目錄
簡介
mean shift 算法理論
Mean Shift算法原理
算法步驟
算法實作
其他
聚類算法之Mean Shift
Mean Shift算法理論
Mean Shift向量
核函數
引入核函數的Mean Shift向量
聚類動畫示範
Mean Shift的代碼實作
算法的Python實作
scikit-learn MeanShift示範
scikit-learn MeanShift源碼分析
簡介
在K-Means算法中,最終的聚類效果受初始的聚類中心的影響,K-Means++算法的提出,為選擇較好的初始聚類中心提供了依據,但是算法中,聚類的類别個數k仍需事先制定,對于類别個數事先未知的資料集,K-Means和K-Means++将很難對其精确求解,對此,有一些改進的算法被提出來處理聚類個數k未知的情形。Mean Shift算法,又被稱為均值漂移算法,與K-Means算法一樣,都是基于聚類中心的聚類算法,不同的是,Mean Shift算法不需要事先制定類别個數k。
Mean Shift的概念最早是由Fukunage在1975年提出的,在後來由Yizong Cheng對其進行擴充,主要提出了兩點的改進:定義了核函數,增加了權重系數。核函數的定義使得偏移值對偏移向量的貢獻随之樣本與被偏移點的距離的不同而不同。權重系數使得不同樣本的權重不同。
Mean Shift算法在很多領域都有成功應用,例如圖像平滑、圖像分割、物體跟蹤等,這些屬于人工智能裡面模式識别或計算機視覺的部分;另外也包括正常的聚類應用。
- 圖像平滑:圖像最大品質下的像素壓縮;
- 圖像分割:跟圖像平滑類似的應用,但最終是将可以平滑的圖像進行分離已達到前後景或固定實體分割的目的;
- 目标跟蹤:例如針對監控視訊中某個人物的動态跟蹤;
- 正常聚類,如使用者聚類等。
mean shift 算法理論
Mean shift 算法是基于核密度估計的爬山算法,可用于聚類、圖像分割、跟蹤等,因為最近搞一個項目,涉及到這個算法的圖像聚類實作,是以這裡做下筆記。
(1)均值漂移的基本形式 給定d維空間的n個資料點集X,那麼對于空間中的任意點x的mean shift向量基本形式可以表示為: 這個向量就是漂移向量,其中Sk表示的是資料集的點到x的距離小于球半徑h的資料點。也就是: 而漂移的過程,說的簡單一點,就是通過計算得漂移向量,然後把球圓心x的位置更新一下,更新公式為: 使得圓心的位置一直處于力的平衡位置。 總結為一句話就是:求解一個向量,使得圓心一直往資料集密度最大的方向移動。說的再簡單一點,就是每次疊代的時候,都是找到圓裡面點的平均位置作為新的圓心位置。
(2)加入核函數的漂移向量 這個說的簡單一點就是加入一個高斯權重,最後的漂移向量計算公式為: 是以每次更新的圓心坐标為: 不過我覺得如果用高斯核函數,把這個算法稱為均值漂移有點不合理,既然叫均值漂移,那麼均值應該指的是權重相等,也就是(1)中的公式才能稱之為真正的均值漂移。 我的簡單了解mean shift算法是:實體學上力的合成與物體的運動。每次疊代通過求取力的合成向量,然後讓圓心沿着力的合成方向,移動到新的平衡位置。
本文由ChardLau原創,轉載請添加原文連結https://www.chardlau.com/mean-shift/
今天的文章介紹如何利用
Mean Shift
算法的基本形式對資料進行聚類操作。而有關
Mean Shift
算法加入核函數計算漂移向量部分的内容将不在本文講述範圍内。實際上除了聚類,
Mean Shift
算法還能用于計算機視覺等場合,有關該算法的理論知識請參考這篇文章。
Mean Shift
Mean Shift
下圖展示了
Mean Shift
算法計算飄逸向量的過程:
Mean Shift
Mean Shift
算法的關鍵操作是通過感興趣區域内的資料密度變化計算中心點的漂移向量,進而移動中心點進行下一次疊代,直到到達密度最大處(中心點不變)。從每個資料點出發都可以進行該操作,在這個過程,統計出現在感興趣區域内的資料的次數。該參數将在最後作為分類的依據。
與
K-Means
算法不一樣的是,
Mean Shift
算法可以自動決定類别的數目。與
K-Means
算法一樣的是,兩者都用集合内資料點的均值進行中心點的移動。
算法步驟
下面是有關
Mean Shift
聚類算法的步驟:
- 在未被标記的資料點中随機選擇一個點作為起始中心點center;
- 找出以center為中心半徑為radius的區域中出現的所有資料點,認為這些點同屬于一個聚類C。同時在該聚類中記錄資料點出現的次數加1。
- 以center為中心點,計算從center開始到集合M中每個元素的向量,将這些向量相加,得到向量shift。
- center = center + shift。即center沿着shift的方向移動,移動距離是||shift||。
- 重複步驟2、3、4,直到shift的很小(就是疊代到收斂),記住此時的center。注意,這個疊代過程中遇到的點都應該歸類到簇C。
- 如果收斂時目前簇C的center與其它已經存在的簇C2中心的距離小于門檻值,那麼把C2和C合并,資料點出現次數也對應合并。否則,把C作為新的聚類。
- 重複1、2、3、4、5直到所有的點都被标記為已通路。
- 分類:根據每個類,對每個點的通路頻率,取通路頻率最大的那個類,作為目前點集的所屬類。
算法實作
下面使用
Python
實作了
Mean Shift
算法的基本形式:
import numpy as np
import matplotlib.pyplot as plt
# Input data set
X = np.array([
[-4, -3.5], [-3.5, -5], [-2.7, -4.5],
[-2, -4.5], [-2.9, -2.9], [-0.4, -4.5],
