日志收集
日志就是用于記錄系統運作時的資訊,對一個事件的記錄。
日志的作用
- 調試程式
- 可以用來判斷程式是否運作正常
- 可以用來分析和定位問題
- 可以用來做使用者行為分析和資料統計
日志的級别
- 調試級别DEBUG 記錄的一些代碼的調試資訊。
- 資訊級别INFO 記錄一些正常的操作資訊。
- 警告級别Warring 記錄的是一些警告日志資訊,但不會影響系統的功能及正常運作。
- 錯誤級别Error 記錄的是系統運作時的錯誤資訊,說明系統的某些功能不能正常運作 。
- 嚴重錯誤級别critical 記錄的系統運作時的嚴重錯誤資訊,有可能導緻整個系統都不能運作。
背景和動機
當我們的容器雲運作的應用或者某個節點出現問題了,解決思路應該如下:
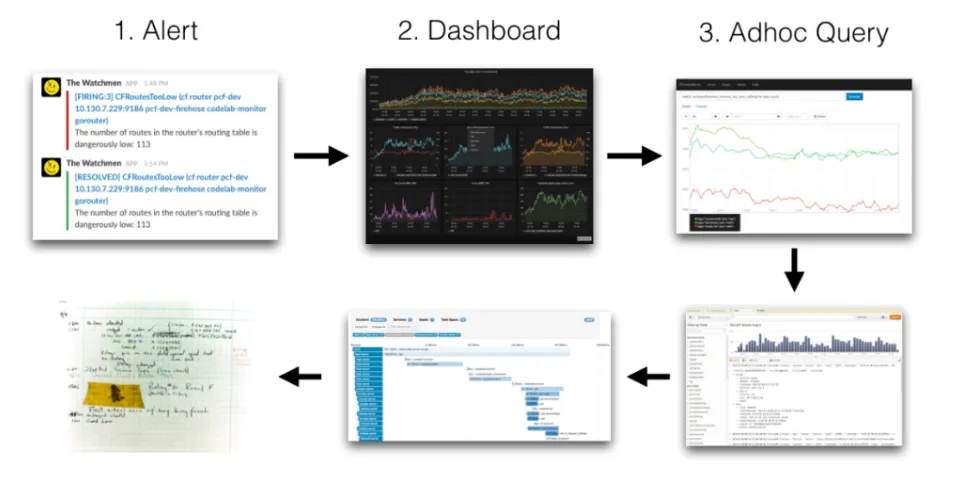
我們的監控使用的是基于Prometheus體系進行改造的,Prometheus中比較重要的是Metric和Alert,Metric是來說明目前或者曆史達到了某個值,Alert設定Metric達到某個特定的基數觸發了告警,但是這些資訊明顯是不夠的。我們都知道,Kubernetes的基本機關是Pod,Pod把日志輸出到stdout和stderr,平時有什麼問題我們通常在界面或者通過指令檢視相關的日志,舉個例子:當我們的某個Pod的記憶體變得很大,觸發了我們的Alert,這個時候管理者,去頁面查詢确認是哪個Pod有問題,然後要确認Pod記憶體變大的原因,我們還需要去查詢Pod的日志,如果沒有日志系統,那麼我們就需要到頁面或者使用指令進行查詢了:

如果,這個時候應用突然挂了,這個時候我們就無法查到相關的日志了,是以需要引入日志系統,統一收集日志,而使用ELK的話,就需要在Kibana和Grafana之間切換,影響使用者體驗。是以 ,loki的第一目的就是最小化度量和日志的切換成本,有助于減少異常事件的響應時間和提高使用者的體驗。
Loki日志系統
Loki日志系統是受Prometheus啟發由Grafana Labs團隊開源的水準可擴充,高度可用的[多租戶日志聚合系統。它被設計得非常輕量高效且易于操作,使用标簽來作為索引,而不是對全文進行檢索,即通過這些标簽既可以查詢日志的内容也可以查詢到監控的資料簽,極大地降低了日志索引的存儲。
Loki 日志系統由以下3個部分組成:
- loki是主伺服器,負責存儲日志和處理查詢
- promtail是專為loki定制的代理,負責收集日志并将其發送給 loki
-
Grafana用于查詢和顯示日志
整體架構
Loki 包含Distributor、Ingester、Querier和可選的Query frontend五個元件。每個元件都會起一個用于處理内部請求的 gRPC 伺服器和一個用于處理外部 API 請求的 HTTP/1伺服器。 【日志】Loki
grpc相關
三豐,公衆号:soft張三豐【通訊】以json的方式通路grpc
Distributor
Distributor 是用戶端連接配接的元件,用于收集日志
在 promtail 收集并将日志發送給Loki 之後, Distributor 就是第一個接收它們的元件,每秒可以接收數百萬次寫入。Distributor會對接收到的日志流進行正确性校驗,并将驗證後的chunk日志塊分批并行發送到Ingester。
事件驅動
三豐,公衆号:soft張三豐事件驅動
Ingester
Ingester 接收來自Distributor的日志流,并将日志壓縮後存放到所連接配接的存儲後端。
