開始急劇下降,響應時間開始急劇上升,直到系統不能處理任何請求,我們稱之為伺服器Down機。從這張圖裡我們可以得出,伺服器吞吐量最大的時候對應的并發使用者數,就是這個伺服器的最佳并發數,當并發使用者數大于這個值的時候,系統服務能力開始明顯下降,做優化要找到這個最佳并發數,通過穩定性子產品設定到系統中,穩定性子產品可以對超過最佳并發數的請求進行限流,以保證系統達到最好的性能表現,不會因為大流量沖擊而垮掉。我們一般通過線上壓測來确定系統最佳并發數,對于CPU密集型應用也可以用如下公式計算:
最佳并發=((CPU時間+CPU等待時間)/CPU時間)*CPU核數
- 3.代碼瓶頸優化
前面介紹了如何找到影響性能的瓶頸代碼,可以針對代碼瓶頸進行優化。舉個例子,經過分析發現某系統每個請求都抛異常吞異常,導緻伺服器資源使用率上不去,吞吐量不高,修正後CPU使用率提高30%,系統吞吐量也提升近30%。抛JDK預設的異常比較影響性能,尤其是線上程調用棧很深的情況下,有的系統還使用異常作業務流程控制,有的異常直接被吞掉,危害都很大。taobao-jdk開發了異常監測功能,從JVM層面直接發現和暴露所有異常問題,杜絕了這一類瓶頸的出現。
- 4.外部調用優化
淘寶系統目前處于第三代分布式架構,為了優化外部調用,開發了并行RPC、并行搜尋等功能,對于适合的場景可以有效降低響應時間。某些場景使用更優的ProtocolBuffers序列化架構,在某些對性能要求很高的場景,使用開發成本稍大、比ProtocolBuffers還快20%的Kryo架構。
- 5.面向CPU程式設計
對于CPU密集型應用,如果能減少CPU的使用則可以直接提升系統吞吐量。針對Web應用可以調低GZip壓縮級别來降低HTTPServer對CPU的消耗。針對核心代碼可以面向CPU程式設計:經常一起使用的Field可以放在一起,這樣對CPU緩存比較友好;在多核伺服器上對性能要求比較高的場景,可以補齊緩存行以減少僞共享的發生;按行處理不要按列處理數組,編寫符合空間局部性的代碼可以很好地提升性能;使用源生批量接口處理數組,這樣一條CPU指令就可以完成操作;使用樂觀政策(CAS)來代替同步和鎖也可以有效提升性能。
- 6.架構優化
架構調整往往要對系統傷筋動骨,開發周期很長,但卻可以帶來最好的優化效果。列舉幾個我們常用的架構優化方法:動态資源靜态化,把需要伺服器動态生成、更新不頻繁的内容CDN化,内容變化了可以回源更新CDN,這樣大幅減少了伺服器的動态内容輸出;背景依賴前台化,給後端服務暴露對外的HTTP接口,使伺服器依賴轉變成JS依賴,可以提升後端性能,并且把強依賴變成弱依賴,提升整個系統的穩定性;後端渲染前端化,對于資料遠小于面,頁面布局比較規則的場景适用;DB依賴緩存化,這點業界用的非常之多;善用緩存,針對不同的場景可以緩存對象、緩存頁面片段、緩存整個頁面、緩存HTTP響應,使用緩存需要關注失效機制和資料預熱,并盡可能提高緩存命中率。
- 前端性能優化
- 1.度量關鍵名額
我們可以通過前端埋點和NavigationTiming接口來采集網頁在使用者浏覽器上的關鍵名額,包括DNS查詢時間、TCP連接配接建立時間、HTTP請求時間、頁面下載下傳時間、開始渲染時間、domReady、可互動時間、onLoad時間,使用阿裡度等工具可以得到首屏時間。有了這些名額就可以衡量前端優化的效果。業界還有一些工具會給出很多優化建議,比如dynaTraceAJAXEdition、YSlow、Chrome插件SpeedTracer等,淘寶也根據Yahoo的34條軍規,開發了自己的TSlow。
性能優化性能調優高性能