[-1.4, -2.5], [-1.6, -2], [-1.5, -1.3],
[-0.5, -2.1], [-0.6, -1], [0, -1.6],
[-2.8, -1], [-2.4, -0.6], [-3.5, 0],
[-0.2, 4], [0.9, 1.8], [1, 2.2],
[1.1, 2.8], [1.1, 3.4], [1, 4.5],
[1.8, 0.3], [2.2, 1.3], [2.9, 0],
[2.7, 1.2], [3, 3], [3.4, 2.8],
[3, 5], [5.4, 1.2], [6.3, 2]
])
def mean_shift(data, radius=2.0):
clusters = []
for i in range(len(data)):
cluster_centroid = data[i]
cluster_frequency = np.zeros(len(data))
# Search points in circle
while True:
temp_data = []
for j in range(len(data)):
v = data[j]
# Handle points in the circles
if np.linalg.norm(v - cluster_centroid) <= radius:
temp_data.append(v)
cluster_frequency[i] += 1
# Update centroid
old_centroid = cluster_centroid
new_centroid = np.average(temp_data, axis=0)
cluster_centroid = new_centroid
# Find the mode
if np.array_equal(new_centroid, old_centroid):
break
# Combined 'same' clusters
has_same_cluster = False
for cluster in clusters:
if np.linalg.norm(cluster['centroid'] - cluster_centroid) <= radius:
has_same_cluster = True
cluster['frequency'] = cluster['frequency'] + cluster_frequency
break
if not has_same_cluster:
clusters.append({
'centroid': cluster_centroid,
'frequency': cluster_frequency
})
print('clusters (', len(clusters), '): ', clusters)
clustering(data, clusters)
show_clusters(clusters, radius)
# Clustering data using frequency
def clustering(data, clusters):
t = []
for cluster in clusters:
cluster['data'] = []
t.append(cluster['frequency'])
t = np.array(t)
# Clustering
for i in range(len(data)):
column_frequency = t[:, i]
cluster_index = np.where(column_frequency == np.max(column_frequency))[0][0]
clusters[cluster_index]['data'].append(data[i])
# Plot clusters
def show_clusters(clusters, radius):
colors = 10 * ['r', 'g', 'b', 'k', 'y']
plt.figure(figsize=(5, 5))
plt.xlim((-8, 8))
plt.ylim((-8, 8))
plt.scatter(X[:, 0], X[:, 1], s=20)
theta = np.linspace(0, 2 * np.pi, 800)
for i in range(len(clusters)):
cluster = clusters[i]
data = np.array(cluster['data'])
plt.scatter(data[:, 0], data[:, 1], color=colors[i], s=20)
centroid = cluster['centroid']
plt.scatter(centroid[0], centroid[1], color=colors[i], marker='x', s=30)
x, y = np.cos(theta) * radius + centroid[0], np.sin(theta) * radius + centroid[1]
plt.plot(x, y, linewidth=1, color=colors[i])
plt.show()
mean_shift(X, 2.5)
代碼連結
上述代碼執行結果如下:

執行結果
其他
Mean Shift
算法還有很多内容未提及。其中有“動态計算感興趣區域半徑”、“加入核函數計算漂移向量”等。本文作為入門引導,暫時隻覆寫這些内容。
聚類算法之Mean Shift
https://www.biaodianfu.com/mean-shift.html
Mean Shift算法理論
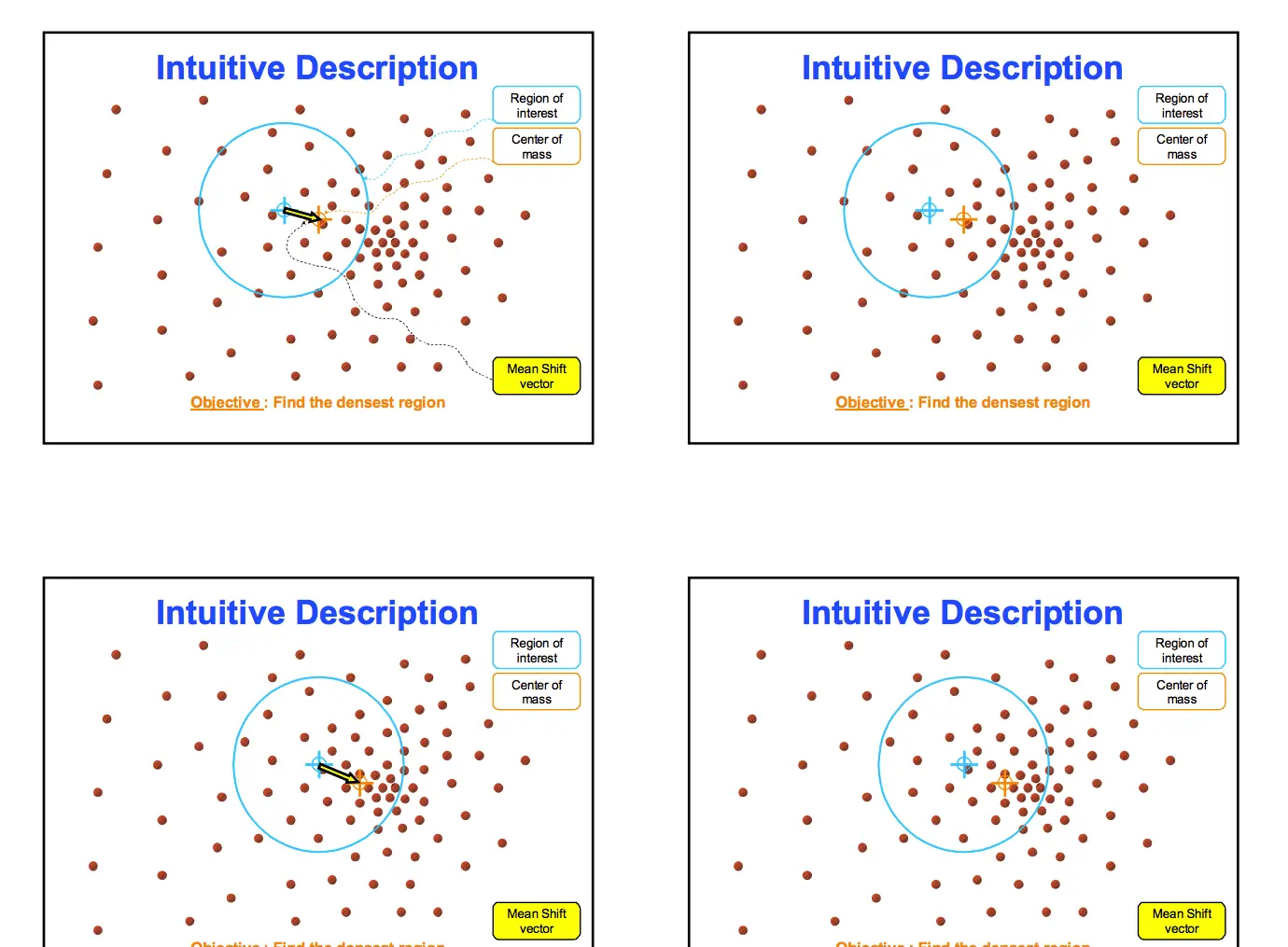
Mean Shift向量
對于給定的