Ingester接受日志流并建構資料塊,其操作通常是壓縮和追加日志。每個Ingester 的生命周期有PENDING, JOINING, ACTIVE, LEAVING 和 UNHEALTHY 五種狀态。處于JOINING和ACTIVE狀态的Ingester可以接受寫請求,處于ACTIVE和LEAVING狀态時可以接受讀請求。
Ingester 将收到的日志流在記憶體中打包成 chunks ,并定期同步到存儲後端。由于存儲的資料類型不同,Loki 的資料塊和索引可以使用不同的存儲
當滿足以下條件時,chunks 會被标記為隻讀:
- 目前 chunk 達到配置的最大容量
- 目前 chunk 長時間沒有更新
- 發生了定期同步
- 當舊的 chunk 經過了壓縮并被打上了隻讀标志後,新的可寫的 chunk 就會生成
Querier
Querier 用來查詢日志,可以直接從 Ingester 和後端存儲中查詢資料。當用戶端給定時間區間和标簽選擇器之後,Querier 就會查找索引來确定所有比對 chunk ,然後對選中的日志進行 grep并傳回查詢結果。查詢時,Querier先通路所有Ingester用于擷取其記憶體資料,隻有當記憶體中沒有符合條件的資料時,才會向存儲後端發起同樣的查詢請求。
需要注意的是,對于每個查詢,單個 Querier 會 grep 所有相關的日志。目前 Cortex 中已經實作了并行查詢,該功能可以擴充到 Loki,通過分布式的 grep 加速查詢。此外,由于副本因子的存在,Querier可能會接收到重複的資料,是以其内置了去重的功能,對擁有同樣時間戳、标簽組和消息内容的日志進行去重處理。
Loki與其他日志聚合系統差别:
- 不對日志進行全文本索引。通過存儲壓縮的,非結構化的日志以及僅索引中繼資料,Loki更加易于操作且運作成本更低
- 使用與Prometheus相同的标簽對日志流進行索引和分組,進而使您能夠使用與Prometheus相同的标簽在名額和日志之間無縫切換。
- 特别适合存儲Kubernetes Pod日志。諸如Pod标簽之類的中繼資料會自動被抓取并建立索引
- 在Grafana中原生支援(需要Grafana v6.0及以上)
成本
全文檢索的方案也帶來成本問題,簡單的說就是全文搜尋(如ES)的反向索引的切分和共享的成本較高。後來出現了其他不同的設計方案如:OKlog,采用最終一緻的、基于網格的分布政策。這兩個設計決策提供了大量的成本降低和非常簡單的操作,但是查詢不夠友善。是以,Loki的第三個目的是,提高一個更具成本效益的解決方案。
Loki與ELK抉擇
在Loki之前,你要問運維開源的日志解決方案,似乎隻有ELK
不可否認,ELK通過對日志全文索引及列式存儲,為日志存儲及分析帶來極大的便利性
但是從另一個角度來講,這樣的便利是通過極高的成本換來的,包括伺服器成本和運維成本,而存儲的日志中,高價值的日志卻很少,這樣的成效比是極低的
而Loki則恰恰相反,Loki不會對日志資料建立全文索引,取而代之的是對非結構化日志資料進行壓縮存儲,并且隻對日志資料的metadata(時間戳、labels等)建立索引,是以相比ELK,它的存儲成本更低,查詢效率也更高
但是Loki也有缺點,就是如果想實作項ELK一樣的複雜度比較高的查詢,需要設計好Labels,如果對labels設計不合理,會使Loki對資料流的存儲和查詢帶來極大的挑戰,會使Loki崩潰。
關注公衆号 soft張三豐