關于消息隊列的使用
一、消息隊列概述
消息隊列中間件是分布式系統中重要的元件,主要解決應用解耦,異步消息,流量削鋒等問題,實作高性能,高可用,可伸縮和最終一緻性架構。目前使用較多的消息隊列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ
二、消息隊列應用場景
以下介紹消息隊列在實際應用中常用的使用場景。異步處理,應用解耦,流量削鋒和消息通訊四個場景。
2.1異步處理
場景說明:使用者注冊後,需要發注冊郵件和注冊短信。傳統的做法有兩種 1.串行的方式;2.并行方式
a、串行方式:将注冊資訊寫入資料庫成功後,發送注冊郵件,再發送注冊短信。以上三個任務全部完成後,傳回給用戶端。
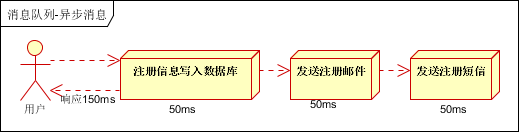
b、并行方式:将注冊資訊寫入資料庫成功後,發送注冊郵件的同時,發送注冊短信。以上三個任務完成後,傳回給用戶端。與串行的差别是,并行的方式可以提高處理的時間

假設三個業務節點每個使用50毫秒鐘,不考慮網絡等其他開銷,則串行方式的時間是150毫秒,并行的時間可能是100毫秒。
因為CPU在機關時間内處理的請求數是一定的,假設CPU1秒内吞吐量是100次。則串行方式1秒内CPU可處理的請求量是7次(1000/150)。并行方式處理的請求量是10次(1000/100)
小結:如以上案例描述,傳統的方式系統的性能(并發量,吞吐量,響應時間)會有瓶頸。如何解決這個問題呢?
引入消息隊列,将不是必須的業務邏輯,異步處理。改造後的架構如下:
按照以上約定,使用者的響應時間相當于是注冊資訊寫入資料庫的時間,也就是50毫秒。注冊郵件,發送短信寫入消息隊列後,直接傳回,是以寫入消息隊列的速度很快,基本可以忽略,是以使用者的響應時間可能是50毫秒。是以架構改變後,系統的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了兩倍。
2.2應用解耦
場景說明:使用者下單後,訂單系統需要通知庫存系統。傳統的做法是,訂單系統調用庫存系統的接口。如下圖:
傳統模式的缺點:假如庫存系統無法通路,則訂單減庫存将失敗,進而導緻訂單失敗,訂單系統與庫存系統耦合
如何解決以上問題呢?引入應用消息隊列後的方案,如下圖:
訂單系統:使用者下單後,訂單系統完成持久化處理,将消息寫入消息隊列,傳回使用者訂單下單成功
庫存系統:訂閱下單的消息,采用拉/推的方式,擷取下單資訊,庫存系統根據下單資訊,進行庫存操作
假如:在下單時庫存系統不能正常使用。也不影響正常下單,因為下單後,訂單系統寫入消息隊列就不再關心其他的後續操作了。實作訂單系統與庫存系統的應用解耦
2.3流量削鋒
流量削鋒也是消息隊列中的常用場景,一般在秒殺或團搶活動中使用廣泛。
應用場景:秒殺活動,一般會因為流量過大,導緻流量暴增,應用挂掉。為解決這個問題,一般需要在應用前端加入消息隊列。
a、可以控制活動的人數
b、可以緩解短時間内高流量壓垮應用
使用者的請求,伺服器接收後,首先寫入消息隊列。假如消息隊列長度超過最大數量,則直接抛棄使用者請求或跳轉到錯誤頁面。
秒殺業務根據消息隊列中的請求資訊,再做後續處理
2.4日志處理
日志處理是指将消息隊列用在日志進行中,比如Kafka的應用,解決大量日志傳輸的問題。架構簡化如下
日志采集用戶端,負責日志資料采集,定時寫受寫入Kafka隊列
Kafka消息隊列,負責日志資料的接收,存儲和轉發
日志處理應用:訂閱并消費kafka隊列中的日志資料
2.5消息通訊
消息通訊是指,消息隊列一般都内置了高效的通信機制,是以也可以用在純的消息通訊。比如實作點對點消息隊列,或者聊天室等
點對點通訊:
用戶端A和用戶端B使用同一隊列,進行消息通訊。
聊天室通訊:
用戶端A,用戶端B,用戶端N訂閱同一主題,進行消息釋出和接收。實作類似聊天室效果。
以上實際是消息隊列的兩種消息模式,點對點或釋出訂閱模式。模型為示意圖,供參考。
三、消息中間件示例
