李鵬同學在blog裡寫了篇關于hashmap死鎖模拟的文章: http://blog.csdn.net/madding/archive/2010/08/25/5838477.aspx 做個糾正,那個不是死鎖問題,而是死循環。
在之前的郵件清單裡,校長提出過這個問題,當時我沒仔細看,不清楚這個問題究竟是對 hashmap的誤用,還是hashmap的潛在問題, 當時感覺不太可能是hashmap自身的問題,否則問題大了。應該是屬于在并發的場景下錯誤的 使用了hashmap。昨天看了李鵬的blog後,覺得這個事情還是應該搞清楚一下;雖然我推測是連結清單形成閉環,但 沒有去證明過。從網上找了一下: http://blog.csdn.net/autoinspired/archive/2008/07/16/2662290.aspx 裡面也有提到:
産生這個死循環的根源在于對一個未保護的共享變量 — 一個”hashmap”資料結構的操作。當在 所有操作的方法上加了”synchronized”後,一切恢複了正常。檢查”hashmap”(java se 5.0)的源 碼,我們發現有潛在的破壞其内部結構最終造成死循環的可能。在下面的代碼中,如果我們使得 hashmap中的entries進入循環,那 麼”e.next()”永遠都不會為null。
不僅get()方法會這樣,put()以及其他對外暴露的方法都會有這個風險,這算jvm的bug嗎?應該說不是的,這個現象很早以前就報告出來了(詳細見: http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=6423457)。sun的工程師并不認為這 是bug,而是建議在這樣的場景下應用”concurrenthashmap”,在建構可擴充的系統時應将這點 納入規範中。
這篇翻譯提到了對<code>hashmap</code>的誤用,但它沒有點破<code>hashmap</code>内部結構在什麼樣誤用情況下怎麼被 破壞的;我想要一個有力的場景來弄清楚。再從李鵬的blog來看,用了2個線程來put就模拟出來了,最後堆棧是在 <code>transfer</code> 方法上(該方法是資料擴容時将資料從舊容器轉移到新容器)。 仔細分析了一下裡面的代碼,基本得出了原因,證明了我之前的推測。
假設擴容時的一個場景如下(右邊的容器是一個長度 2 倍于目前容器的數組) 單線程情況。
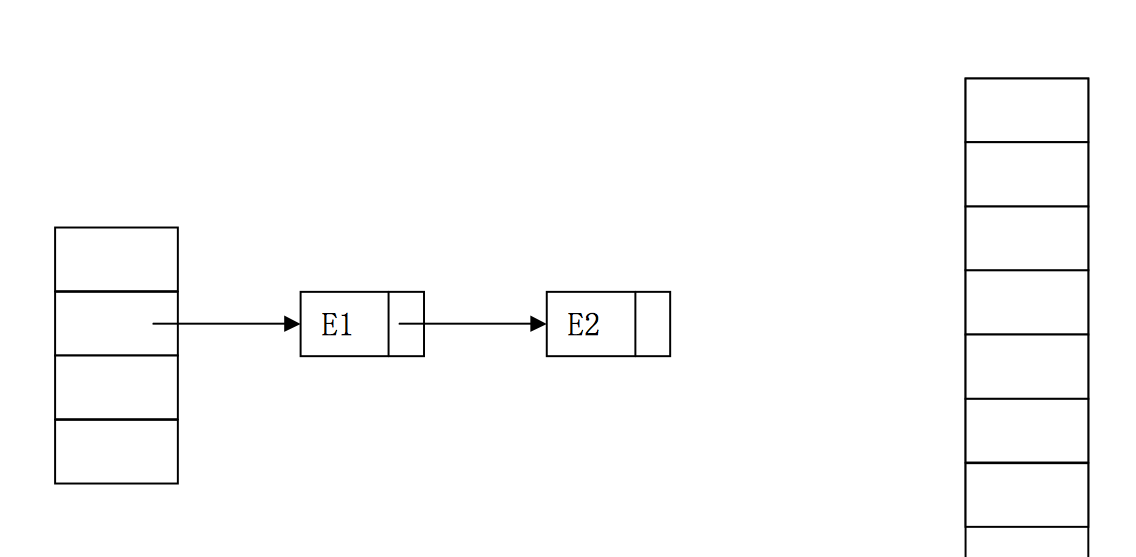
我們分析資料轉移的過程,主要是連結清單的轉移。

執行過一次後的狀态:
最終的結果:
兩個線程并發情況下,擴容時可能會建立出 2 個新數組容器
順利的話,最終轉移完可能是這樣的結果
但并發情況下,出現死循環的可能場景是什麼呢? 還要詳細的分析一下代碼,下面的代碼中重點在 <code>do/while</code> 循環結構中(完成鍊 表的轉移)。
2 個線程并發情況下, 當線程 1 執行到上面第 9 行時,而線程 2 已經完成了一 輪 do/while 操作,那麼它的狀态如下圖:
(上面的數組時線程 1 的,已經完成了連結清單資料的轉移;下面的是線程 2 的,它 即将開始進行對連結清單資料的轉移,此時它記錄 e1 和 e2 的首位已經被線程 1 翻 轉了)
後續的步驟如下:
1) 插入 e1 節點,e1 節點的 next 指向新容器索引位置上的值(null 或 entry)
2) 插入 e2 節點,e2 的 next 指向目前索引位置上的引用值 e1
3)因為 next 不為 null,連結清單繼續移動,此時 2 節點之間形成了閉環。造成了 死循環。
上面隻是一種情況,造成單線程死循環,雙核 cpu 的話占用率是 50%,還有導緻 100%的情況,應該也都是連結清單的閉環所緻。