在課程中進行案例研究(使用真實資料)時,學生都會驚訝地發現很難獲得“好”模型,而當試圖對索賠的機率進行模組化時,他們總是會驚訝地發現AUC較低。因為保險中存在很多'随機性'。
更具體地說,我決定進行一些模拟,并計算AUC以檢視發生了什麼。而且由于我不想浪費時間進行拟合模型,是以我們假設每次都有一個完美的模型。是以,我想表明AUC的上限實際上很低!是以,這不是模組化問題,而是保險業的基礎問題。
我們使用協變量(例如在汽車保險中的汽車駕駛員的年齡或在人壽保險中的保單持有人的年齡等)。然後我們使用它們來訓練模型。然後,我們使用從混淆矩陣獲得的ROC曲線來檢查我們的模型是否良好。在這裡,我不會嘗試構模組化型。我會預測每次真實基礎機率超過門檻值!
在這裡 p(\ omega_1)表示索賠損失,欺詐等的可能性。這裡存在異質性,這種異質性可以很小,也可以很大。請看下面的圖表來說明,
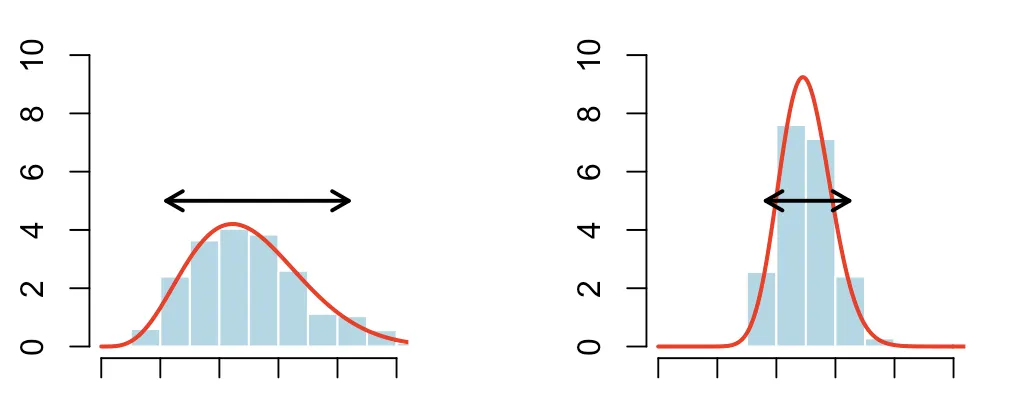
在這兩種情況下,平均有25%的機會要求賠償損失。但是在左邊,存在更多的異構性,更多的分散性。為了說明這一點,我使用了箭頭。
考慮一些帶有伯努利變量的資料集 y,用這些機率得出p( omega),p (ω )。然後,我們假設我們能夠得到一個完美的模型:我不會基于某些協變量來估計模型,在這裡,我假設我完全知道機率。更具體地說,為了生成機率向量,在這裡我使用具有給定均值和給定方差的Beta分布(以捕獲上面提到的異質性).
a=m*(m*(1-m)/v-1)
b=(1-m)*(m*(1-m)/v-1)
p=rbeta(n,a,b) 從這些機率中,我模拟了索賠或死亡的發生,
Y=rbinom(n,size = 1,prob = p) 然後,我計算出“完美”模型的AUC,
auc.tmp=performance(prediction(p,Y),"auc") 然後,我将生成許多樣本,以計算AUC的平均值。我們可以對Beta分布的均值和方差的許多值執行此操作。這是代碼
Vm=seq(.025,.975,by=.025)
Vi=seq(.01,.5,by=.01)
V=outer(X = Vm,Y = Vi, Vectorize(function(x,y)
Sim_AUC_mean_inter(x,y)$moy_AUC))
library("RColorBrewer")
image(Vm,Vi,V,
xlab="Probability (Average)",
ylab="Dispersion (Q95-Q5)",
col=
colorRampPalette(brewer.pal(n = 9, name = "YlGn"))(101))
contour(Vm,Vi,V,add=TRUE,lwd=2) 