大家好,我是Python進階者。
一、前言
前幾天在才哥的Python交流群遇到了一個粉絲提問,提問截圖如下:
覺得還挺有意思的,都是
Pandas
基礎操作,這裡拿出來給大家一起分享下。
二、實作過程
這裡【dcpeng】給了一個代碼,如下所示:
import pandas as pd
df = pd.read_excel('test.xlsx')
df["标記列"] = df[["字元串1", "字元串2"]].apply(lambda x: len(set(x['字元串1']) & set(x['字元串2'])) > 0, axis=1)
print(df) 不過得到的是
True
和
False
,如下圖所示:

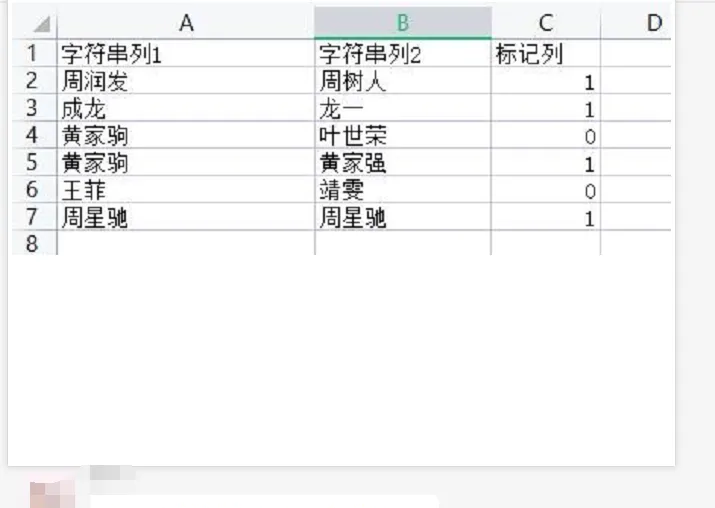
這裡稍微優化了下,直接得到0,1,三個方法,一起學習下。
【方法一】代碼如下:
import pandas as pd
df = pd.read_excel('test.xlsx')
df["标記列"] = df[["字元串1", "字元串2"]].apply(lambda x: len(set(x['字元串1']) & set(x['字元串2'])) > 0, axis=1)
bool_map = {True: 1, False: 0}
df['new_标記列'] = df['标記列'].map(bool_map)
print(df) 可以得到如下的結果:
【方法二】代碼如下:
import pandas as pd
df = pd.read_excel('test.xlsx')
df["标記列"] = df[["字元串1", "字元串2"]].apply(lambda x: 1 if len(set(x['字元串1']) & set(x['字元串2'])) > 0 else 0, axis=1) 同樣可以得到相同的結果。
【方法三】代碼如下:
import pandas as pd
df = pd.read_excel('test.xlsx')
df["标記列"] = df.apply(lambda x: 1 if len(set(x['字元串1']) & set(x['字元串2'])) > 0 else 0, axis=1)
print(df) 後來發現是可以繼續優化的,是以就有了上述代碼。