網易視訊雲是網易傾力打造的一款基于雲計算的分布式多媒體處理叢集和專業音視訊技術,為客戶提供穩定流暢、低延遲時間、高并發的視訊直播、錄制、存儲、轉碼及點播等音視訊的PaaS服務。線上教育、遠端醫療、娛樂秀場、線上金融等各行業及企業使用者隻需經過簡單的開發即可打造在線上音視訊平台。現在,網易視訊雲與大家分享一下HBase GC的前生今世身世篇。
在之前的HBase BlockCache系列文章中已經簡單提到:使用LRUBlockCache緩存機制會因為CMS GC政策導緻記憶體碎片過多,進而可能引發臭名昭著的Full GC,觸發可怕的’stop-the-world’暫停,嚴重影響上層業務;而Bucket Cache緩存機制因為在初始化的時候就申請了一片固定大小的記憶體作為緩存,緩存淘汰不再由 JVM管理,資料Block的緩存操作隻是對這篇空間的通路和覆寫,因而大大減少了記憶體碎片的出現,降低了Full GC發生的頻率。那CMS GC政策如何導緻記憶體碎片過多?記憶體碎片過多如何觸發Full GC?HBase在演進的道路上又如何不斷優化CMS GC?接下來這個系列《HBase GC的前生今生》将會為你一一揭開謎底,這個系列一共兩篇文章,本篇文章-’身世篇’将會帶你全面了解HBase的GC機制,後面一篇-’演進篇’将會給你道出HBase在發展的道路上如何不斷對Full GC進行優化。
Java GC概述
整個HBase是建構在JVM虛拟機上的,是以了解HBase的記憶體管理機制以及不同緩存機制對GC的影響,就必須對Java GC有一個全面的了解。至于深入地了解Java GC 的工作原理,不在本文的讨論範圍之内;當然,如果已經對Java GC比較熟悉,也可以跳過此節。
Java GC建立在這樣一個假設基礎上的:大多數記憶體對象要麼生存周期比較短,很快就會沒人引用,比如處理RPC請求的buffer可能隻會生存幾微秒;要麼生存周期比較長,比如Block Cache中的熱點Block,可能就會生存幾分鐘,甚至更長時間。基于這樣的事實,JVM将整個堆記憶體分為兩個部分:新生代(young generation)和老生代(tenured generation),除此之外,JVM還有一個非堆記憶體區-Perm區,主要存放class資訊以及其他meta元資訊,記憶體結構如下圖所示:
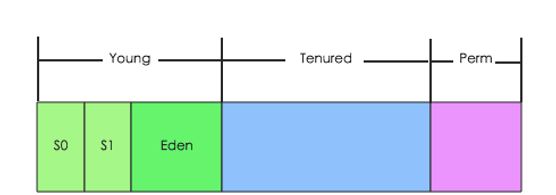
其中Young區又分為Eden區和兩個Survivor 區:S0和S1。一個記憶體對象在建立之後,首先會為其在新生代申請一塊記憶體空間,如果這個對象在新生代存活了很長時間,會将其遷移到老生代。 在大多數對延遲敏感的業務場景下(比如HBase),建議使用如下JVM參數,-XX:+UseParNewGC和XX:+UseConcMarkSweepGC,其中前者表示對新生代執行并行的垃圾回收機制,而後者表示對老生代執行并行标記-清除垃圾回收機制。可見,JVM允許針對不同記憶體區執行不同的GC政策。
新生代GC政策 – Parallel New Collector
根據上文所述,對象初始化之後會被放入Young區,更具體的話應該是Eden區,當Eden區滿了之後,會進行一次GC。GC算法會檢查所有對象的引用情況,如果某個對象還有被引用,表示該對象存活。檢查完成之後,會将這些存活的對象移到S0區,并且回收整個Eden區空間,稱為一次Minor GC;接着新對象進來,又會放入Eden區,滿了之後會檢查S0和Eden區存活的對象,将所有存活的對象移到S1區,再回收整個S0和Eden區空間;很容易了解,S0和S1兩個區總會有一個區是預留給下次存放存活對象用的。
整個過程可以使用如下圖示:

這種算法稱為複制算法,對于這種算法,有兩點需要關注:
