我們直接結合代碼來講解,
建立一個SimpleTestDemo.java,在裡面分别調用三個子線程(三種編寫方式,其實都一樣):
public class SimpleTestDemo {
public static void main(String[] args) throws InterruptedException {
Thread t1= new Thread(new Runnable() {
@Override
public void run() {
try {
System.out.println("1111111111111 Thread");
} catch (Exception e) {
e.printStackTrace();
}
}
});
//運作子線程 1
t1.start();
Thread t2=new Thread(() -> {
try {
System.out.println("2222222222222 Thread");
} catch (Exception e) {
e.printStackTrace();
}
});
//運作子線程 2
t2.start();
Thread t3= new Thread(() -> System.out.println("3333333333333 Thread"));
//運作子線程 3
t3.start();
//主線程的輸出
System.out.println(" The End !");
}
} 運作結果:
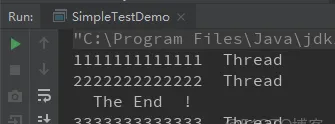

從運作結果,可以看到,三個子線程異步執行,是以導緻每次運作的輸出結果不一定是一樣的,因為都在搶資源。
為了讓這種異步執行的場景模拟更加真實,我們在子線程1上加上sleep(2000):
再看看運作結果,因為子線程1執行時間久,是以最後才執行完畢:
OK,接下來就是Thread.join()的運用了。
雖然子線程1執行得久,但是我們依然想先確定子線程1被執行完畢後才執行後面的代碼,那麼我們就需要調用子線程1的join()方法:
這樣我們再看看運作結果,盡管子線程1執行了很久,但是其他的代碼依然等待子線程1執行完畢再進行執行:
到這裡,很明顯已經看到了join的作用了,簡單來說,就是主線程跟各子線程之間其實都是異步的執行的;
但是如果使用了某個子線程的join()方法,那麼就是 強行在此刻轉變成了同步執行,也就是後面還未執行的代碼(子線程調用等),都必須等,等到使用join()方法的線程執行完畢才能繼續放飛自我。
那麼join方法還有其他作用麼, 有的,在調用的時候發現是可以填入參數的:
這個參數,毫秒,作用是什麼呢?
作用是最大等待時間,也就是說雖然使用了join(),後面的代碼需要等待這個子線程執行完畢後才能開始運作,但是我們如果想實作,如果這子線程執行時間超過某個限制,我們就不等了,直接執行後面的代碼,這麼我們隻需要把限制時間毫秒級别作為參數填入join()即可。
之前我們子線程1 sleep(2000),那麼我們就嘗試下join(1000),也就是說,超過1000毫秒,就不等了:
看看運作結果,雖然子線程1使用了join,但是我們加上了最大等待時間1000毫秒,是以等了1000毫秒後,後面的代碼直接運作了,最後最後子線程1才執行完畢輸出了内容: