HashMap源碼閱讀02
- 1、前言
- 2、解答
- 3、提問
- 4、測試與分析
- 5、結論
1、前言
上篇文章《HashMap源碼閱讀01》中記錄了一個問題,當HashMap依次put鍵值對時,并沒有按照由小到大的順序排列,而是跳過了中間幾個數字,今天我們就來一探究竟:
2、解答
我們的測試代碼如下:
@Test
public void test(){
Map<String,Object> map = new HashMap<>();
map.put("a",1);
map.put("b",2);
map.put("c",3);
map.put("d",4);
map.put("Ed",4);
// map.put("E",4);
map.put("F",4);
map.put("G",4);
map.put("hd",4);
// map.put("h",4);
map.put("I",4);
map.put("J",4);
map.put("K",4);
map.put("l",4);
map.put("M",4);
Integer i = (Integer) map.get("a");
System.out.println(i);
}
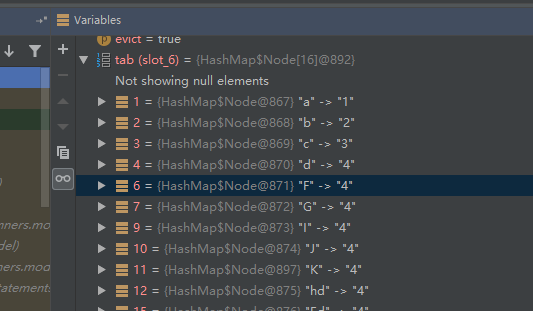
當map放入(“Ed”,4)這個鍵值對時,我們通過debug發現,在進行(n - 1) & hash運算時,得到的結果是15,是以該鍵值對被放入了索引15的位置上。
當map放入(“hd”,4)這個鍵值對時,(n - 1) & hash運算結果是12,是以該鍵值對被放入了索引12的位置上。
…
經過debug調試,我們得知一條規律,在HashMap調用put方法放入鍵值對時,是通過(n - 1) & hash的與運算來确定該鍵值對将放入的索引位置。
我們通過改變測試案例,進一步調試來驗證這條規律。比如将放入鍵值對的順序打亂後,最終連結清單各鍵值對得到的位置排列依舊不變。
我們再來看看(n - 1) & hash這個與運算表達式,裡面有兩個變量:
n:目前連結清單的長度
hash:要進行put操作的鍵值對中的key的hash值
是以,當連結清單長度不變得前提下,進行put操作得各鍵值對是依據各自key的hash值來進行連結清單位置的散列分布。
以上結論,即可解答文章開頭提出的問題。
3、提問
那麼當HashMap多次放入key相同的鍵值對導緻(n - 1) & hash運算的結果相同的情況下,會發生什麼呢?
4、測試與分析
我們一起來看下:
首先,修改我們的測試案例:
map.put("a",1);
map.put("a",11);
讓map同時put(“a”,1)與(“a”,11)兩個鍵值對操作,這樣就造成了最終(n - 1) & hash運算結果相同,我們進入putVal方法:
當進行判斷時,(p = tab[i = (n - 1) & hash]) 不為空,将執行如下代碼:
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
我們分析下這段代碼做了什麼:
首先,定義了兩個變量:
Node<K,V> e; K k;
進入判斷:
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
這裡判斷成立的條件是:
(1)對應位置的節點的hash屬性與目标鍵值對的key的hash值相等
(2)對應位置的節點的key屬性與目标鍵值對的key相同
①如果判斷成立:則将連結清單上目标節點的節點對象指派給變量e.
②如果判斷不成立:也就是說,雖然原鍵值對的key的hash值與目标鍵值對的key的hash值相同,但key本身卻并不一樣。
這裡會判斷原鍵值對對象的類型是否屬于TreeNode:
如果判斷成立,則調用putTreeVal方法。(此方法做了什麼,我們另外說明)
如果判斷不成立,則進入一個for循環,從原節點開始,沿着連結清單往末端周遊節點,這裡有兩種情況可以跳出for循環:
1、滿足上述(1)(2)的判斷條件
2、目前節點無下一節點,即為連結清單末端
我們先看第一種情況,當找到滿足上述(1)(2)的判斷條件的節點時,跳出for循環後執行下面的代碼:
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
當允許替換value或者舊值為空時,可以用新value替換掉舊value.
在HashMap中afterNodeAccess方法實作為空:
void afterNodeAccess(Node<K,V> p) { }
将舊值傳回,方法結束。
接下來我們看第二種情況,目前節點無下一節點,即到達連結清單末端後,執行以下代碼:
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
新建構一個節點對象放在連結清單末端。(還進行了一個判斷,此處不講,另作說明)
5、結論
綜合以上所述,我們得知,HashMap調用put方法發生hash沖突時,HashMap如何解決與處理的。
首先,HashMap會判斷key是否相同,如果是同一個key,則進行value替換操作;如果不是同一個key,但原連結清單節點是TreeNode類型時,會調用putTreeVal方法;如果不是同一個key,而且原連結清單節點不是TreeNode類型時,HashMap會從hash沖突節點開始,沿着連結清單尋找是否存在key值與待放入鍵值對的key相同的節點,如果有,則進行值替換操作,如果沒有,則在連結清單末端添加一個由待放入鍵值對建構的新節點。
![Java超市會員管理系統[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)