維空間
中的n個樣本點
,則對于x點,其Mean Shift向量的基本形式為:
其中,
指的是一個半徑為h的高維球區域,如上圖中的圓形區域。
的定義為:
裡面所有點與圓心為起點形成的向量相加的結果就是Mean shift向量。下圖黃色箭頭就是
(Mean Shift向量)。
對于Mean Shift算法,是一個疊代的步驟,即先算出目前點的偏移均值,将該點移動到此偏移均值,然後以此為新的起始點,繼續移動,直到滿足最終的條件。
Mean-Shift 聚類就是對于集合中的每一個元素,對它執行下面的操作:把該元素移動到它鄰域中所有元素的特征值的均值的位置,不斷重複直到收斂。準确的說,不是真正移動元素,而是把該元素與它的收斂位置的元素标記為同一類。
如上的均值漂移向量的求解方法存在一個問題,即在
的區域内,每一個樣本點x對樣本X的共享是一樣的。而實際中,每一個樣本點x對樣本X的貢獻是不一樣的,這樣的共享可以通過核函數進行度量。
核函數
在Mean Shift算法中引入核函數的目的是使得随着樣本與被偏移點的距離不同,其偏移量對均值偏移向量的貢獻也不同。核函數是機器學習中常用的一種方式。核函數的定義如下所示:
X 表示一個d維的歐式空間,x 是該空間中的一個點
,其中,x的模
,R表示實數域,如果一個函數K:X→R存在一個剖面函數k:[0,∞]→R,即
并且滿足:
- k是非負的
- k是非增的
- k是分段連續的
那麼,函數K(x)就稱為核函數。
核函數有很多,下圖中表示的每一個曲線都為一個核函數。
常用的核函數有高斯核函數。高斯核函數如下所示:
其中,h稱為帶寬(bandwidth),不同帶寬的核函數如下圖所示:
從高斯函數的圖像可以看出,當帶寬h一定時,樣本點之間的距離越近,其核函數的值越大,當樣本點之間的距離相等時,随着高斯函數的帶寬h的增加,核函數的值在減小。
高斯核函數的Python實作:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # -*- coding:utf-8 -*- import numpy as np import math def gaussian_kernel(distance, bandwidth): ''' 高斯核函數 :param distance: 歐氏距離計算函數 :param bandwidth: 核函數的帶寬 :return: 高斯函數值 ''' m = np.shape(distance)[0] # 樣本個數 right = np.mat(np.zeros((m, 1))) # m * 1 矩陣 for i in range(m): right[i, 0] = (-0.5 * distance[i] * distance[i].T) / (bandwidth * bandwidth) right[i, 0] = np.exp(right[i, 0]) left = 1 / (bandwidth * math.sqrt(2 * math.pi)) gaussian_val = left * right return gaussian_val |
引入核函數的Mean Shift向量
假設在半徑為h的範圍
範圍内,為了使得每一個樣本點x對于樣本X的共享不一樣,向基本的Mean Shift向量形式中增加核函數,得到如下改進的Mean Shift向量形式:
其中,
為核函數。通常,可以取
為整個資料集範圍。
計算
時考慮距離的影響,同時也可以認為在所有的樣本點X中,重要性并不一樣,是以對每個樣本還引入一個權重系數。如此以來就可以把Mean Shift形式擴充為:
其中,
是一個賦給采樣點的權重。
聚類動畫示範
Mean Shift的代碼實作
算法的Python實作
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 | import numpy as np import math MIN_DISTANCE = 0.00001 # 最小誤差 def euclidean_dist(pointA, pointB): # 計算pointA和pointB之間的歐式距離 total = (pointA - pointB) * (pointA - pointB).T return math.sqrt(total) def gaussian_kernel(distance, bandwidth): ''' 高斯核函數 :param distance: 歐氏距離計算函數 :param bandwidth: 核函數的帶寬 :return: 高斯函數值 ''' m = np.shape(distance)[0] # 樣本個數 right = np.mat(np.zeros((m, 1))) for i in range(m): right[i, 0] = (-0.5 * distance[i] * distance[i].T) / (bandwidth * bandwidth) right[i, 0] = np.exp(right[i, 0]) left = 1 / (bandwidth * math.sqrt(2 * math.pi)) gaussian_val = left * right return gaussian_val def shift_point(point, points, kernel_bandwidth): '''計算均值漂移點 :param point: 需要計算的點 :param points: 所有的樣本點 :param kernel_bandwidth: 核函數的帶寬 :return: point_shifted:漂移後的點 ''' points = np.mat(points) m = np.shape(points)[0] # 樣本個數 # 計算距離 point_distances = np.mat(np.zeros((m, 1))) for i in range(m): point_distances[i, 0] = euclidean_dist(point, points[i]) # 計算高斯核 point_weights = gaussian_kernel(point_distances, kernel_bandwidth) # 計算分母 all = 0.0 for i in range(m): all += point_weights[i, 0] # 均值偏移 point_shifted = point_weights.T * points / all return point_shifted def group_points(mean_shift_points): '''計算所屬的類别 :param mean_shift_points:漂移向量 :return: group_assignment:所屬類别 ''' group_assignment = [] m, n = np.shape(mean_shift_points) index = 0 index_dict = {} for i in range(m): item = [] for j in range(n): item.append(str(("%5.2f" % mean_shift_points[i, j]))) item_1 = "_".join(item) if item_1 not in index_dict: index_dict[item_1] = index index += 1 for i in range(m): item = [] for j in range(n): item.append(str(("%5.2f" % mean_shift_points[i, j]))) item_1 = "_".join(item) group_assignment.append(index_dict[item_1]) return group_assignment def train_mean_shift(points, kernel_bandwidth=2): '''訓練Mean Shift模型 :param points: 特征資料 :param kernel_bandwidth: 核函數帶寬 :return: points:特征點 mean_shift_points:均值漂移點 group:類别 ''' mean_shift_points = np.mat(points) max_min_dist = 1 iteration = 0 m = np.shape(mean_shift_points)[0] # 樣本的個數 need_shift = [True] * m # 标記是否需要漂移 # 計算均值漂移向量 while max_min_dist > MIN_DISTANCE: max_min_dist = 0 iteration += 1 print("iteration : " + str(iteration)) for i in range(0, m): # 判斷每一個樣本點是否需要計算偏置均值 if not need_shift[i]: continue p_new = mean_shift_points[i] p_new_start = p_new p_new = shift_point(p_new, points, kernel_bandwidth) # 對樣本點進行偏移 dist = euclidean_dist(p_new, p_new_start) # 計算該點與漂移後的點之間的距離 if dist > max_min_dist: # 記錄是有點的最大距離 max_min_dist = dist if dist < MIN_DISTANCE: # 不需要移動 need_shift[i] = False mean_shift_points[i] = p_new # 計算最終的group group = group_points(mean_shift_points) # 計算所屬的類别 return np.mat(points), mean_shift_points, group |
以上代碼實作了基本的流程,但是執行效率很慢,正式使用時建議使用scikit-learn庫中的MeanShift。
scikit-learn MeanShift示範
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | import numpy as np from sklearn.cluster import MeanShift, estimate_bandwidth data = [] f = open("k_means_sample_data.txt", 'r') for line in f: data.append([float(line.split(',')[0]), float(line.split(',')[1])]) data = np.array(data) # 通過下列代碼可自動檢測bandwidth值 # 從data中随機選取1000個樣本,計算每一對樣本的距離,然後選取這些距離的0.2分位數作為傳回值,當n_samples很大時,這個函數的計算量是很大的。 