文章目錄
- RDD 序列化
- 1、閉包檢查
- 2、序列化方法和屬性
- 3、Kryo 序列化架構
RDD 序列化
1、閉包檢查
從計算的角度, 算子以外的代碼都是在 Driver 端執行, 算子裡面的代碼都是在 Executor 端執行。那麼在 scala 的函數式程式設計中,就會導緻
算子内經常會用到算子外的資料,這樣就形成了閉包的效果
,如果使用的算子外的資料無法序列化,就意味着無法傳值給Executor端執行,就會發生錯誤,是以需要在執行任務計算前,檢測閉包内的對象是否可以進行序列化,這個操作我們稱之為閉包檢測。Scala2.12 版本後閉包編譯方式發生了改變。
傳回頂部
2、序列化方法和屬性
從計算的角度, 算子以外的代碼都是在 Driver 端執行, 算子裡面的代碼都是在 Executor端執行,看如下代碼:
object serializable02_function {
def main(args: Array[String]): Unit = {
// 1.建立 SparkConf 并設定 App 名稱
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
// 2.建立 SparkContext,該對象是送出 Spark App 的入口
val sc: SparkContext = new SparkContext(conf)
// 3.建立一個 RDD
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
// 3.1 建立一個 Search 對象
val search = new Search("hello")
// 3.2 函數傳遞,列印:ERROR Task not serializable
search.getMatch1(rdd).collect().foreach(println)
// 3.3 屬性傳遞,列印:ERROR Task not serializable
search.getMatch2(rdd).collect().foreach(println)
// 4.關閉連接配接
sc.stop()
}
}
class Search(query:String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函數序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
//rdd.filter(this.isMatch)
rdd.filter(isMatch)
}
// 屬性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
//rdd.filter(x => x.contains(this.query))
rdd.filter(x => x.contains(query))
//val q = query
//rdd.filter(x => x.contains(q))
}
} 類的構造參數其實是類的屬性(即query屬性),構造參數需要進行閉包檢測,其實就等共同于類進行閉包檢測。
無論是調用getMatch1還是getMatch2都直接或間接地需要用到query屬性,而算子以外的代碼都是在 Driver 端執行, 算子裡面的代碼都是在 Executor端執行,是以這裡的query是存在與Driver中,但是計算存在于Executor,是以在使用query的時候必須将Search類進行序列化。
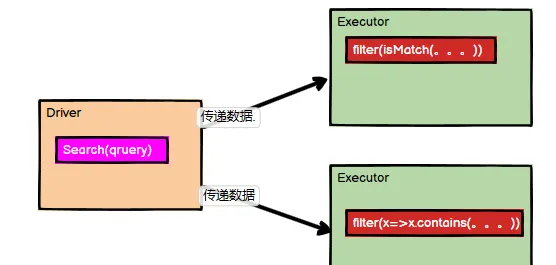
在作業job送出之前,其中有一行代碼,
val cleanF = sc.clean(f)
, 用于進行閉包檢測,之是以叫閉包檢測,是因為目前函數的内部通路了外部函數的變量,屬于閉包的形式。按照這種邏輯,還有一種解決方法,我們在使用query屬性之前将其指派給函數内部的局部變量
val q = query
,然後我們就使用變量q來完成操作:
rdd.filter(x => x.contains(q))
。
傳回頂部
3、Kryo 序列化架構
Java 的序列化能夠序列化任何的類。但是比較重(位元組多),序列化後,對象的送出也比較大。Spark 出于性能的考慮,Spark2.0 開始支援另外一種
Kryo 序列化機制
。Kryo 速度是 Serializable 的 10 倍。當 RDD 在 Shuffle 資料的時候,簡單資料類型、數組和字元串類型已經在 Spark 内部使用 Kryo 來序列化。
注意:即使使用 Kryo 序列化,也要繼承 Serializable 接口(或者使用局部變量)。
package test03_rdd.serializable
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_Kryo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 1、替換預設的序列化機制
.set("spark.serializer",
"org.apache.spark.serializer.KryoSerializer")
// 2、注冊需要使用 kryo 序列化的自定義類
.registerKryoClasses(Array(classOf[Searcher]))
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array("hello world", "hello spark", "scala"), 2)
val searcher = new Searcher("hello")
val result = searcher.getMatchedRDD1(rdd)
result.collect.foreach(println)
}
}
case class Searcher(val query: String) {
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatchedRDD1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
def getMatchedRDD2(rdd: RDD[String]): RDD[String] = {
val q = query
rdd.filter(_.contains(q))
}
} ![Spark流式分析系統實作 流式實時日志分析系統[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)