3.1電商系統
消息隊列采用高可用,可持久化的消息中間件。比如Active MQ,Rabbit MQ,Rocket Mq。
(1)應用将主幹邏輯處理完成後,寫入消息隊列。消息發送是否成功可以開啟消息的确認模式。(消息隊列傳回消息接收成功狀态後,應用再傳回,這樣保障消息的完整性)
(2)擴充流程(發短信,配送處理)訂閱隊列消息。采用推或拉的方式擷取消息并處理。
(3)消息将應用解耦的同時,帶來了資料一緻性問題,可以采用最終一緻性方式解決。比如主資料寫入資料庫,擴充應用根據消息隊列,并結合資料庫方式實作基于消息隊列的後續處理。
3.2日志收集系統
分為Zookeeper注冊中心,日志收集用戶端,Kafka叢集和Storm叢集(OtherApp)四部分組成。
Zookeeper注冊中心,提出負載均衡和位址查找服務
日志收集用戶端,用于采集應用系統的日志,并将資料推送到kafka隊列
Kafka叢集:接收,路由,存儲,轉發等消息處理
Storm叢集:與OtherApp處于同一級别,采用拉的方式消費隊列中的資料
四、JMS消息服務
講消息隊列就不得不提JMS 。JMS(JAVA Message Service,java消息服務)API是一個消息服務的标準/規範,允許應用程式元件基于JavaEE平台建立、發送、接收和讀取消息。它使分布式通信耦合度更低,消息服務更加可靠以及異步性。
在EJB架構中,有消息bean可以無縫的與JM消息服務內建。在J2EE架構模式中,有消息服務者模式,用于實作消息與應用直接的解耦。
4.1消息模型
在JMS标準中,有兩種消息模型P2P(Point to Point),Publish/Subscribe(Pub/Sub)。
4.1.1 P2P模式
P2P模式包含三個角色:消息隊列(Queue),發送者(Sender),接收者(Receiver)。每個消息都被發送到一個特定的隊列,接收者從隊列中擷取消息。隊列保留着消息,直到他們被消費或逾時。
P2P的特點
每個消息隻有一個消費者(Consumer)(即一旦被消費,消息就不再在消息隊列中)
發送者和接收者之間在時間上沒有依賴性,也就是說當發送者發送了消息之後,不管接收者有沒有正在運作,它不會影響到消息被發送到隊列
接收者在成功接收消息之後需向隊列應答成功
如果希望發送的每個消息都會被成功處理的話,那麼需要P2P模式。
4.1.2 Pub/Sub模式
包含三個角色主題(Topic),釋出者(Publisher),訂閱者(Subscriber) 多個釋出者将消息發送到Topic,系統将這些消息傳遞給多個訂閱者。
Pub/Sub的特點
每個消息可以有多個消費者
釋出者和訂閱者之間有時間上的依賴性。針對某個主題(Topic)的訂閱者,它必須建立一個訂閱者之後,才能消費釋出者的消息
為了消費消息,訂閱者必須保持運作的狀态
為了緩和這樣嚴格的時間相關性,JMS允許訂閱者建立一個可持久化的訂閱。這樣,即使訂閱者沒有被激活(運作),它也能接收到釋出者的消息。
如果希望發送的消息可以不被做任何處理、或者隻被一個消息者處理、或者可以被多個消費者處理的話,那麼可以采用Pub/Sub模型。
4.2消息消費
在JMS中,消息的産生和消費都是異步的。對于消費來說,JMS的消息者可以通過兩種方式來消費消息。
(1)同步
訂閱者或接收者通過receive方法來接收消息,receive方法在接收到消息之前(或逾時之前)将一直阻塞;
(2)異步
訂閱者或接收者可以注冊為一個消息監聽器。當消息到達之後,系統自動調用監聽器的onMessage方法。
JNDI:Java命名和目錄接口,是一種标準的Java命名系統接口。可以在網絡上查找和通路服務。通過指定一個資源名稱,該名稱對應于資料庫或命名服務中的一個記錄,同時傳回資源連接配接建立所必須的資訊。
JNDI在JMS中起到查找和通路發送目标或消息來源的作用。
五、常用消息隊列
