消費者
消費組
-
kafka消費組是消費組的一部分,當多個消費者形成一個消費組來消費主題時,
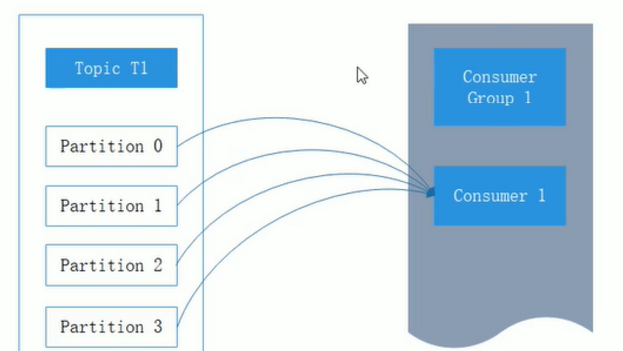
每個消費者會受到不同分區的消息,假設有一個T1主題,該主題有4個分區,
同時我們有一個消費組G1,這個消費組隻有一個消費者C1,那麼消費組C1将會受到這4個分區的消息
kafka之五 消費者消費者 - 特性之一:隻需寫入一次消息,可以支援任意多的應用讀取這個消息
kafkaConsumer參數
- bootstrap.servers:該參數和kafkaProducer中相同,指定連接配接kafka叢集所需要的broker位址清單,可以設定一個或多個
- group.id:消費組隸屬的消費組,預設為空,如果設定為空,則會抛出一行,這個參數要設定成一定業務含義的名稱
- client.id:指定kafkaConsumer對應的用戶端id,預設為空,如果不設定kafkaConsumer會自動生成一個非空字元串
訂閱主題和分區
- 建立完消費組,可以訂閱主題,隻需要調用subscrbe方法即可,這個方法接受一個主題清單
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic)) ;
- 也可以使用正規表達式來比對主題
consumer.sunscribe(Pattern.compile("topicName"));
- 指定訂閱的分區
consumer.assign(Arrays.asList(new TopicPartition("topic",0)));
反序列化
// 要和kafkaProducer中設定保持一緻
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
位移送出
- 對于kafka中的分區而言,他的沒條消息都有位移的offset,用來表示消息在分區中的位置
-
當我們調用poll()時,該方法會傳回我們沒有消費的消息,當消息從broker傳回消費組時,
broker并不跟蹤這些消息是否被消費組接收到,kafka讓消費組自身來管理消費的位移,并向消費者
提供更新唯一的接口,這種更新唯一的方式成為送出

kafka之五 消費者消費者 - 自動送出
-
自動送出隻需要把enable.auto.commit設定為true,
消費者會在poll方法調用後每隔5秒(由auto.commit.interval.ms指定)送出一次唯一,自動送出
也是由poll方法來驅動的.調用poll時,消費組判斷是否到達送出時間,如果是則送出上一次poll傳回的最大位移
-
但是這方式可能會導緻消息重複消費,某個消費組poll消息後,應用正在處理消息,在3秒後kafka進行重平衡,
那麼由于沒有更新唯一導緻重平衡後這部分消息重複消費
-
- 同步送出
- 隻需将ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG設定為false
- 異步送出
-
手動送出有一個缺點,就是當發起送出調用時應用會阻塞,當然我們可以減少手動送出的頻率,
但是這個會增加消息重複的機率,另外一個解決方法是,使用異步送出的API
-
異步送出也有一個缺點,就是伺服器傳回送出失敗,異步送出是不會進行重試,同步送出會進行重試
直到成功或者最後抛出異常給應用.
-
consumer.commitAsync(new OffsetCommitCallback(){
@Override
public void onComplete(Map<TopicPartition,OffsetAndMetadata> offsets,
Exception,exception){
if(exception == null){
System.out.pritln(offset);
}else{
log.error("fail commit offsets {}",offsets,exception);
}
}
});
- 指定位移消費
-
seek方法隻能充值消費組配置設定到的分區的消費位置,而分區的配置設定是在poll方法調用過程中實作的
,也就是說在seek方法之前要先執行一次poll方法
- seek方法可以追蹤以前的消費或回溯消費,以下看出需要指定partitin和開始消費的offset
/** * @see KafkaConsumer#seek(TopicPartition, long) */ public void seek(TopicPartition partition, long offset);- 也可以從結尾處開始消費回來
Set <TopicPartition>assignment = kafkaConsumer.assignment(); Map <TopicPartition,Long> endOffsets = kafkaConsumer.endOffsets(assignment); for(TopicPartition tp:assigment){ kafkaConsumer.seek(tp,endOffsets.get(tp)); }- 位移越界(這個是查不到資料的)
for(TopicPartition tp:assigment){ kafkaConsumer.seek(tp,endOffsets.get(tp)+1); }
-
- 再均衡監聽器
-
再均衡是指分區的所屬從一個消費者轉移到另外一個消費者的行為,它為消費組具備了高可用性
和伸縮性提供了保障,使得他們既友善又安全的删除消費組中的消費組或者往消費組内添加消費者.
不過再均衡發生期間,消費者是無法來取消息的
-
- 消費者攔截器
-
主要是在消費得到消息或發生消費位移時進行的一些定制化操作.和生産者攔截器一樣,
實作ConsumerInterceptor接口,在onConsume裡面寫邏輯
-
- 消費組參數補充
- fetch.min.bytes:運作消費組指定從broker讀取消息時最小的資料量,可以減少往返時間,減輕broker壓力
- fetch.max.wait.ms:消費組杜讀取最長等待時間,避免長時間阻塞,預設500ms
- max.partition.fetch.bytes:指定每個分區傳回的最多位元組數,預設為1M
- max.poll.records:這個參數控制一個poll()調用傳回的記錄數,可以控制應用在拉取循環中的處理資料量