Brief
一篇arxiv19上的文章,感覺真的挺新的,總結了一下最新的用于3D檢測的
backbone
,其中重要的積累了一些稀疏卷積的基礎架構,剛好最近也在啃稀疏卷積的3D形式,包括了兩部分(submanifold和sp層)。
該文章的結構都是3D卷積的結構,和二維CNN無關
這一篇文章的另外一個版本是《Three-dimensional Backbone Network for 3D Object Detection in Traffic Scenes》
因該是作者換了一個寫法,格式是CVPR的格式,不知道中了沒有。很有意思的是該工作也是和我最近研究的second這一篇工作的基礎上完成的,是以大體結構都是類似的。
Abstruct
- 該文章主要介紹作者設計的一些3D基礎卷積結構
- 居然也能達到sota的效果(在KITTI上)
1 INTRODUCTION
- 批評一下2D卷積運用于3D檢測的問題(Voxel-based)
VoxelNet [15] builds 3 layers of 3D CNN to extract 3D features for region proposal network. However, compressing 3D data into 2D or shallow 3D layers make the network fail to extract reliable 3D features for detection.
- 稀疏3D卷積的形式記憶體占用減少,使得可以設計複雜的網絡結構。
- 3DBN-1:不同分辨率的特征提取整合,bottom to top
- 3DBN-2:包含從下到上和從下到上兩個過程的特征提取
- 這篇文章也是voxel-based 的方法,需要進行規則化。
2 RELATED WORK
- Image-based 3D detection
Deep MANTA
- 3D point cloud-based detection
VoxelNet and SECOND adopt PointNet, to extract features from the low resolution raw point cloud for each voxel.
- Detection by fusing image and 3D point cloud
AVOD-FPN等等等
3 3D BACKBONE NETWORK
要主要研究的部分來了,這一部分主要分為稀疏卷積的運作模式,和作者自己提出的基礎架構。
稀疏卷積
- 作者先給出了些文章約定的記号:
| 記号 | 内容 |
|---|---|
| 小寫字母 | 标量 |
| 大寫字母 | 向量 |
| 粗體大寫字母 | 矩陣 |
| c i n × h i n × w i n × l i n c_{in}×h_{in}×w_{in}×l_{in} cin×hin×win×lin | 3D卷積層輸入資料:長寬高×特征次元 |
| CNN fliter: ( k × k × k × c i n × c o u t , s ) (k × k × k × cin × c_{out}, s) (k×k×k×cin×cout,s) | k表示3D卷積的kernel_size,s表示stride, c o u t 表 示 輸 出 的 維 度 c_{out}表示輸出的次元 cout表示輸出的次元 |
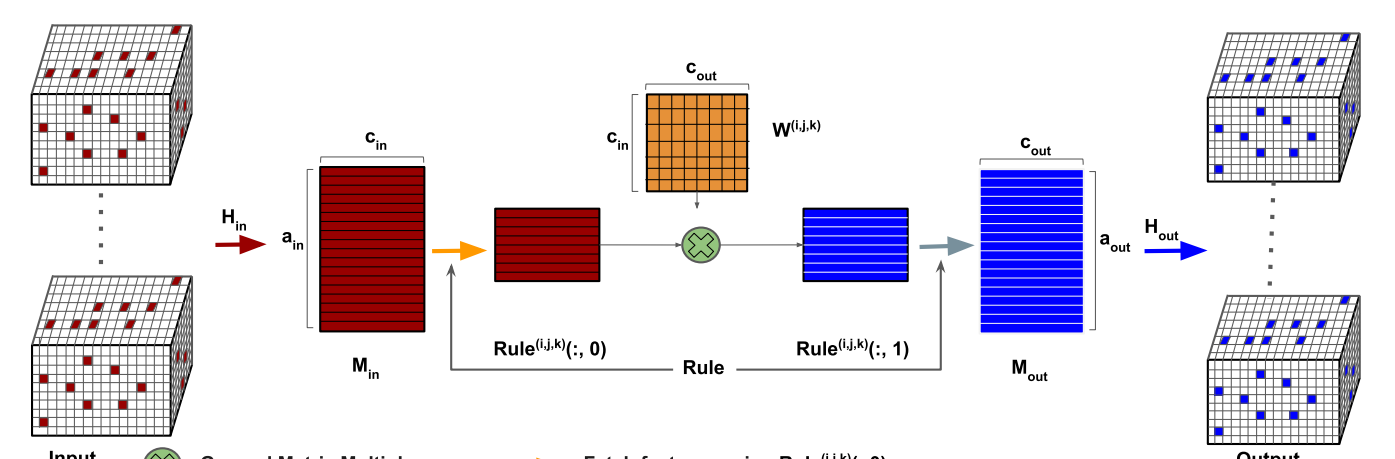
- The pipeline of sparse CNN:
【文章閱讀】3D Backbone Network for 3D Object DetectionBriefAbstruct1 INTRODUCTION2 RELATED WORK3 3D BACKBONE NETWORK