一般商用的容器,比如WebLogic,JBoss,都支援JMS标準,開發上很友善。但免費的比如Tomcat,Jetty等則需要使用第三方的消息中間件。本部分内容介紹常用的消息中間件(Active MQ,Rabbit MQ,Zero MQ,Kafka)以及他們的特點。
5.1 ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力強勁的開源消息總線。ActiveMQ 是一個完全支援JMS1.1和J2EE 1.4規範的 JMS Provider實作,盡管JMS規範出台已經是很久的事情了,但是JMS在當今的J2EE應用中間仍然扮演着特殊的地位。
ActiveMQ特性如下:
⒈ 多種語言和協定編寫用戶端。語言: Java,C,C++,C#,Ruby,Perl,Python,PHP。應用協定: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
⒉ 完全支援JMS1.1和J2EE 1.4規範 (持久化,XA消息,事務)
⒊ 對Spring的支援,ActiveMQ可以很容易内嵌到使用Spring的系統裡面去,而且也支援Spring2.0的特性
⒋ 通過了常見J2EE伺服器(如 Geronimo,JBoss 4,GlassFish,WebLogic)的測試,其中通過JCA 1.5 resource adaptors的配置,可以讓ActiveMQ可以自動的部署到任何相容J2EE 1.4 商業伺服器上
⒌ 支援多種傳送協定:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
⒍ 支援通過JDBC和journal提供高速的消息持久化
⒎ 從設計上保證了高性能的叢集,用戶端-伺服器,點對點
⒏ 支援Ajax
⒐ 支援與Axis的整合
⒑ 可以很容易得調用内嵌JMS provider,進行測試
5.2 Kafka
Kafka是一種高吞吐量的分布式釋出訂閱消息系統,它可以處理消費者規模的網站中的所有動作流資料。 這種動作(網頁浏覽,搜尋和其他使用者的行動)是在現代網絡上的許多社會功能的一個關鍵因素。 這些資料通常是由于吞吐量的要求而通過處理日志和日志聚合來解決。 對于像Hadoop的一樣的日志資料和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka的目的是通過Hadoop的并行加載機制來統一線上和離線的消息處理,也是為了通過叢集機來提供實時的消費。
Kafka是一種高吞吐量的分布式釋出訂閱消息系統,有如下特性:
通過O(1)的磁盤資料結構提供消息的持久化,這種結構對于即使數以TB的消息存儲也能夠保持長時間的穩定性能。(檔案追加的方式寫入資料,過期的資料定期删除)
高吞吐量:即使是非常普通的硬體Kafka也可以支援每秒數百萬的消息
支援通過Kafka伺服器和消費機叢集來分區消息
支援Hadoop并行資料加載
Kafka相關概念
Broker
Kafka叢集包含一個或多個伺服器,這種伺服器被稱為broker[5]
Topic
每條釋出到Kafka叢集的消息都有一個類别,這個類别被稱為Topic。(實體上不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然儲存于一個或多個broker上但使用者隻需指定消息的Topic即可生産或消費資料而不必關心資料存于何處)
Partition
Parition是實體上的概念,每個Topic包含一個或多個Partition.
Producer
負責釋出消息到Kafka broker
Consumer
消息消費者,向Kafka broker讀取消息的用戶端。
Consumer Group
每個Consumer屬于一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬于預設的group)。
一般應用在大資料日志處理或對實時性(少量延遲),可靠性(少量丢資料)要求稍低的場景使用。