bandwidth = estimate_bandwidth(data, quantile=0.2, n_samples=1000) print(bandwidth) # bin_seeding設定為True就不會把所有的點初始化為核心位置,進而加速算法 ms = MeanShift(bandwidth=bandwidth, bin_seeding=True) ms.fit(data) labels = ms.labels_ cluster_centers = ms.cluster_centers_ # 計算類别個數 labels_unique = np.unique(labels) n_clusters = len(labels_unique) print("number of estimated clusters : %d" % n_clusters) # 畫圖 import matplotlib.pyplot as plt from itertools import cycle plt.figure(1) plt.clf() # 清楚上面的舊圖形 # cycle把一個序列無限重複下去 colors = cycle('bgrcmyk') for k, color in zip(range(n_clusters), colors): # current_member表示标簽為k的記為true 反之false current_member = labels == k cluster_center = cluster_centers[k] # 畫點 plt.plot(data[current_member, 0], data[current_member, 1], color + '.') #畫圈 plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=color, #圈内顔色 markeredgecolor='k', #圈邊顔色 markersize=14) #圈大小 plt.title('Estimated number of clusters: %d' % n_clusters) plt.show() |
執行效果:
scikit-learn MeanShift源碼分析
源碼位址:https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/cluster/mean_shift_.py
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 | def mean_shift(X, bandwidth=None, seeds=None, bin_seeding=False, min_bin_freq=1, cluster_all=True, max_iter=300, n_jobs=1): """Perform mean shift clustering of data using a flat kernel. Read more in the :ref:`User Guide <mean_shift>`. Parameters ---------- X : array-like, shape=[n_samples, n_features] Input data. bandwidth : float, optional Kernel bandwidth. If bandwidth is not given, it is determined using a heuristic based on the median of all pairwise distances. This will take quadratic time in the number of samples. The sklearn.cluster.estimate_bandwidth function can be used to do this more efficiently. seeds : array-like, shape=[n_seeds, n_features] or None Point used as initial kernel locations. If None and bin_seeding=False, each data point is used as a seed. If None and bin_seeding=True, see bin_seeding. bin_seeding : boolean, default=False If true, initial kernel locations are not locations of all points, but rather the location of the discretized version of points, where points are binned onto a grid whose coarseness corresponds to the bandwidth. Setting this option to True will speed up the algorithm because fewer seeds will be initialized. Ignored if seeds argument is not None. min_bin_freq : int, default=1 To speed up the algorithm, accept only those bins with at least min_bin_freq points as seeds. cluster_all : boolean, default True If true, then all points are clustered, even those orphans that are not within any kernel. Orphans are assigned to the nearest kernel. If false, then orphans are given cluster label -1. max_iter : int, default 300 Maximum number of iterations, per seed point before the clustering operation terminates (for that seed point), if has not converged yet. n_jobs : int The number of jobs to use for the computation. This works by computing each of the n_init runs in parallel. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one are used. .. versionadded:: 0.17 Parallel Execution using *n_jobs*. Returns ------- cluster_centers : array, shape=[n_clusters, n_features] Coordinates of cluster centers. labels : array, shape=[n_samples] Cluster labels for each point. Notes ----- See examples/cluster/plot_mean_shift.py for an example. """ #沒有定義bandwidth執行函數estimate_bandwidth估計帶寬 if bandwidth is None: bandwidth = estimate_bandwidth(X, n_jobs=n_jobs) #帶寬小于0就報錯 elif bandwidth <= 0: raise ValueError("bandwidth needs to be greater than zero or None,\ got %f" % bandwidth) #如果沒有設定種子 if seeds is None: #通過get_bin_seeds選取種子 #min_bin_freq指定最少的種子數目 if bin_seeding: seeds = get_bin_seeds(X, bandwidth, min_bin_freq) #把所有點設為種子 else: seeds = X #根據shape得到樣本數量和特征數量 n_samples, n_features = X.shape #中心強度字典 鍵為點 值為強度 center_intensity_dict = {} #近鄰搜尋 fit的傳回值為 #radius意思是半徑 表示參數空間的範圍 #用作于radius_neighbors 可以了解為在半徑範圍内找鄰居 nbrs = NearestNeighbors(radius=bandwidth, n_jobs=n_jobs).fit(X) #并行地在所有種子上執行疊代 #all_res為所有種子的疊代完的中心以及周圍的鄰居數 # execute iterations on all seeds in parallel all_res = Parallel(n_jobs=n_jobs)( delayed(_mean_shift_single_seed) (seed, X, nbrs, max_iter) for seed in seeds) #周遊所有結果 # copy results in a dictionary for i in range(len(seeds)): #隻有這個點的周圍沒有鄰居才會出現None的情況 if all_res[i] is not None: #一個中心點對應一個強度(周圍鄰居個數) center_intensity_dict[all_res[i][0]] = all_res[i][1] #要是一個符合要求的點都沒有,就說明bandwidth設定得太小了 if not center_intensity_dict: # nothing near seeds raise ValueError("No point was within bandwidth=%f of any seed." " Try a different seeding strategy \ or increase the bandwidth." % bandwidth) # POST PROCESSING: remove near duplicate points # If the distance between two kernels is less than the bandwidth, # then we have to remove one because it is a duplicate. Remove the # one with fewer points. #按照強度來排序 #dict.items()傳回值形式為[(key1,value1),(key2,value2)...] #reverse為True表示由大到小 #key的lambda表達式用來指定用作比較的部分為value sorted_by_intensity = sorted(center_intensity_dict.items(), key=lambda tup: tup[1], reverse=True) #單獨把排好序的點分出來 sorted_centers = np.array([tup[0] for tup in sorted_by_intensity]) #傳回長度和點數量相等的bool類型array unique = np.ones(len(sorted_centers), dtype=np.bool) #在這些點裡再來一次找鄰居 nbrs = NearestNeighbors(radius=bandwidth, n_jobs=n_jobs).fit(sorted_centers) #enumerate傳回的是index,value #還是類似于之前的找鄰居 不過這次是為了剔除相近的點 就是去除重複的中心 #因為是按強度由大到小排好序的 是以優先将靠前的當作确定的中心 for i, center in enumerate(sorted_centers): if unique[i]: neighbor_idxs = nbrs.radius_neighbors([center], return_distance=False)[0] #中心的鄰居不能作為候選 unique[neighbor_idxs] = 0 #因為這個範圍内肯定包含自己,是以要單獨标為1 unique[i] = 1 # leave the current point as unique #把篩選過後的中心拿出來 就是最終的聚類中心 cluster_centers = sorted_centers[unique] #配置設定标簽:最近的類就是這個點的類 # ASSIGN LABELS: a point belongs to the cluster that it is closest to #把中心放進去 用kneighbors來找鄰居 #n_neighbors标為1 使找到的鄰居數為1 也就成了标簽 nbrs = NearestNeighbors(n_neighbors=1, n_jobs=n_jobs).fit(cluster_centers) #labels用來存放标簽 labels = np.zeros(n_samples, dtype=np.int) #所有點帶進去求 distances, idxs = nbrs.kneighbors(X) #cluster_all為True表示所有的點都會被聚類 if cluster_all: #flatten可以簡單了解如下 #>>> np.array([[[[1,2]],[[3,4]],[[5,6]]]]).flatten() #array([1, 2, 3, 4, 5, 6]) labels = idxs.flatten() #為False就把距離大于bandwidth的點類别标為-1 else: #先全标-1 labels.fill(-1) #距離小于bandwidth的标False bool_selector = distances.flatten() <= bandwidth #标True的才能參與聚類 labels[bool_selector] = idxs.flatten()[bool_selector] #傳回的結果為聚類中心和每個樣本的标簽 return cluster_centers, labels |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | # separate function for each seed's iterative loop def _mean_shift_single_seed(my_mean, X, nbrs, max_iter): #對于每個種子,梯度上升,直到收斂或者到達max_iter次疊代次數 # For each seed, climb gradient until convergence or max_iter bandwidth = nbrs.get_params()['radius'] #表示收斂時的門檻值 stop_thresh = 1e-3 * bandwidth # when mean has converged #記錄完成的疊代次數 completed_iterations = 0 while True: #radius_neighbors尋找my_mean周圍的鄰居 #i_nbrs是符合要求的鄰居的下标 # Find mean of points within bandwidth i_nbrs = nbrs.radius_neighbors([my_mean], bandwidth, return_distance=False)[0] #根據下标找點 points_within = X[i_nbrs] #找不到點就跳出疊代 if len(points_within) == 0: break # Depending on seeding strategy this condition may occur #儲存舊的均值 my_old_mean = my_mean # save the old mean #移動均值,這就是mean-shift名字的由來,每一步的疊代就是計算新的均值點 my_mean = np.mean(points_within, axis=0) #用歐幾裡得範數與門檻值進行比較判斷收斂 或者 #判斷疊代次數達到上限 # If converged or at max_iter, adds the cluster if (extmath.norm(my_mean - my_old_mean) < stop_thresh or completed_iterations == max_iter): #傳回收斂時的均值中心和周圍鄰居個數 #tuple表示轉換成元組 因為之後的center_intensity_dict鍵不能為清單 return tuple(my_mean), len(points_within) #疊代次數增加 completed_iterations += 1 |
參考資料:
- http://scikit-learn.org/stable/modules/generated/sklearn.cluster.MeanShift.html
- https://blog.csdn.net/jiaqiangbandongg/article/details/53557500