1. 算法會執行’stop-the-world’暫停,但時間非常短。因為Young區通常會設定的比較小(一般不建議不超過512M),而且JVM會啟動大量線程并發執行,一次Minor GC一般都會在幾毫秒内完成
2. 不會産生碎片,每次GC之後都會将存活的對象放入連續的空間(S0或S1)
記憶體中所有對象都會維護一個計數器,每次Minor GC移動一個對象之後,都會為這個對象的計數器加一。當計數器增加到一定門檻值之後,算法就會認為該對象生命周期很長,會将其移入老生代。該門檻值可以通過JVM參數XX:MaxTenuringThreshold指定。
老生代GC政策 – Concurrent Mark-Sweep
每次執行Minor GC之後,都會有部分生命周期較長的對象被移入老生代,一段時間之後,老生代空間也會被占滿。此時就需要針對老生代空間執行GC操作,此處我們介紹Concurrent Mark-Sweep(CMS)算法。CMS算法整個流程分為6個階段,其中部分階段會執行 ‘stop-the-world’ 暫停,部分階段會和應用線程一起并發執行:
1. initial-mark:這個階段虛拟機會暫停所有正在執行的任務。這一過程虛拟機會标記所有 ‘根對象’,所謂‘根對象’,一般是指一個運作線程直接引用到的對象。雖然會暫停整個JVM,但因為’根對象’相對較少,這個過程通常很快。
2. concurrent mark:垃圾回收器會從‘根節點’開始,将所有引用到的對象都打上标記。這個階段應用程式的線程和标記線程并發執行,是以使用者并不會感到停頓。
3. concurrent precleaning:并發預清理階段仍然是并發的。在這個階段,虛拟機查找在執行mark階段新進入老年代的對象(可能會有一些對象從新生代晉升到老年代, 或者有一些對象被配置設定到老年代)。
4. remark:在階段3的基礎上對查找到的對象進行重新标記,這一階段會暫停整個JVM,但是因為階段3已經欲檢查出了所有新進入的對象,是以這個過程也會很快。
5. concurrent sweep:上述3階段完成了引用對象的标記,此階段會将所有沒有标記的對象作為垃圾回收掉。這個階段應用程式的線程和标記線程并發執行。
6. concurrent reset:重置CMS收集器的資料結構,等待下一次垃圾回收。
相應的,對于CMS算法,也需要關注兩點:
1. ‘stop-the-world’暫停時間也很短暫,耗時較長的标記和清理都是并發執行的。
2. CMS算法在标記清理之後并沒有重新壓縮配置設定存活對象,是以整個老生代會産生很多的記憶體碎片。
CMS Failure Mode
上文提到在正常的情況下CMS整個流程的暫停時間都是很短的,一般也就在10ms~100ms左右。然而這與線上的情況并不相符,線上叢集在讀寫壓力很大的情況下,經常會出現長時間的卡頓,有些卡頓甚至長達幾分鐘,導緻很嚴重的讀寫阻塞,甚至會造成Region Server和Zookeeper之間Session逾時,使得Region Server異常離線。實際上,CMS并不是很完美,它會在兩種場景下産生嚴重的Full GC,接下來分别進行介紹。
Concurrent Failure
這種場景其實比較簡單,假如現在系統正在執行CMS回收老生代空間,在回收的過程中新生代來了一批對象進來,不巧的是,老生代已經沒有空間再容納這些對象了。這種場景下,CMS回收器會停止繼續工作,系統進入 ’stop-the-world’ 模式,并且回收算法會退化為單線程複制算法,重新配置設定整個堆記憶體的存活對象到S0中,釋放所有其他空間。很顯然,整個過程會非常’漫長’。但是這種問題也很容易解決,隻需要讓CMS回收器更早一點回收就可以避免。JVM提供了參數-XX:CMSInitiatingOccupancyFraction=N來設定CMS回收的時機,其中N表示目前老生代已使用記憶體占新生代總記憶體的比例,該值預設為68,可以将該值修改的更小使得回收更早進行。