(1)輸入資料就是3D空間的體素全體 M i n M_{in} Min,但是很多的體素實際上是空的
(2)通過哈希表 H i n H_{in} Hin把非空的體素轉化為輸入矩陣 M i n M_{in} Min,其中 a i n a_{in} ain表示的是輸入的非空的體素的個數, c i n c_{in} cin則是每個voxel的特征次元
(3) w i , j , k w^{i,j,k} wi,j,k表示的是特征次元上的變換矩陣。經過變換矩陣得到對應的輸出特征。最後再通過哈希表就得到了變換後的特征。這裡需要指出的是輸出的hash表和輸入的是不一樣的,是比輸入的要大,因為隻要有在kernel中有一個voxel是非空的,那麼就可以得到對應的值
這裡有一個疑問:這裡的stride和kernel這些領域資訊實際上每有描述到,僅僅是把每一個體素内的特征就行了一個特征變換,如何做到類似滑動的卷積?
(5)回答上面提出的這個問題,上面的rule不是指的激活函數,而是指的基于偏移量而得到的輸入和輸出神經元的連接配接規則。原文如下:
The rule book, Rule, depicting neuron connections from the current layer to the next layer is created based on the offset between input points and its corresponding output points.
作者給出的例子是如果偏移量offset(0,0,0),那麼久表示輸入的點在3D kernel的最上-右-前的那一個位置;同樣(f-1,f-1,f-1)對應的輸入時kennel的最下-左-下的位置.
如何建構連接配接規則relu和得到對應的activate points – a o u t a_{out} aout,以及建立輸出的哈希表 H o u t H_{out} Hout作者放到附件,這裡貼上來研究一下:
- RELU

【文章閱讀】3D Backbone Network for 3D Object DetectionBriefAbstruct1 INTRODUCTION2 RELATED WORK3 3D BACKBONE NETWORK
也就是一個更新rule規則的一個方式。後面再研究
- hash out
【文章閱讀】3D Backbone Network for 3D Object DetectionBriefAbstruct1 INTRODUCTION2 RELATED WORK3 3D BACKBONE NETWORK
3D Backone
作者在這篇文章中的主要的貢獻是兩個提高檢測精度的3D backone,實際上,這一項工作的主要是基于second的工作的,如下看一下這兩個主要的3D特征提取網絡。
- 3D BN1
【文章閱讀】3D Backbone Network for 3D Object DetectionBriefAbstruct1 INTRODUCTION2 RELATED WORK3 3D BACKBONE NETWORK
作者的第一個網絡結構采用了自下而上的殘差子產品,僅此而已,在SECOND中實際上是用的稀疏卷積的直連模式,實際上也就4個BLOCK,每一個含有兩層,而這篇文章的第一個網絡是把該4個BLOCK換成了一個殘差連接配接的形式。
- 3D BN2
【文章閱讀】3D Backbone Network for 3D Object DetectionBriefAbstruct1 INTRODUCTION2 RELATED WORK3 3D BACKBONE NETWORK
在二維檢測中,這樣的類似FPN的連接配接結構可以融合多尺度特征。這裡的第二個網絡就是把它給融入到3D的檢測的3D卷積中來。
實驗效果
其實怎麼說呢,這個效果意料之中。現在排到了榜單的46名,比我的高3名。我是垃圾,不錯側面說明,這個改動也不咋的