Promotion Failure
假設此時設定XX:CMSInitiatingOccupancyFraction=60,但是在已使用記憶體還沒有達到總記憶體60%的時候,已經沒有空間容納從新生代遷移的對象了。oh,my god!怎麼會這樣?罪魁禍首就是記憶體碎片,上文中提到CMS算法會産生大量碎片,當碎片容量積累到一定大小之後就會造成上面的場景。這種場景下,CMS回收器一樣會停止工作,進入漫長的 ’stop-the-world’ 模式。JVM也提供了參數 -XX: UseCMSCompactAtFullCollection來減少碎片的産生,這個參數表示會在每次CMS回收垃圾之後執行一次碎片整理,很顯然,這個參數會對性能有比較大的影響,對HBase這種對延遲敏感的業務來說并不是一個完美解決方案。
HBase記憶體碎片統計實驗
在實際線上環境中,很少出現Concurrent Failure模式的Full GC,大多數Full GC場景都是Promotion Failure。我們線上叢集也會每隔半個月左右就會因為Promotion Failure觸發一次Full GC。為了更好地了解CMS政策下記憶體碎片是如何觸發Promotion Failure,接下來我們做一個簡單的實驗:JVM提供了參數 -XX:PrintFLSStatistics=1來列印每次GC前後記憶體碎片的統計資訊,統計資訊主要包括3個次元:Free Space、Max Chunk Size和Num Chunks,其中Free Space表示老生代目前空閑的總記憶體容量,Max Chunk Size表示老生代中最大的記憶體碎片所占的記憶體容量大小,Num Chunks表示老生代中總的記憶體碎片數。我們在測試環境叢集(共4台Region Server)将這個參數設定為1,然後使用一個用戶端YCSB執行Read-And-Write操作,分别統計日志中Free Space和Max Chunk Size兩個名額随時間的變化情況。
測試結果如下圖所示,其中第一張圖表示Total Free Space随時間的變化曲線圖,第二張圖表示Max Chunk Size随時間變化曲線圖。其中橫坐标表示時間,縱坐标表示相應記憶體大小。
根據第一張曲線圖可知,老生代總的空閑記憶體容量維持在300M~400M之間,當記憶體容量到達300M左右時就會進行一次GC,GC後記憶體容量就會又回到400M左右。而第二張曲線圖會更加形象地說明記憶體碎片導緻的Promotion Failure,剛開始随着資料不斷寫入,Max Chunk Size會不斷變小,之後很長一段時間基本維持在30M左右。在橫坐标為1093那點,人為地将寫入的單條資料大小由500Byte變為5M大小,此後Max Chunk Size會再次減小,當減小到一定程度之後曲線會忽然升高到350M左右,經過日志确認,此時JVM發生了Promotion Failure模式的Full GC,持續時間約4.91s。此後一段時間Full GC還在持續發生。
經過上述分析,可以知道:CMS GC會不斷産生記憶體碎片,當碎片小到一定程度之後就會基本維持不變,如果此時業務寫入一些單條資料量很大的KeyValue,就有可能觸發Promotion Failure模式Full GC。
總結
本文首先介紹了兩種常見的Java GC政策,再接着介紹了CMS政策可能引起兩種模式的Full GC,最後通過一個小實驗說明了CMS GC确實産生了記憶體碎片,而且會導緻長時間的Full GC發生。接下來《演進篇》會詳細介紹從一開始HBase是如何針對CMS進行優化處理的,敬請期待!
更多技術分享,請關注網易視訊雲官方網站或者網易視訊雲官方微信(vcloud163)進行交流與咨詢